Ubuntu16.04LTS安装及配置Hadoop
前言
这学期有一门云计算的课程,有接触到Hadoop,后来需要完成Hadoop的安装及配置,折腾了好久,决定以此记录下来。以供学习!课本附录简单介绍了在Windows上的安装及配置过程,但是推荐在Linux系统下完成,正好对Linux系统及一些命令比较感兴趣,趁着这个机会正好学习一波。以此记录之!
Hadoop简介
此处引用百度百科:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Hadoop在Ubuntu上的安装与配置
安装环境及版本说明
Ubuntu 16.04LTS 64位操作系统
Hadoop版本:2.7.3 [下载地址](https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/)
Jdk版本:1.8.0
MyEclipse版本:MyEclipse2017 CI 10
安装路径信息
hadoop安装路径:/usr/local/hadoop/hadoop-2.7.3
jdk路径:/usr/lib/jvm/java-8-oracle
MyEclipse路径:/opt/MyEclipse 2017
一、Java 环境安装
此处引用我朋友的CSDN上一篇关于java web环境配置的博客
- 添加ppa
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update- 安装oracle-java-installer
JDK8:
sudo apt-get install oracle-java8-installer
JDK7:
sudo apt-get install oracle-java7-installer
安装时会提示你同意Oracle的服务条款,选择ok,然后选择yes
这种方式安装后jdk路径为/usr/lib/jvm/java-8-oracle。
二、安装ssh server 实现免密码登录
Hadoop需要使用ssh进行通信,首先我们需要在我们的操作系统上安装ssh。在安装之前,我们需要查看系统是否已经安装并且启动了ssh。
#查看ssh安装包情况
dpkg -l | grep ssh
#查看是否启动ssh服务
ps -e | grep ssh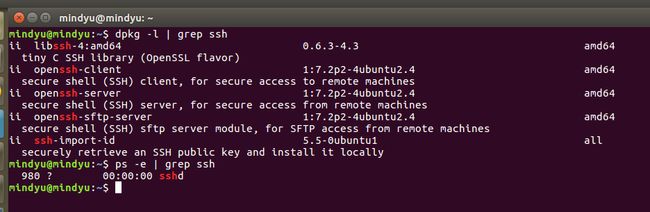
如果系统中没有ssh服务,需要先安装:
sudo apt-get install openssh-server
我安装时出现了connect to host localhost port 22: Connection refused问题,在CSDN博客上找到解决方法:
