nodejs初步学习
什么是nodejs?
- Node.js 就是运行在服务端的 JavaScript。
- Node.js 是一个基于Chrome JavaScript 运行时建立的一个平台。
- Node.js是一个事件驱动I/O服务端JavaScript环境,基于Google的V8引擎,V8引擎执行Javascript的速度非常快,性能非常好。
nodejs的特性?
单线程
我们都知道Node.js的runtime是v8,v8在设计之初是Chrome使用在浏览器对JavaScript语言的解析运行引擎,其最大的特点是单线程,而在Node.js对v8的沿用也是针对这一非常重要的特点。什么是单线程?简单来说就是一个进程中只有一个线程,程序顺序执行,前面执行完成才会执行后面的程序。来看个Node.js对http服务的模型:
Node.js的单线程指的是主线程是“单线程”,由主要线程去按照编码顺序一步步执行程序代码,假如遇到同步代码阻塞,主线程被占用,后续的程序代码执行就会被卡住。实践一个测试代码
var http = require('http');
function sleep(time) {
var _exit = Date.now() + time * 1000;
while( Date.now() < _exit ) {}
return ;
}
var server = http.createServer(function(req, res){
sleep(10);
res.end('server sleep 10s');
});
server.listen(8080);下面为代码块的堆栈图:
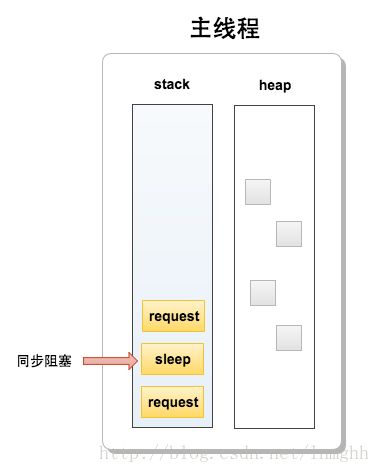
JavaScript是解析性语言,代码按照编码顺序一行一行被压进stack里面执行,执行完成后移除然后继续压下一行代码块进去执行。上面代码块的堆栈图,当主线程接受了request后,程序被压进同步执行的sleep执行块(我们假设这里就是程序的业务处理),如果在这10s内有第二个request进来就会被压进stack里面等待10s执行完成后再进一步处理下一个请求,后面的请求都会被挂起等待前面的同步执行完成后再执行,所以这也说明Node.js单线程的执行模型,因为这样的特性,我们的页面不能有耗时很长的同步处理程序阻塞了程序的后续执行,而对于耗时过长的程序应该采用异步执行,这里也就是Node.js的第二个特性,异步。
异步
我们平时都会说Node.js是异步,但是所说的异步具体指的是什么异步?更进一步的说应该是主线程的异步处理函数队列+多线程异步I/O。
主线程的异步处理函数队列
首先,所谓的主线程的异步处理函数队列指的是主线程的主要执行空间除了stack以及heap外,还有callback queue(回调函数队列),而callback queue是存放了异步处理的回调函数,在一个执行块里面,当里面的同步代码执行完成后,会从callback queue里面取出回调函数一个个执行,我们最常见的异步处理函数就是setTimeout,一个简单的例子来讲述:
function sleep(time) {
var _exit = Date.now() + time * 1000;
while( Date.now() < _exit ) {}
return ;
}
function main(){
setTimeout(function(){
console.log('setTimeout run');
},0);
sleep(5);
console.log('after sleep');
}
main();
/** 执行输出
after sleep
setTimeout run
**/下面是代码块的主线程堆栈执行:
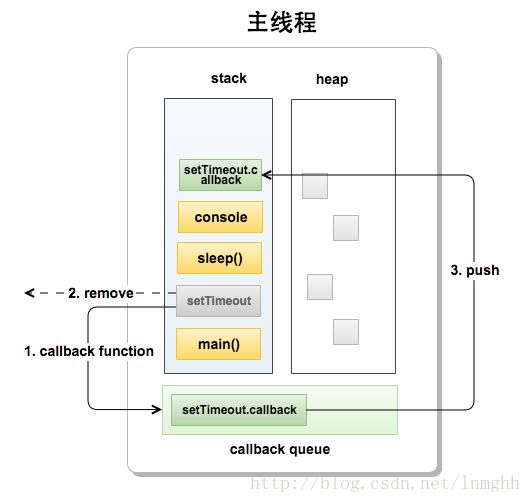
看上图,主线程将main函数压进stack里面一行行解析执行,首先遇到setTimeout方法,因为setTimeout是一个异步处理函数,这里会把setTimeout(callback,timeout),里面的callback函数移进callback queue里面,同时会把自己从主线程的stack里面移除,继续压进后面的执行代码来解析执行,这里继续压进sleep沉睡5s,接下来执行console,等到这里的同步代码执行完成后这个时候就会从callback queue(FIFO顺序)里面取回调函数一个个执行。(题外话:就算setTimeout里面的timeout设置了是0,都是要等待执行块里面的同步代码执行完成后再去执行callback queue里面的代码)这就是异步里面的其一:主线程异步函数处理队列。
多线程异步I/O
一看标题多线程异步I/O可能会有疑问,不是说Node.js是单线程的吗?其实这里并没有冲突,Node.js每个进程里面只有一个主线程来处理程序,所以,主线程是单线程的。而主线程之外调用的I/O处理是通过一个叫做线程池来管理和分配线程来处理I/O,所以对I/O的处理是多线程。而主线程和I/O线程池则通过上面刚刚讲述的主线程的异步处理函数队列来协作。除了上文所说的timers模块里面的setTimeout函数外,Node.js还对文件系统、网络都实现了异步化调用(题外话:系统底层的I/O异步化都是基于c++的异步框架libuv来实现,然后往上层提供JavaScript调用接口)此处之前理解有误,应该是Node.js只对文件系统以及DNS实现了多线程I/O封装,网络I/O还是采用单线程形式(可参考libuv设计概述原文:Important libuv uses a thread pool to make asynchronous file I/O operations possible, but network I/O is always performed in a single thread, each loop’s thread.感谢bd_bai指正)
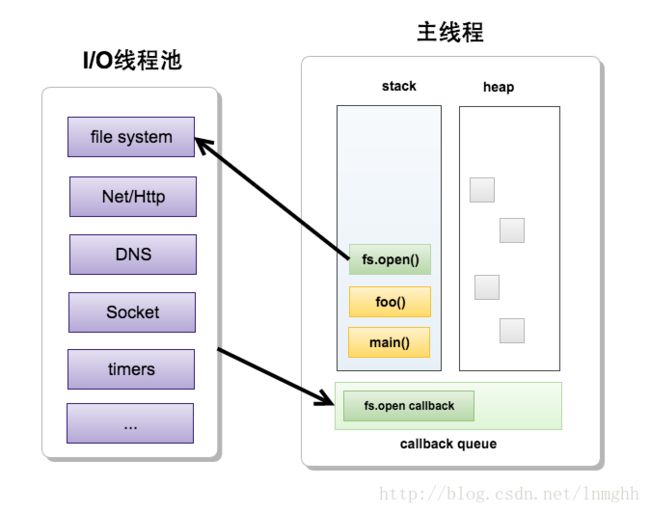
而Node.js的高性能也是得益于其将阻塞的I/O异步化,使得不影响主逻辑的执行。
事件驱动
文章至此,先简单总结一下Node.js的两个简单特性,每个Node.js进程只有一个主线程在执行程序代码,在执行的过程中Node.js将阻塞的I/O异步化,并将其回调函数插入callback queue里面,等待同步逻辑执行完成后再通过callback queue里面取出回调函数压进stack里面执行。好了,而事件驱动的作用就是取出回调函数。事件驱动又叫事件循环,是指主线程从主线程的异步处理函数队列里面不停循环的读取事件,驱动了所有的异步回调函数的执行。
