R语言文本挖掘tm包详解(附代码实现)
- 文本挖掘相关介绍
- 1什么是文本挖掘
- 2NLP
- 3 分词
- 4 OCR
- 5 常用算法
- 6 文本挖掘处理流程
- 7 相应R包简介
- 8 文本处理
- 词干化stemming snowball包
- 记号化Tokenization RWeka包
- 中文分词 Rwordseg包
- 9 tm包常用操作介绍
- tm包具体操作
-
- 建立语料库
- 导出语料库
- 语料库检索和查看
- 元数据查看与管理
- 词条-文档关系矩阵
- 1创建词条-文档关系矩阵
- 2文档距离计算
- 文本聚类
- 层次聚类法
- Kmeans聚类
- K中心法聚类
- Knn算法
- 支持向量机SVM
-
文本挖掘相关介绍
1、什么是文本挖掘
文本挖掘是抽取有效、新颖、有用、可理解的、散布在文本文件中的有价值知识,并且利用这些知识更好地组织信息的过程。
在文本挖掘领域中,文本自动分类,判同,情感分析是文本挖掘比较常见的应用 。文本分类技术主要应用在百度新闻,谷歌新闻等新闻网站,对新闻内容进行自动分类,并且实现根据用户专业倾向的文档推荐;搜索引擎去重,论文抄袭判别系统等。情感分析技术主要应用在电商评论分析系统,政府和媒体舆情监测系统等。语意理解技术应用在机器翻译、聊天机器人等。
2、NLP
文本挖掘可以视为NLP(Natural language processing,自然语言处理)的一个子领域,目标是在大量非结构化文本中整理析取出有价值的内容。由于人类语言具有很高的复杂性,例如不同语言间语法不同,组成方式不同,还有语言种类的多样性,使得NLP是目前机器学习领域最困难的技术之一,里面的难点大部分成为各个应用领域(搜索引擎,情感识别,机器写作等等)的核心障碍,是实现高度智能机器人的关键技术。NLP大部分方法适用于不同的语种,也有部分只适合特定语种。
NLP通常包含两方面内容:词法、语法。词法的经典问题为分词、拼写检查、语音识别等;语法的经典问题有词类识别、词义消歧、结构分析等;语音识别领域经典问题有语言识别、语音指令、电话监听、语音生成等。
3、 分词
在英语等语言中,词与词之间存在着空格,因此在进行处理过程中不需要对其进行分词处理,但由于汉语等语言中词与词之间没有存在分隔,因此需要对其进行分词处理。分词处理能够避免不分词所引发的全表扫描,全表扫描效率低且内存消耗大。
4、 OCR
OCR : optional character recognition 印刷体识别和手写体识别、字形析取
应用:车牌识别、名片识别等
5、 常用算法
(算法需要一定的数学和统计学基础)
贝叶斯分类器
隐马尔科夫过程
有限状态自动机(FSA):用于文本判同等
6、 文本挖掘处理流程

7、 相应R包简介
语音与语音处理: emu包
词库数据库: wordnet包(英文库)
关键字提取和通用字符串操作: RKEA包;gsubfn包,tau包
自然语言处理: openNLP包,RWeka包;snowball包(分词);Rstem包;KoNLP包
文本挖掘: tm包(相对完整和综合);lsa包;topicmodels包;RTextTools包;textact包;zipfR包;……
8、 文本处理
1.词干化stemming snowball包
2.记号化Tokenization RWeka包
3.中文分词 Rwordseg包
Rwordseg包需下载安装,网址:
https://r-forge.r-project.org/R/?group_id=1054
在上面网址中下载Rwordseg 如果是64位的话就要下载.zip文件
中文分词比较有名的包非Rwordseg和jieba莫属,他们采用的算法大同小异,但有一个地方有所差别:Rwordseg在分词之前会去掉文本中所有的符号,这样就会造成原本分开的句子前后相连,本来是分开的两个字也许连在一起就是一个词了。
而jieba分词包不会去掉任何符号,而且返回的结果里面也会有符号。
9、 tm包常用操作介绍
1.DirSource:处理目录
2.VectorSource:由文档构成向量
3.DataframeSource:数据框,就像CSV 文件
4.Map操作:对文档内容应用转换函数
5.Xml转化为纯文本
6.去除多余空白
7.去除停用词
8.填充
9.Reduce操作:将多个转换函数的输出合并成一个
tm包具体操作
tm包版本问题:代码基于tm包0.6版本
关于版本差异问题,详见:https://cran.r-project.org/web/packages/tm/news.html
1.建立语料库
建立动态语料库 Corpus(x,……) Corpus(x, readerControl = list(reader=x$DefaultReader,language="en"),|…… )
建立静态语料库 Pcorpus(x,……) PCorpus(x, readerControl = list(reader=x$DefaultReader,language="en"),dbControl = list(dbName="",dbType="DB1"),…… )
x参数有如下三种选择:
DirSource
VectorSource
DataframeSource
(可以在readercontrol中的language中改变参数,建立各种语言的语料库,详见https://zh.wikipedia.org/zh/ISO_639-1%E4%BB%A3%E7%A0%81%E8%A1%A8)
另外,reader中可选参数如下,可以通过选择不同的参数读取不同形式的文件: 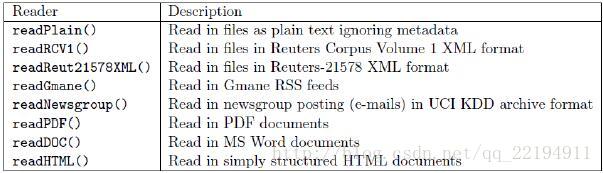
例:
#利用DirSource
ovid1<-Corpus(DirSource("d:/Program Files/R/R-3.3.3/library/tm/texts/txt"),
readerControl = list(language = "lat"))
inspect(ovid1)
#inspect可输出语料库的内容#利用VectorSource
docs <- c("This is a text.", "This another one.")
ovid2 <- Corpus(VectorSource(docs))
inspect(ovid2)#利用DataframeSource
data <- read.csv("D:/data/Finance Report 2012.csv")
ovid3 <- Corpus(DataframeSource(data),readerControl=list(language="zh"))
inspect(ovid3)2.导出语料库
方法:writeCorpus(x, path = ".", filenames = NULL)
例:
#将语料库保存为txt,并按序列命名语料库
writeCorpus(ovid1, path = "E:",filenames = paste(seq_along(ovid1), ".txt", sep = ""))3.语料库检索和查看
ovid[] 查找语料库的某篇文档 ovid[[]] 文档内容 c(ovid,ovid) 语料库拼接 lapply() 函数 length() 语料库文档数目 show()/print() 语料库信息 summary() 语料库信息(详细) inspect(ovid1[n:m]) 查找语料库第n至m个文档 meta(ovid[[n]], "id") 查看第n个语料库的id identical(ovid[[2]], ovid[["ovid_2.txt"]])查看第二个语料库名称是否为某个值 inspect(ovid[[2]]) 查看第二个文档的详细内容 lapply(ovid[1:2], as.character)分行查看内容
例1 按照文档的属性进行检索
#根据id和heading属性进行检索
reut21578 <- system.file("texts", "crude", package = "tm")
reuters <- Corpus(DirSource(reut21578), readerControl = list(reader = readReut21578XML))
#注意使用readReut21578XML时需要安装xml包,否则出错:Error in loadNamespace(name) : there is no package called ‘XML’
idx <- meta(reuters, "id") == '237' & meta(reuters, "heading") == 'INDONESIA SEEN AT CROSSROADS OVER ECONOMIC CHANGE'
reuters[idx] #查看搜索结果
inspect(reuters[idx][[1]])例2 全文检索
#检索文中含有某个单词的文档
data("crude")
tm_filter(crude, FUN = function(x) any(grep("co[m]?pany", content(x))))tm_filter也可以换作tm_index,区别在于tm_filter返回结果为语料库形式而tm_index返回结果则为true/false。
例3 语料库转换
#大小写转换
lapply(ovid,toupper)