- 先用:sudo apt-get install -f 解决依赖问题
- 然后:sudo apt-get install openssh-server 就可以了
安装完成之后,启动服务:
sudo /etc/init.d/ssh start
三、安装Hadoop及配置
根据上述地址下载hadoop-2.7.3.tar.gz文件
解压缩下载的文件到指定文件夹
tar -zxvf hadoop-2.7.3 -C /usr/local/hadoop/
配置/usr/local/hadoop/hadoop-2.7.3/etc/hadoop/目录下三个文件
- core-site.xml配置如下:
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://localhost:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/mindyu/tmpvalue>
property>
configuration>- hdfs-site.xml配置如下:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>- hadoop-env.sh中进行对应的配置:
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.3
export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin在系统环境变量中写入hadoop路径:
vim /etc/environment然后在文件尾追加
:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin重启系统
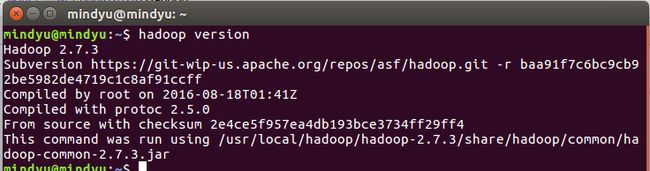
- 验证Hadoop单机模式安装完成
hadoop version
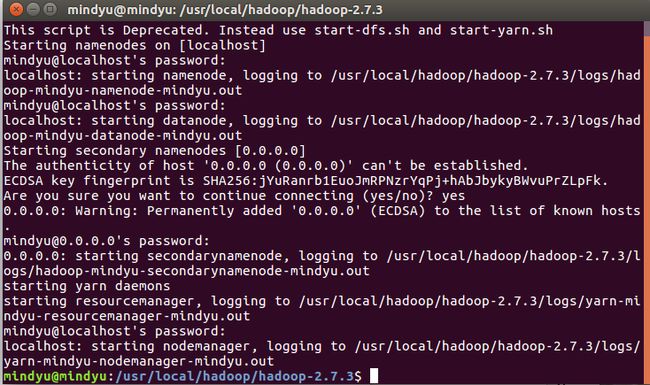
- 启动hdfs 使用伪分布模式,首先完成格式化
hadoop namenode -format - 启动hdfs
sbin/start-all.sh
- 显示进程
jps
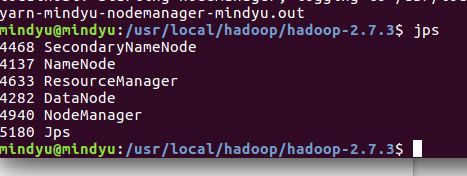
若显示以上内容即说明hdfs已经成功
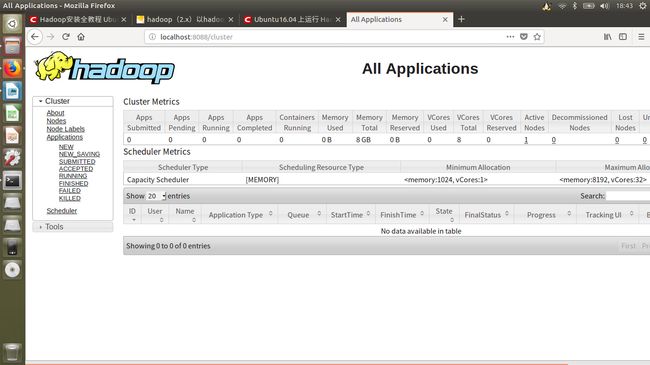
Hadoop资源管理GUI:
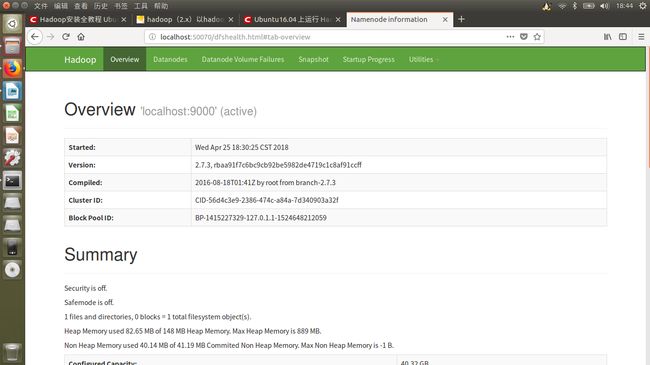
