golang 六个比较排序算法实现
golang 比较排序算法实现
- 比较排序算法
- 交换排序
- 冒泡排序
- 快速排序
- 插入排序
- 简单插入排序
- 希尔排序
- 选择排序
- 简单选择排序
- 堆排序
比较排序算法
这里的比较排序算法重点并非比较算法之间优劣,这里的比较一词指的是接下来讲的六种排序算法皆为通过比较来决定元素次序。
| 比较排序 | 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|---|---|---|
| 交换排序 | |||||
| 冒泡排序 | O(n²) | O(n²) | O(n) | O(1) | 稳定 |
| 快速排序 | O(nlog₂n) | O(n²) | O(nlog₂n) | O(nlog₂n) | 不稳定 |
| 插入排序 | |||||
| 简单插入排序 | O(n²) | O(n²) | O(n) | O(1) | 稳定 |
| 希尔排序 | O(n3/2) | O(n²) | O(n) | O(1) | 不稳定 |
| 选择排序 | |||||
| 简单选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 |
| 堆排序 | O(nlog₂n) | O(nlog₂n) | O(nlog₂n) | O(1) | 不稳定 |
交换排序
所谓交换,就是根据序列中两个记录键值的比较结果来互换这两个记录在序列中的位置。
冒泡排序
冒泡算是最简单的交换排序了。具体步骤如下:
- 通过循环获取一个未排序元素
- 将该元素循环比较一个未排序元素,符合排序条件(更大或更小)则交换,直到元素全部对比过,此时该元素即为当前循环中的最大/最小元素。
- 重复步骤1-2直到所有元素均为排序后元素。
golang实现
func BubbleSort(array []int) {
//1.获取未排序元素array[i],此时[0,i]的元素则为排序后元素
for i := 0; i < len(array); i++ {
//2.循环和未排序的元素进行比较
for j := i + 1; j < len(array); j++ {
if array[i] > array[j] {
array[i], array[j] = array[j], array[i]
}
}
}
}
快速排序
快排是冒泡排序的改良版,也是极为常用的排序手段,golang标准库中的排序就使用了快排。具体步骤如下:
- 设定一个分界值x,通过该分界值将数组分成左右两部分(这里我们简单的把分界值设成第一个元素)。
- 从右边开始循环判断是否比分界值更小,如果更小则把该值填入当前 i 的位置并退出循环,否则继续循环
- 从左边开始循环判断是否比分界值更大,如果更大则把该值填入当前 j 的位置并退出循环,否则继续循环
- 重复2-3,直至i
- 此时分界下标则为i,将分界值填入i的位置
- 分别重复分界线的左边序列与右边序列1-5的过程,直至left
golang实现
//doPivot这个函数其实就是快排实现,不过作为排序接口不应该给调用方出现left,right.因此将doPivot隐藏。
func doPivot(array []int, left, right int) {
if left < right {//6.直到left
i := left
j := right
x := array[left]//1.设置分界值
for i < j {//4.左右交替赋值
for i < j {//2.从右边开始找出比分界值小的赋到左边
if array[j] < x {
array[i] = array[j]
i++
break
} else {
j--
}
}
for i < j {//3.从左边开始找出比分界值大的赋到右边
if array[i] > x {
array[j] = array[i]
j--
break
} else {
i++
}
}
}
array[i] = x//5.将分界值填入分界线位置
doPivot(array, left, i-1)//6.重复分界线的左边
doPivot(array, i+1, right)//6.重复分界线的右边
}
}
//对外接口,自身在调用快排实现
func QuickSort(array []int) {
left := 0
right := len(array) - 1
doPivot(array, left, right)
}
插入排序
所谓插入,指的就是将未排序元素插入有序的队列。
简单插入排序
简单插入排序的实现非常简单。具体步骤如下:
- 循环获取未排序的元素,该元素设为current(当前元素)
- 将当前元素循环对比排序后队列,符合排序条件(更大或更小)则将那个对比元素后移一位
- 不符合排序条件则停止循环并将值插入进队列
- 重复步骤1-3直到所有元素均为排序后元素。
golang实现
func InsertionSort(array []int) {
var preIndex, current int
//1.获取未排序元素array[i],此时[0,i]的元素则为排序后元素
for i := 1; i < len(array); i++ {
preIndex = i - 1
current = array[i]//将其设为当前元素
//2.循环和排序后元素比较
for preIndex >= 0 && current < array[preIndex] {
array[preIndex+1] = array[preIndex]//符合条件则元素往后移位
preIndex--
}
array[preIndex+1] = current//3.插入当前元素
}
}
希尔排序
希尔排序是简单插入排序算法的一种更高效的改进版本,主要是在简单插入排序的基础上增加了增量的概念,减少了其复制的次数,golang标准库中的排序就使用了希尔排序。具体步骤如下:
- 设置增量step(这里我们设置为长度/2,不管你自己设成什么规则最后一次增量都应该为1),循环增量序列
- 根据增量序列的每一次增量值为初始下标来获取循环队列(step,len(array))
- 设 前值下标 为 当前下标-增量值
- 循环对比当前值与前值,若符合排序条件(大于/小于)则更新对应前值下标与当前值下标并继续循环,否则跳出循环
- 将当前值插入队列对应位置
- 循环3-4直至增量<1结束
其实这里的步骤2-5就是一个简单插入循环,只不过这里加入了一个增量序列,从对比上一个值变成了对比上一个增量下标的值。
golang实现
func ShellSort(array []int) {
//1.循环增量序列,此处为增量初始值为len/2。
//6.直至step<1结束
for step := len(array) / 2; step >= 1; step = step / 2 {
//2.根据增量step循环队列
for i := step; i < len(array); i++ {
currentIndex := i//当前值下标
preIndex := currentIndex-step//3.前值下标
current := array[i]//当前值
//4.循环对比排序条件
for j-step >= 0 && current < array[preIndex] {
array[currentIndex] = array[preIndex]
currentIndex = currentIndex - step
preIndex = currentIndex-step
}
array[j] = current//5.将当前值插入队列对应位置
}
}
}
选择排序
所谓选择,就是将最符合排序条件(最大或最小)的元素一个个拿出来。
简单选择排序
简单选择排序应该是选择排序中最简单的实现。具体步骤如下:
- 循环获取未排序的元素,该元素的下标设为极值(最大或最小)
- 循环对比未排序元素,获得极值下标。
- 将极值下标对应元素与1中获取的原始极值的元素进行交换
- 重复步骤1-3直到所有元素均为排序后元素。
func SelectionSort(array []int) {
var minIndex int
//1.循环获取未排序元素,此时[0,i]的元素则为排序后元素
for i := 0; i < len(array)-1; i++ {
minIndex = i//设置最小值下标
//2.循环对比未排序元素
for j := i + 1; j < len(array); j++ {
if array[j] < array[minIndex] {
minIndex = j//更新最小值下标
}
}
//3.交换
array[i], array[minIndex] = array[minIndex], array[i]
}
}
堆排序
推排序指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点,它同时属于选择排序的一种(将最大堆节点或最小堆节点选择出来),golang标准库中的排序就使用了堆排序。具体步骤如下:
- 在顶部构建最大元素的堆
(1)从最后一个拥有子节点的父节点开始往上实现父元素更大堆属性 - 最大的元素放置末尾
(1)将未排序队列中的最大元素放置末尾
(2)使未排序队列实现父元素更大堆属性
实现父元素更大堆属性的具体步骤如下:
- 循环父节点下的所有子节点
- 判断父节点是否存在子节点,若不存在子节点退出循环
- 判断两个子节点哪个更大,选择大的那一个子节点
- 判断父节点是否大于子节点,若大于则退出循环
- 互换父子节点
- 将子节点设为父节点重新循环
该实现其实就是golang标准库下排序中的堆排序实现,只不过由于在Sort中堆排序只是其排序逻辑中的一部分,因此具有一些其他与堆排序无关的属性,在此将其删除。
func siftDown(array []int, lo, hi int) {
rootIndex := lo
//1.循环对比是否有比父节点大的子节点,当父节点为叶子节点或比子节点大时退出循环
for {
childIndex := 2*rootIndex + 1
//2.如果子节点下标大于堆的最大长度,则不存在该子节点退出循环
if childIndex >= hi {
break
}
//3.如果子节点的下一个兄弟节点大于等于该子节点,则定位下一个子节点下标
if childIndex+1 < hi && array[childIndex] <= array[childIndex+1] {
childIndex++
}
//4.如果父节点大于子节点则退出循环
if array[rootIndex] > array[childIndex] {
break
}
//5.互换父子节点
array[rootIndex], array[childIndex] = array[childIndex], array[rootIndex]
rootIndex = childIndex //6.将子节点设为父节点
}
}
func HeapSort(array []int) {
lo := 0
hi := len(array)
// 1.构建大顶堆,从最后一个拥有子节点的父节点开始往上循环
for i := (hi - 1) / 2; i >= 0; i-- {
//在array[i,len)上实现堆属性
siftDown(array, i, hi)
}
// 2.循环将当前序列中最大的元素放置末尾
for i := hi - 1; i >= 0; i-- {
//将array[0]与array[i]互换,即将最大元素放置末尾
array[0], array[i] = array[i], array[0]
//在array[0,i)上实现堆属性,即找出最大元素
siftDown(array, lo, i)
}
}
仅看代码的情况下如果你对堆的数据结构不怎么了解或许你还是会比较懵,因此我就用图来举个例子,剩下的过程你自己试验一下看一遍流程立马就懂了。
现调用HeapSort函数并传入一个int切片
HeapSort([]int{5, 4, 6, 7, 0, 3, 4, 8, 2, 9})
此时切片[]int{5, 4, 6, 7, 0, 3, 4, 8, 2, 9}转换为堆的效果就是
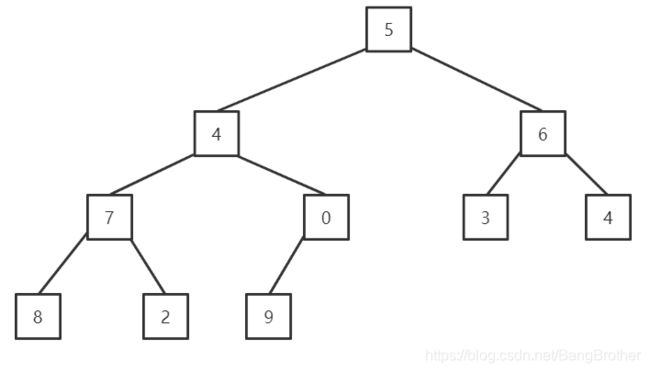
当程序运行至
// 1.构建大顶堆,从最后一个拥有子节点的父节点开始往上循环
for i := (hi - 1) / 2; i >= 0; i-- {
//在array[i,len)上实现堆属性
siftDown(array, i, hi)
}
第一次循环 i = (10-1)/2这个 i 就是最后一个具有子节点的父节点下标4,array[4]=0,看上图array[4]符合条件。
进入siftDown(array,4,10)函数
childIndex := 2*rootIndex + 1
这里的2*rootIndex + 1公式对应着父节点的第一个子节点下标此时为9,
if childIndex >= hi {
break
}
9小于堆的最大长度10,则存在该子节点,循环继续。
if childIndex+1 < hi && array[childIndex] <= array[childIndex+1] {
childIndex++
}
9+1并不小于最大长度10,不存在下一个兄弟节点,跳过if判断,循环继续。
if array[rootIndex] > array[childIndex] {
break
}
array[rootIndex], array[childIndex] = array[childIndex], array[rootIndex]
rootIndex = childIndex //6.将子节点设为父节点
4<9,父节点并不大于子节点,因此将其互换并将子节点设为父节点继续循环
childIndex := 2*rootIndex + 1
if childIndex >= hi {
break
}
下标9的子节点下标为19,大于堆的长度10,不存在该子节点退出循环。
array此时为[5, 4, 6, 7, 9, 3, 4, 8, 2, 0]
逼逼赖赖这么多不如放张图:

图实在是占地方了,后续循环我就不放图了,给你们个结果切片[]int自己转换,看一看就懂了。
初始值 [5 4 6 7 0 3 4 8 2 9]
调用siftDown(array, 4 , 10 )
交换后结果 [5 4 6 7 9 3 4 8 2 0] 继续循环
rootIndex: 9 没有子节点退出循环
调用siftDown(array, 3 , 10 )
交换后结果 [5 4 6 8 9 3 4 7 2 0] 继续循环
rootIndex: 7 没有子节点退出循环
调用siftDown(array, 2 , 10 )
child兄弟节点更大,选择该兄弟节点childIndex: 6
父节点比子节点大退出循环
调用siftDown(array, 1 , 10 )
child兄弟节点更大,选择该兄弟节点childIndex: 4
交换后结果 [5 9 6 8 4 3 4 7 2 0] 继续循环
父节点比子节点大退出循环
调用siftDown(array, 0 , 10 )
交换后结果 [9 5 6 8 4 3 4 7 2 0] 继续循环
交换后结果 [9 8 6 5 4 3 4 7 2 0] 继续循环
交换后结果 [9 8 6 7 4 3 4 5 2 0] 继续循环
rootIndex: 7 没有子节点退出循环
最后获取得的 [9 8 6 7 4 3 4 5 2 0] 就是大顶堆,父节点皆比子节点大。
排序我就不举例了,都是一个意思。如果还看不懂就把切片换成堆结构你就明白了。
结束
以后有机会可以把sort包拿出来说说。