inspect(tm_map(ovid,toupper))4.元数据查看与管理
元数据(core data)用于标记语料库的附件信息,它具有两个级别:一个为语料库元数据,一个为文档元数据。Simple Dublin Core是一种带有以下15种特定的数据元素的元数据。元数据只记录语料库或文档的信息,与文档相互独立,互不影响。
–标题(Title)
–创建者(Creator)
–主题(Subject)
–描述(Description)
–发行者(Publisher)
–资助者(Contributor)
–日期(Date)
–类型(Type)
–格式(Format)
–标识符(Identifier)
–来源(Source)
–语言(Language)
–关系(Relation)
–范围(Coverage)
–权限(Rights)
对core data或者Simple Dublin Core查看和管理方法如下: meta(crude[[1]])查看语料库元数据信息 meta(crude)查看语料库元数据的格式
例
#修改语料库元数据的值
DublinCore(crude[[1]], "Creator") <- "Ano Nymous"
#查看语料库元数据信息
meta(crude[[1]])
#查看语料库元数据的格式
meta(crude)
#增加语料库级别的元数据信息
meta(crude, tag = "test", type = "corpus") <- "test meta"
meta(crude, type = "corpus")
meta(crude, "foo") <- letters[1:20]5.词条-文档关系矩阵
1、创建词条-文档关系矩阵
为了后续建模的需要,一般需要对语料库创立词条-文档关系矩阵,创建词条-文档关系矩阵所用到的函数为: TermDocumentMatrix(x, control = list()) DocumentTermMatrix(x, control = list())
它们创建的矩阵互为转置矩阵。 control = list()中的可选参数有:removePunctuation,stopwords,weighting,stemming等,其中weighting可以计算词条权重,有 weightTf, weightTfIdf, weightBin, 和weightSMART4种。
#创建词条-文本矩阵
tdm <- TermDocumentMatrix(crude,
control = list(removePunctuation = TRUE,
stopwords = TRUE))
dtm <- DocumentTermMatrix(crude,
control = list(weighting =function(x) weightTfIdf(x, normalize =FALSE),
stopwords = TRUE))
dtm2 <- DocumentTermMatrix(crude,
control = list(weighting =weightTf,
stopwords = TRUE))
#查看词条-文本矩阵
inspect(tdm[202:205, 1:5])
inspect(tdm[c("price", "texas"), c("127", "144", "191", "194")])
inspect(dtm[1:5, 273:276])
inspect(dtm2[1:5,273:276])
#频数提取
findFreqTerms(dtm, 5)
#相关性提取
findAssocs(dtm, "opec", 0.8)
inspect(removeSparseTerms(dtm, 0.4))2、文档距离计算
使用方法:
dist(rbind(x, y), method = "binary" )
dist(rbind(x, y), method = "canberra" )
dist(rbind(x, y), method = "maximum")
dist(rbind(x, y), method = "manhattan") 有的时候,不同量级间的数据进行距离计算时,会受量级的影响,为了使到各个变量平等地发挥作用,我们需要对数据进行中心化和标准化的变换。
scale(x, center = TRUE, scale = TRUE)6.文本聚类
1.层次聚类法
算法主要思想
1. 开始时,每个样本各自作为一类
2. 规定某种度量作为样本之间的距离及类与类之间的距离,并计算之
3. 将距离最短的两个类合并为一个新类
4. 重复2-3,即不断合并最近的两个类,每次减少一个类,直至所有样本被合并为一类
代码实现
data(crude)
