Python_美多商城(性能优化)_10
页面静态化
首页广告页面静态化
思考:
- 美多商城的首页访问频繁,而且查询数据量大,其中还有大量的循环处理。
问题:
- 用户访问首页会耗费服务器大量的资源,并且响应数据的效率会大大降低。
解决:
- 页面静态化
1. 页面静态化介绍
1.为什么要做页面静态化
- 减少数据库查询次数。
- 提升页面响应效率。
2.什么是页面静态化
- 将动态渲染生成的页面结果保存成html文件,放到静态文件服务器中。
- 用户直接去静态服务器,访问处理好的静态html文件。

3.页面静态化注意点
- 用户相关数据不能静态化:
- 用户名、购物车等不能静态化。
- 动态变化的数据不能静态化:
- 热销排行、新品推荐、分页排序数据等等。
- 不能静态化的数据处理:
- 可以在用户得到页面后,在页面中向后端发送Ajax请求获取相关数据。
- 直接使用模板渲染出来。
- 其他合理的处理方式等等。
2. 首页页面静态化实现
1.首页页面静态化实现步骤
- 查询首页相关数据
- 获取首页模板文件
- 渲染首页html字符串
- 将首页html字符串写入到指定目录,命名'index.html'
2.首页页面静态化实现

def generate_static_index_html():
"""
生成静态的主页html文件
"""
print('%s: generate_static_index_html' % time.ctime())
# 获取商品频道和分类
categories = get_categories()
# 广告内容
contents = {}
content_categories = ContentCategory.objects.all()
for cat in content_categories:
contents[cat.key] = cat.content_set.filter(status=True).order_by('sequence')
# 渲染模板
context = {
'categories': categories,
'contents': contents
}
# 获取首页模板文件
template = loader.get_template('index.html')
# 渲染首页html字符串
html_text = template.render(context)
# 将首页html字符串写入到指定目录,命名'index.html'
file_path = os.path.join(settings.STATICFILES_DIRS[0], 'index.html')
with open(file_path, 'w', encoding='utf-8') as f:
f.write(html_text)
3.首页页面静态化测试效果