Hadoop节点管理GUI:
- 停止hdfs
sbin/stop-all.sh
Ubuntu16.04 上运行 Hadoop2.7.3 自带wordCount摸索记录
启动hadoop:
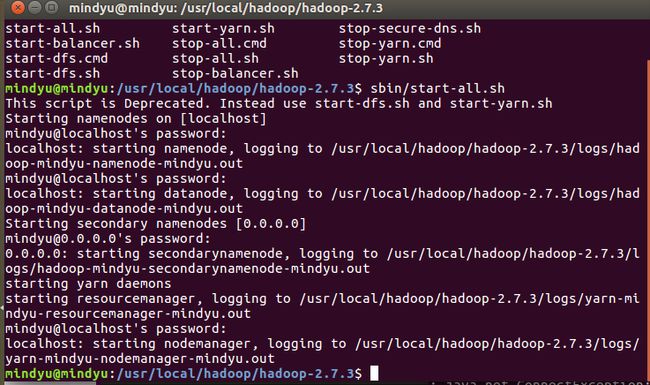
运行命令:ps -ef|grep hadoop查询是否有hadoop进程:
在hdfs下创建input文件夹。准备两个文件,比如abc.txt和def.txt 里面各写上一句话(用于统计)。然后导入到hdfs文件系统中的input文件夹下。
hadoop fs -put *.txt /input
执行:bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output
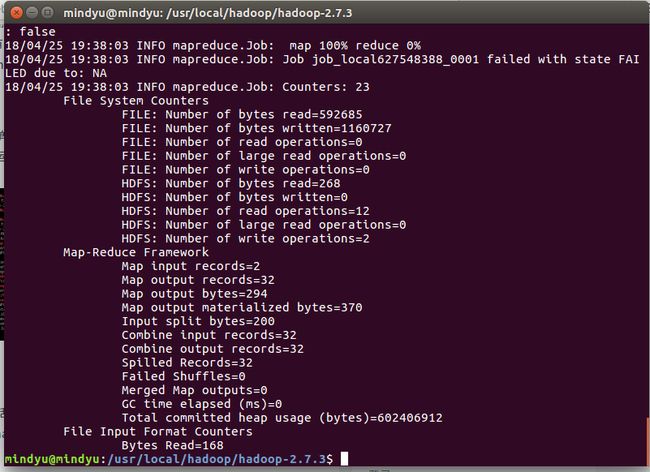
下次执行时需要将当前的output目录删除或者更换目录
hadoop fs -rmr /output查看hdfs下output中的文件:

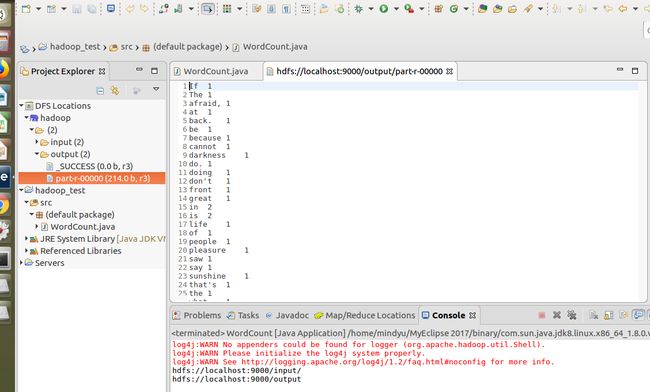
查看结果:hadoop fs -cat /output/part-r-00000

myeclipse下搭建hadoop2.7.3开发环境
- 下载对应版本的myeclipse-hadoo-plugins插件
- 把解压后的插件(jar文件)放到myeclipse安装目录下的plugins文件夹下
- 重启MyEclipse
- window->preferences中会出现Hadoop Map/Reduce选项,选中并设置hadoop 的安装路径
- 在show view中把map/reduce显示到工具栏
打开 Hadoop Location配置窗口: 配置Map/Reduce Master和DFS Mastrer,Host和Port配置成与core-site.xml的一致
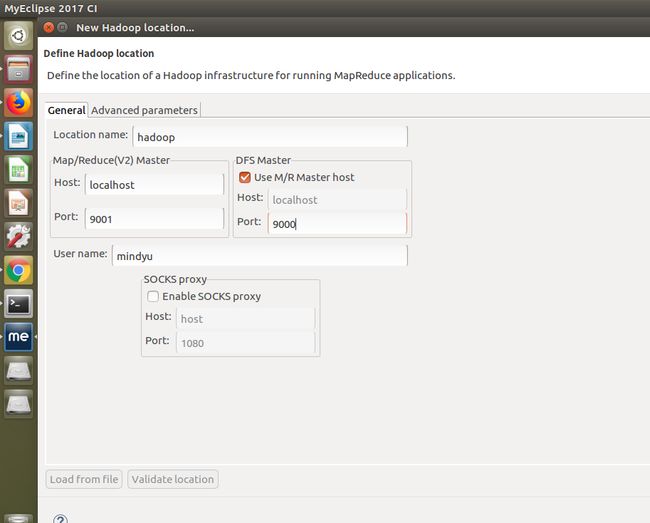
- 配置完成之后。(如果出现错误,检查hadoop集群是否启动成功,看日志是否有错误,先把错误调完,正确启动集群后再干别的)
- 新建测试项目
File—>Project,选择Map/Reduce Project,输入项目名称等。 将Hadoop源码(源码可在上文hadoop下载链接中下载)中的WordCount类拷贝到项目中 设置Run Configration的arguments参数:
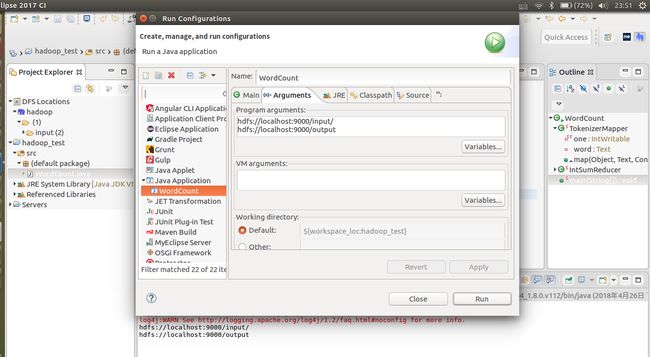
执行WordCount类,查看结果。结果如下: