SpringData整合ElasticSearch
SpringData整合ElasticSearch
1 前言
很早很早以前就听说了ElasticSearch,知道了它对大量数据的强悍搜索功能,当时就想以后一定要用一下这个东西,把它加到我自己的项目中。兜兜转转终于到了使用的这天,虽说有点大材小用,但还是在我的博客项目中使用了它。
2 ElasticSearch与MYSQL类比
| ElasticSearch | MYSQL |
|---|---|
| 索引库(indices) | 数据库(databases) |
| 类型(type) | 表(table) |
| 文档(document) | 行(row) |
| 字段(field) | 列(column) |
3 使用Docker安装ElasticSearch
需要注意的是安装ElasticSearch时要注意自己springboot引入的springdata引入的ElasticSearch版本
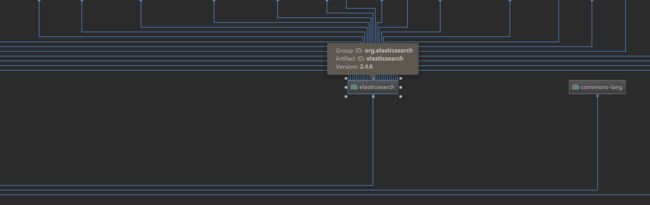
我的版本是2.4.6,所以我下载镜像时也是下载的相应的版本。
在Docker仓库查看对应版本的镜像,然后使用下面的命令下载
docker pull elasticsearch:2.4.6
下载完成后

然后启动镜像,指定运行内存最大与最小都为256m,后台运行,端口映射
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 --name ES01 5e9d896dc62c
访问9200端口,启动成功则会出现如下情景

4 创建SpringBoot项目整合
properties文件(cluster-name就是上面的cluster_name,一般默认是elasticsearch)
spring.data.elasticsearch.cluster-name=elasticsearch
spring.data.elasticsearch.cluster-nodes=118.25.236.51:9300
Image类
@Data
@Document(indexName = "blog",type = "image")
public class Image {
private int id;
private String url;
private int type;
@Field(type = FieldType.String,analyzer = "ik_max_word")
private String tag;
@Field(type = FieldType.String,analyzer = "ik_max_word")
private String description;
}
Spring Data通过注解来声明字段的映射属性,有下面的三个注解:
@Document作用在类,标记实体类为文档对象,一般有两个属性- indexName:对应索引库名称
- type:对应在索引库中的类型
- shards:分片数量,默认5
- replicas:副本数量,默认1
@Id作用在成员变量,标记一个字段作为id主键@Field作用在成员变量,标记为文档的字段,并指定字段映射属性:- type:字段类型,是枚举:FieldType,可以是text、long、short、date、integer、object等
- text:存储数据时候,会自动分词,并生成索引
- keyword:存储数据时候,不会分词建立索引
- Numerical:数值类型,分两类
- 基本数据类型:long、interger、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
- Date:日期类型
- elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
- index:是否索引,布尔类型,默认是true
- store:是否存储,布尔类型,默认是false
- analyzer:分词器名称,这里的
ik_max_word即使用ik分词器(关于IK分词器将在以后介绍)
- type:字段类型,是枚举:FieldType,可以是text、long、short、date、integer、object等
5 继承ElasticSearch的Repository接口完成基本的操作
ElasticsearchRepository接口
@NoRepositoryBean
public interface ElasticsearchRepository<T, ID extends Serializable> extends ElasticsearchCrudRepository<T, ID> {
<S extends T> S index(S var1);
Iterable<T> search(QueryBuilder var1);
Page<T> search(QueryBuilder var1, Pageable var2);
Page<T> search(SearchQuery var1);
Page<T> searchSimilar(T var1, String[] var2, Pageable var3);
void refresh();
Class<T> getEntityClass();
}
继承接口(同JpaRepository等接口相同,继承接口就已经有实现的操作数据的方法)