crudeDTM <- DocumentTermMatrix(crude, control = list(stopwords = TRUE))
#crudeDTM <- removeSparseTerms(crudeDTM, 0.8) #可以选择去除权重较小的项
crudeDTM.matrix <- as.matrix(crudeDTM)
d <- dist(crudeDTM.matrix,method="euclidean")
hclustRes <- hclust(d,method="complete")
hclustRes.type <- cutree(hclustRes,k=5) #按聚类结果分5个类别
length(hclustRes.type)
hclustRes.type #查看分类结果
plot(hclustRes, xlab = '') #画出聚类系谱图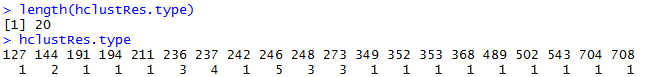
2.Kmeans聚类
算法主要思想
1. 选择K个点作为初始质心
2. 将每个点指派到最近的质心,形成K个簇(聚类)
3. 重新计算每个簇的质心
4. 重复2-3直至质心不发生变化
代码实现
k <- 5
kmeansRes <- kmeans(crudeDTM.matrix,k) #k是聚类数
mode(kmeansRes) #kmeansRes的内容
names(kmeansRes)
kmeansRes$cluster #聚类结果
kmeansRes$size #每个类别下有多少条数据
#sort(kmeansRes$cluster) #对分类情况进行排序
'''
"cluster"是一个整数向量,用于表示记录所属的聚类
"centers"是一个矩阵,表示每聚类中各个变量的中心点
"totss"表示所生成聚类的总体距离平方和
"withinss"表示各个聚类组内的距离平方和
"tot.withinss"表示聚类组内的距离平方和总量
"betweenss"表示聚类组间的聚类平方和总量
"size"表示每个聚类组中成员的数量
'''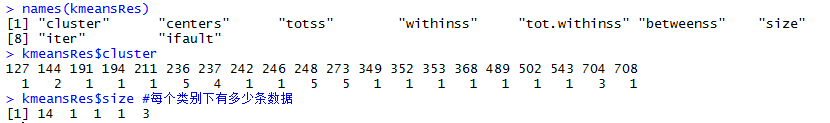
kmeans算法优缺点
- 有效率,而且不容易受初始值选择的影响
- 不能处理非球形的簇
- 不能处理不同尺寸,不同密度的簇
- 离群值可能有较大干扰(因此要先剔除)
3.K中心法聚类
算法主要思想
1. 随机选择k个点作为“中心点”
2. 计算剩余的点到这k个中心点的距离,每个点被分配到最近的中心点组成聚簇
3. 随机选择一个非中心点Or,用它代替某个现有的中心点Oj,计算这个代换的总代价S
4. 如果S<0,则用Or代替Oj,形成新的k个中心点集合
5. 重复2,直至中心点集合不发生变化
代码实现
library(cluster)
pa<-pam(d,2) #分两类
summary(pa)k中心法优缺点:
- K中心法的优点:对于“噪音较大和存在离群值的情况,K中心法更加健壮,不像Kmeans那样容易受到极端数据影响
- K中心法的缺点:执行代价更高
4.Knn算法
算法主要思想
1. 选取k个和待分类点距离最近的样本点
2. 看1中的样本点的分类情况,投票决定待分类点所属的类
代码实现
library("class")
library("kernlab")
data(spam)
train <- rbind(spam[1:1360, ], spam[1814:3905, ])
trainCl <- train[,"type"]
test <- rbind(spam[1361:1813, ], spam[3906:4601, ])
trueCl <- test[,"type"]
knnCl <- knn(train[,-58], test[,-58], trainCl)
(nnTable <- table("1-NN" = knnCl, "Reuters" = trueCl))
sum(diag(nnTable))/nrow(test) #查看分类正确率5.支持向量机SVM
算法主要思想
它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而 使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
算法实现
ksvmTrain <- ksvm(type ~ ., data = train)
svmCl <- predict(ksvmTrain, test[,-58])
(svmTable <- table("SVM" = svmCl, "Reuters" = trueCl))
sum(diag(svmTable))/nrow(test)