生成式对抗网络GAN研究进展(三)——条件GAN
【前言】
本文首先介绍生成式模型,然后着重梳理生成式模型(Generative Models)中生成对抗网络(Generative Adversarial Network)的研究与发展。作者按照GAN主干论文、GAN应用性论文、GAN相关论文分类整理了45篇近两年的论文,着重梳理了主干论文之间的联系与区别,揭示生成式对抗网络的研究脉络。
本文涉及的论文有:
[1] Goodfellow Ian, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in Neural Information Processing Systems. 2014: 2672-2680.
[2] Mirza M, Osindero S. Conditional Generative Adversarial Nets[J]. Computer Science, 2014:2672-2680.
[3] Denton E L, Chintala S, Fergus R. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks[C]//Advances in neural information processing systems. 2015: 1486-1494.
3. 条件生成式对抗网络,Conditional Generative Adversarial Networks
3.1 CGAN的思想
生成式对抗网络GAN研究进展(二)——原始GAN 提出,与其他生成式模型相比,GAN这种竞争的方式不再要求一个假设的数据分布,即不需要formulate p(x),而是使用一种分布直接进行采样sampling,从而真正达到理论上可以完全逼近真实数据,这也是GAN最大的优势。然而,这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的 pixel的情形,基于简单 GAN 的方式就不太可控了。为了解决GAN太过自由这个问题,一个很自然的想法是给GAN加一些约束,于是便有了Conditional Generative Adversarial Nets(CGAN)【Mirza M, Osindero S. Conditional】。这项工作提出了一种带条件约束的GAN,在生成模型(D)和判别模型(G)的建模中均引入条件变量y(conditional variable y),使用额外信息y对模型增加条件,可以指导数据生成过程。这些条件变量y可以基于多种信息,例如类别标签,用于图像修复的部分数据[2],来自不同模态(modality)的数据。如果条件变量y是类别标签,可以看做CGAN 是把纯无监督的 GAN 变成有监督的模型的一种改进。这个简单直接的改进被证明非常有效,并广泛用于后续的相关工作中[3,4]。Mehdi Mirza et al. 的工作是在MNIST数据集上以类别标签为条件变量,生成指定类别的图像。作者还探索了CGAN在用于图像自动标注的多模态学习上的应用,在MIR Flickr25000数据集上,以图像特征为条件变量,生成该图像的tag的词向量。
3.2 Conditional Generative Adversarial Nets
3.2.1 Generative Adversarial Nets
Generative Adversarial Nets是由Goodfellow[5]提出的一种训练生成式模型的新方法,包含了两个“对抗”的模型:生成模型(G)用于捕捉数据分布,判别模型(D)用于估计一个样本来自与真实数据而非生成样本的概率。为了学习在真实数据集x上的生成分布Pg,生成模型G构建一个从先验分布 Pz (z)到数据空间的映射函数 G(z; θg )。 判别模型D的输入是真实图像或者生成图像,D(x; θd )输出一个标量,表示输入样本来自训练样本(而非生成样本)的概率。
模型G和D同时训练:固定判别模型D,调整G的参数使得 log(1 − D(G(z))的期望最小化;固定生成模型G,调整D的参数使得logD(X) + log(1 − D(G(z)))的期望最大化。这个优化过程可以归结为一个“二元极小极大博弈(minimax two-player game)”问题:
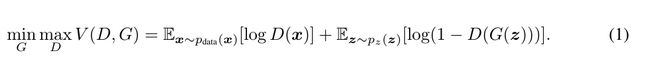
3.2.2 Conditional Adversarial Nets
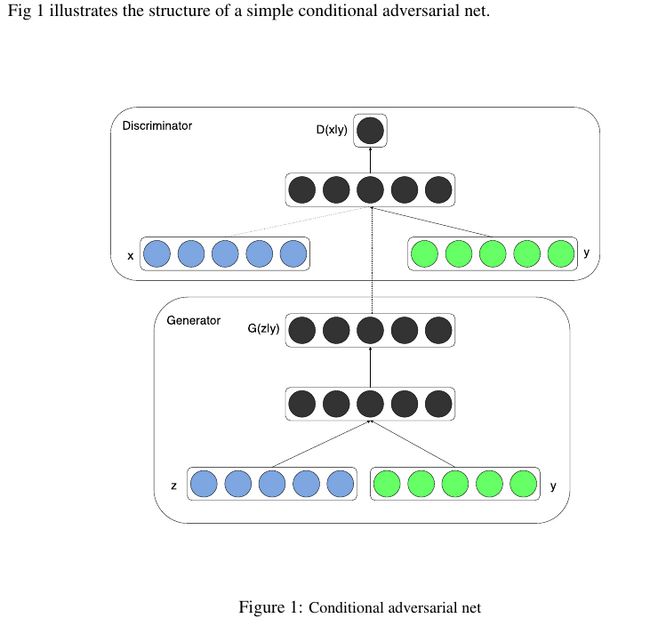
条件生成式对抗网络(CGAN)是对原始GAN的一个扩展,生成器和判别器都增加额外信息y为条件, y可以使任意信息,例如类别信息,或者其他模态的数据。如Figure 1所示,通过将额外信息y输送给判别模型和生成模型,作为输入层的一部分,从而实现条件GAN。在生成模型中,先验输入噪声p(z)和条件信息y联合组成了联合隐层表征。对抗训练框架在隐层表征的组成方式方面相当地灵活。类似地,条件GAN的目标函数是带有条件概率的二人极小极大值博弈(two-player minimax game ):

CGAN的网络结构
3.3 实验
3.3.1 MNIST数据集实验
在MNIST上以类别标签为条件(one-hot编码)训练条件GAN,可以根据标签条件信息,生成对应的数字。生成模型的输入是100维服从均匀分布的噪声向量,条件变量y是类别标签的one hot编码。噪声z和标签y分别映射到隐层(200和1000个单元),在映射到第二层前,联合所有单元。最终有一个sigmoid生成模型的输出(784维),即28*28的单通道图像。
判别模型的输入是784维的图像数据和条件变量y(类别标签的one hot编码),输出是该样本来自训练集的概率。

3.3.2 多模态学习用于图像自动标注
自动标注图像:automated tagging of images,使用多标签预测。使用条件GAN生成tag-vector在图像特征条件上的分布。数据集: MIR Flickr 25,000 dataset ,语言模型:训练一个skip-gram模型,带有一个200维的词向量。
【生成模型输入/输出】
噪声数据 100维=>500维度
图像特征4096维=>2000维
这些单元全都联合地映射到200维的线性层,
输出生成的词向量 (200维的词向量)
【判别模型的输入/输出】
输入:
500维词向量;
1200维的图像特征
???生成式和判别式的条件输入y,维度不一样???一个是4096维的图像特征,另一个是?维的?向量 _???
如图2所示,第一列是原始像,第二列是用户标注的tags ,第三列是生成模型G生成的tags。

3.4 Future works
1. 提出更复杂的方法,探索CGAN的细节和详细地分析它们的性能和特性。
2. 当前生成的每个tag是相互独立的,没有体现更丰富的信息。
3. 另一个遗留下的方向是构建一个联合训练的调度方法去学校language model
Reference
[1] Mirza M, Osindero S. Conditional Generative Adversarial Nets[J]. Computer Science, 2014:2672-2680.
[2] Goodfellow, I., Mirza, M., Courville, A., and Bengio, Y. (2013a). Multi-prediction deep boltzmann machines. In Advances in Neural Information Processing Systems, pages 548–556.
[3] Denton E L, Chintala S, Fergus R. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks[C]//Advances in neural information processing systems. 2015: 1486-1494.
[4] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks[J]. arXiv preprint arXiv:1511.06434, 2015.
[5] Goodfellow Ian, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in Neural Information Processing Systems. 2014: 2672-2680.