public interface ImageRepository extends ElasticsearchRepository<Image,Integer> {
}
5.1 添加对象
@Test
public void addImage(){
Image image = new Image();
image.setId(4);
image.setUrl("444");
image.setTag("tag");
image.setType(1);
image.setDescription("aaaaaaa");
imageRepository.save(image);
}
5.2 删除对象
@Test
public void deleteImage(){
imageRepository.delete(4);
}
5.3 更新对象
@Test
public void update(){
Image image = new Image();
image.setId(4);//注意id应该与要更改的数据的相同
image.setUrl("333");
image.setTag("tag1");
image.setType(1);
image.setDescription("aaaaaaa");
imageRepository.save(image);
}
5.4 查询对象
5.4.1 基本查询(通过ElasticsearchRepository提供的方法进行查询)
5.4.2 通过自己需求自定义方法
| Keyword | Sample | Elasticsearch Query String |
|---|---|---|
And |
findByNameAndPrice |
{"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Or |
findByNameOrPrice |
{"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Is |
findByName |
{"bool" : {"must" : {"field" : {"name" : "?"}}}} |
Not |
findByNameNot |
{"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
Between |
findByPriceBetween |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
LessThanEqual |
findByPriceLessThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
GreaterThanEqual |
findByPriceGreaterThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Before |
findByPriceBefore |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
After |
findByPriceAfter |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Like |
findByNameLike |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
StartingWith |
findByNameStartingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
EndingWith |
findByNameEndingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
Contains/Containing |
findByNameContaining |
{"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}} |
In |
findByNameIn(Collection |
{"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
NotIn |
findByNameNotIn(Collection |
{"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
Near |
findByStoreNear |
Not Supported Yet ! |
True |
findByAvailableTrue |
{"bool" : {"must" : {"field" : {"available" : true}}}} |
False |
findByAvailableFalse |
{"bool" : {"must" : {"field" : {"available" : false}}}} |
OrderBy |
findByAvailableTrueOrderByNameDesc |
{"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"available" : true}}}} |
5.4.3 通过构建Elasticsearch的查询语句来实现查询
- 重要查询
match查询
无论你在任何字段上进行的是全文搜索还是精确查询,match 查询是你可用的标准查询。
如果你在一个全文字段上使用 match 查询,在执行查询前,它将用正确的分析器去分析查询字符串:如果在一个精确值的字段上使用它, 例如数字、日期、布尔或者一个 not_analyzed 字符串字段,那么它将会精确匹配给定的值。(查询前可以分词,可以不分词,看类型)
@Test
public void query(){
String tag = "武器";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//查询tag域中存在"武器"的数据
queryBuilder.withQuery(QueryBuilders.matchQuery("tag", tag));
Page<Image> search = imageRepository.search(queryBuilder.build());
for (Image image : search) {
System.out.println(image);
}
}
term查询
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些 not_analyzed 的字符串,term 查询对于输入的文本不 分析 ,所以它将给定的值进行精确查询。
更多的组合语法请参考Elasticsearch查询的官方文档
@Test
public void query() {
String tag = "武器";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withQuery(QueryBuilders.termQuery("tag", tag));
Page<Image> search = imageRepository.search(queryBuilder.build());
for (Image image : search) {
System.out.println(image);
}
}
- 组合查询
可以用 bool 查询来实现组合查询。这种查询将多查询组合在一起,成为用户自己想要的布尔查询。它接收以下参数:
must
文档 必须 匹配这些条件才能被包含进来。
must_not
文档 必须不 匹配这些条件才能被包含进来。
should
如果满足这些语句中的任意语句,将增加 _score ,否则,无任何影响。它们主要用于修正每个文档的相关性得分。
filter
必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
public List<Image> combineQuery(String search) {
//组合查询BoolQueryBuilder
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//精确匹配tag,不分词
//should相当于or,下面语句的意思是,找到tag域 或 description域中存在search的文档
boolQueryBuilder.should(QueryBuilders.termQuery("tag", search))
//两种条件会出现不同结果,具体看后面分析
// .should(QueryBuilders.termQuery("description",search));
.should(QueryBuilders.matchQuery("description", search));
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
//根据id域升序排列查询结果
NativeSearchQuery searchQuery = nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort("id").order(SortOrder.ASC)).withQuery(boolQueryBuilder).build();
Page<Image> search1 = imageRepository.search(searchQuery);
List<Image> returnImages = new ArrayList<>();
for (Image image : search1) {
returnImages.add(image);
}
return returnImages;
}
前面已经讲过match与term的区别,现在直观的来看一下
description使用matchQuery
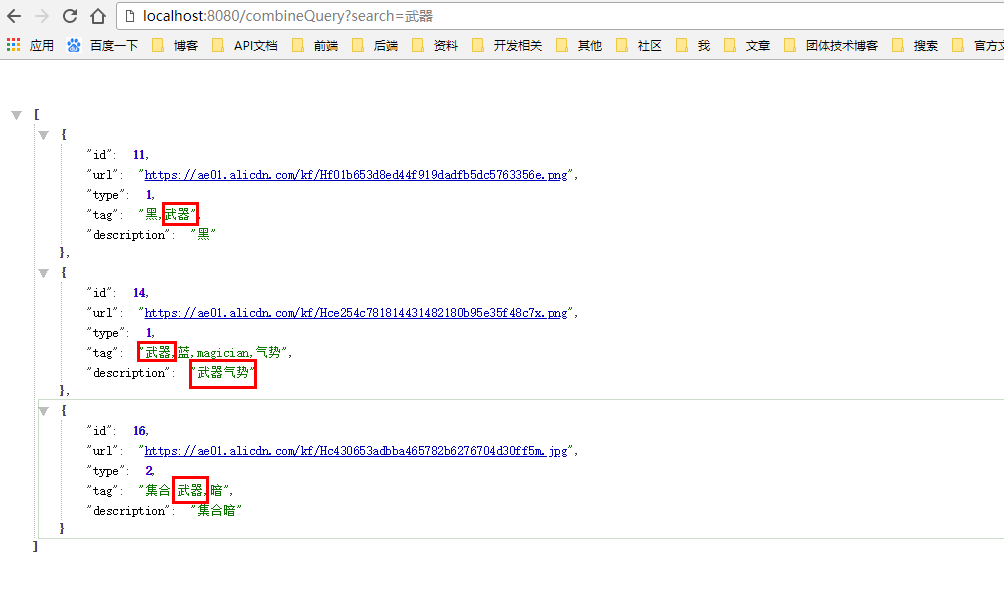
description使用matchQuery
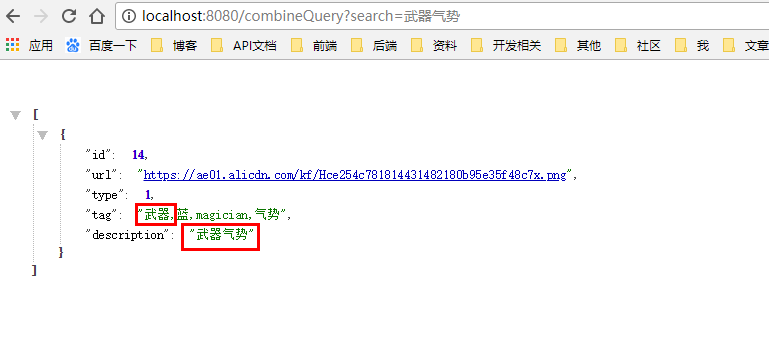
description使用term
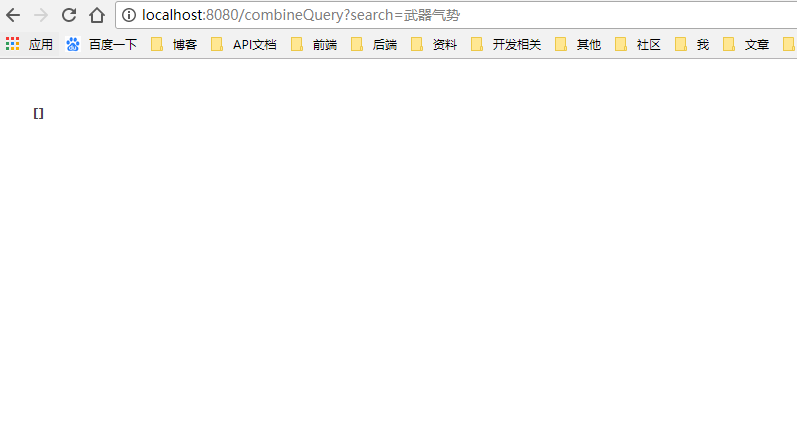
当使用term时,查询字段不会分词,直接是武器气势精确查询,但是索引中却不存在这个索引,真正的索引如下:
description的分词索引
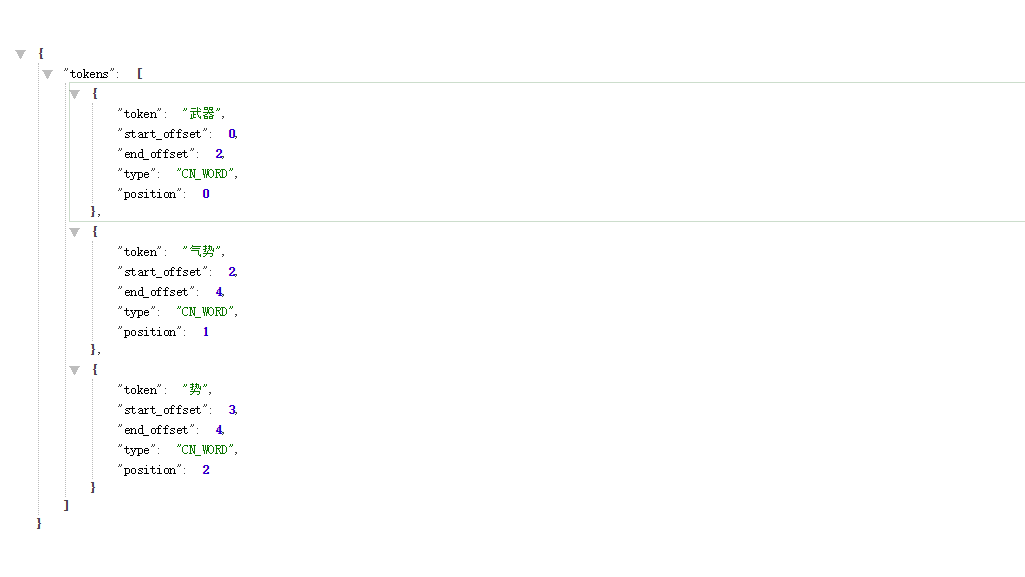
所以当使用term进行精确查询时,返回结果就为空。