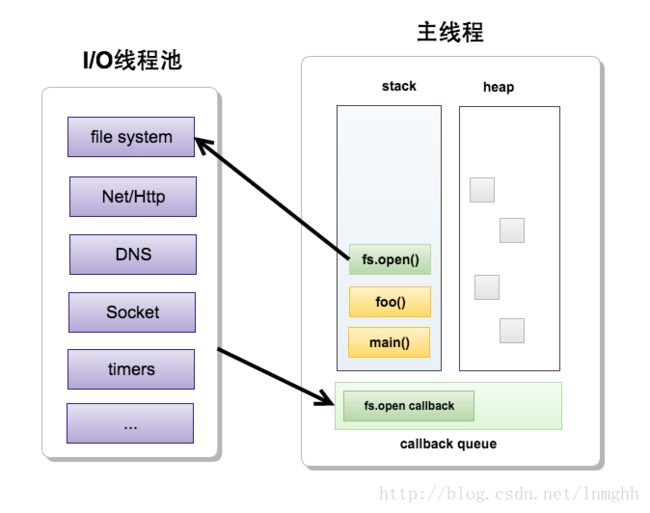
至此整个Node.js的异步化逻辑可以不断循环的跑起来了,以上则是我们日常所言的Node.js的三大特性以及其原理
为什么要使用nodejs?
总的来说,Node.js 适合以下场景:
- 实时性应用,比如在线多人协作工具,网页聊天应用等。
- 以 I/O 为主的高并发应用,比如为客户端提供 API,读取数据库。
- 流式应用,比如客户端经常上传文件。
- 前后端分离。
实际上前两者可以归结为一种,即客户端广泛使用长连接,虽然并发数较高,但其中大部分是空闲连接。
Node.js 也有它的局限性,它并不适合 CPU 密集型的任务,比如人工智能方面的计算,视频、图片的处理等
nodejs的优缺点?
Node.js优点:
1、采用事件驱动、异步编程,为网络服务而设计。其实Javascript的匿名函数和闭包特性非常适合事件驱动、异步编程。而且JavaScript也简单易学,很多前端设计人员可以很快上手做后端设计。
2、Node.js非阻塞模式的IO处理给Node.js带来在相对低系统资源耗用下的高性能与出众的负载能力,非常适合用作依赖其它IO资源的中间层服务。
3、Node.js轻量高效,可以认为是数据密集型分布式部署环境下的实时应用系统的完美解决方案。Node非常适合如下情况:在响应客户端之前,您预计可能有很高的流量,但所需的服务器端逻辑和处理不一定很多。
Node.js缺点:
1、可靠性低
2、单进程,单线程,只支持单核CPU,不能充分的利用多核CPU服务器。一旦这个进程崩掉,那么整个web服务就崩掉了。
不过以上缺点可以可以通过代码的健壮性来弥补。
目前Node.js的网络服务器有以下几种支持多进程的方式:
1 开启多个进程,每个进程绑定不同的端口,用反向代理服务器如 Nginx 做负载均衡,好处是我们可以借助强大的 Nginx 做一些过滤检查之类的操作,同时能够实现比较好的均衡策略,但坏处也是显而易见——我们引入了一个间接层。
2 多进程绑定在同一个端口侦听。在Node.js中,提供了进程间发送“文件句柄” 的功能,这个功能实在是太有用了(貌似是yahoo 的工程师提交的一个patch) ,不明真相的群众可以看这里: Unix socket magic
3 一个进程负责监听、接收连接,然后把接收到的连接平均发送到子进程中去处理。
在Node.js v0.5.10+ 中,内置了cluster 库,官方宣称直接支持多进程运行方式。Node.js 官方为了让API 接口傻瓜化,用了一些比较tricky的方法,代码也比较绕。这种多进程的方式,不可避免的要牵涉到进程通信、进程管理之类的东西。此外,有两个Node.js的module:multi-node 和 cluster ,采用的策略和以上介绍的类似,但使用这些module往往有一些缺点:
1 更新不及时
2 复杂庞大,往往绑定了很多其他的功能,用户往往被绑架#3 遇到问题难以解决