提示:使用Python自带的
http.server模块来模拟静态服务器,提供静态首页的访问测试。
# 进入到static上级目录
$ cd ~/projects/meiduo_project/meiduo_mall/meiduo_mall
# 开启测试静态服务器
$ python -m http.server 8080 --bind 127.0.0.1![]()
3. 定时任务crontab静态化首页
重要提示:
- 对于首页的静态化,考虑到页面的数据可能由多名运营人员维护,并且经常变动,所以将其做成定时任务,即定时执行静态化。
- 在Django执行定时任务,可以通过
django-crontab扩展来实现。
1.安装 django-crontab
$ pip install django-crontab
2.注册 django-crontab 应用
INSTALLED_APPS = [
'django_crontab', # 定时任务
]
3.设置定时任务
定时时间基本格式 :
* * * * *
分 时 日 月 周 命令
M: 分钟(0-59)。每分钟用 * 或者 */1 表示
H:小时(0-23)。(0表示0点)
D:天(1-31)。
m: 月(1-12)。
d: 一星期内的天(0~6,0为星期天)。
定时任务分为三部分定义:
- 任务时间
- 任务方法
- 任务日志
CRONJOBS = [
# 每1分钟生成一次首页静态文件
('*/1 * * * *', 'contents.crons.generate_static_index_html', '>> ' + os.path.join(os.path.dirname(BASE_DIR), 'logs/crontab.log'))
]
解决 crontab 中文问题
- 在定时任务中,如果出现非英文字符,会出现字符异常错误
CRONTAB_COMMAND_PREFIX = 'LANG_ALL=zh_cn.UTF-8'
4.管理定时任务
# 添加定时任务到系统中
$ python manage.py crontab add
# 显示已激活的定时任务
$ python manage.py crontab show
# 移除定时任务
$ python manage.py crontab remove
商品详情页面静态化
提示:
- 商品详情页查询数据量大,而且是用户频繁访问的页面。
- 类似首页广告,为了减少数据库查询次数,提升页面响应效率,我们也要对详情页进行静态化处理。
静态化说明:
- 首页广告的数据变化非常的频繁,所以我们最终使用了
定时任务进行静态化。- 详情页的数据变化的频率没有首页广告那么频繁,而且是当SKU信息有改变时才要更新的,所以我们采用新的静态化方案。
- 方案一:通过Python脚本手动一次性批量生成所有商品静态详情页。
- 方案二:后台运营人员修改了SKU信息时,异步的静态化对应的商品详情页面。
- 我们在这里先使用方案一来静态详情页。当有运营人员参与时才会补充方案二。
注意:
- 用户数据和购物车数据不能静态化。
- 热销排行和商品评价不能静态化。
1. 定义批量静态化详情页脚本文件
1.准备脚本目录和Python脚本文件
2.指定Python脚本解析器
#!/usr/bin/env python
3.添加Python脚本导包路径
#!/usr/bin/env python
import sys
sys.path.insert(0, '../')
4.设置Python脚本Django环境
#!/usr/bin/env python
import sys
sys.path.insert(0, '../')
import os
if not os.getenv('DJANGO_SETTINGS_MODULE'):
os.environ['DJANGO_SETTINGS_MODULE'] = 'meiduo_mall.settings.dev'
import django
django.setup()
5.编写静态化详情页Python脚本代码
#!/usr/bin/env python
import sys
sys.path.insert(0, '../')
import os
if not os.getenv('DJANGO_SETTINGS_MODULE'):
os.environ['DJANGO_SETTINGS_MODULE'] = 'meiduo_mall.settings.dev'
import django
django.setup()
from django.template import loader
from django.conf import settings
from goods import models
from contents.utils import get_categories
from goods.utils import get_breadcrumb
def generate_static_sku_detail_html(sku_id):
"""
生成静态商品详情页面
:param sku_id: 商品sku id
"""
# 获取当前sku的信息
sku = models.SKU.objects.get(id=sku_id)
# 查询商品频道分类
categories = get_categories()
# 查询面包屑导航
breadcrumb = get_breadcrumb(sku.category)
# 构建当前商品的规格键
sku_specs = sku.specs.order_by('spec_id')
sku_key = []
for spec in sku_specs:
sku_key.append(spec.option.id)
# 获取当前商品的所有SKU
skus = sku.spu.sku_set.all()
# 构建不同规格参数(选项)的sku字典
spec_sku_map = {}
for s in skus:
# 获取sku的规格参数
s_specs = s.specs.order_by('spec_id')
# 用于形成规格参数-sku字典的键
key = []
for spec in s_specs:
key.append(spec.option.id)
# 向规格参数-sku字典添加记录
spec_sku_map[tuple(key)] = s.id
# 获取当前商品的规格信息
goods_specs = sku.spu.specs.order_by('id')
# 若当前sku的规格信息不完整,则不再继续
if len(sku_key) < len(goods_specs):
return
for index, spec in enumerate(goods_specs):
# 复制当前sku的规格键
key = sku_key[:]
# 该规格的选项
spec_options = spec.options.all()
for option in spec_options:
# 在规格参数sku字典中查找符合当前规格的sku
key[index] = option.id
option.sku_id = spec_sku_map.get(tuple(key))
spec.spec_options = spec_options
# 上下文
context = {
'categories': categories,
'breadcrumb': breadcrumb,
'sku': sku,
'specs': goods_specs,
}
template = loader.get_template('detail.html')
html_text = template.render(context)
file_path = os.path.join(settings.STATICFILES_DIRS[0], 'detail/'+str(sku_id)+'.html')
with open(file_path, 'w') as f:
f.write(html_text)
if __name__ == '__main__':
skus = models.SKU.objects.all()
for sku in skus:
print(sku.id)
generate_static_sku_detail_html(sku.id)
2. 执行批量静态化详情页脚本文件
1.添加Python脚本文件可执行权限
$ chmod +x regenerate_detail_html.py

2.执行批量静态化详情页脚本文件
$ cd ~/projects/meiduo_project/meiduo_mall/scripts
$ ./regenerate_detail_html.py
提示:跟测试静态首页一样的,使用Python自带的http.server模块来模拟静态服务器,提供静态首页的访问测试。
# 进入到static上级目录
$ cd ~/projects/meiduo_project/meiduo_mall/meiduo_mall
# 开启测试静态服务器
$ python -m http.server 8080 --bind 127.0.0.1=================================================
MySQL读写分离
提示:
我们的项目中已经存在非常多的数据库表了,数据量也会逐渐增多,所以我们需要做一些数据库的安全和性能的优化。
对于数据库的优化,我们选择使用MySQL读写分离实现。涉及内容包括
主从同步和Django实现MySQL读写分离。
MySQL主从同步
1. 主从同步机制
1.主从同步介绍和优点
- 在多台数据服务器中,分为主服务器和从服务器。一台主服务器对应多台从服务器。
- 主服务器只负责写入数据,从服务器只负责同步主服务器的数据,并让外部程序读取数据。
- 主服务器写入数据后,即刻将写入数据的命令发送给从服务器,从而使得主从数据同步。
- 应用程序可以随机读取某一台从服务器的数据,这样就可以分摊读取数据的压力。
- 当从服务器不能工作时,整个系统将不受影响;当主服务器不能工作时,可以方便地从从服务器选举一台来当主服务器
- 使用主从同步的优点:
- 提高读写性能
- 因为主从同步之后,数据写入和读取是在不同的服务器上进行的,而且可以通过增加从服务器来提高数据库的读取性能。
- 提高数据安全
- 因为数据已复制到从服务器,可以在从服务器上备份而不破坏主服务器相应数据。
- 提高读写性能
2.主从同步机制
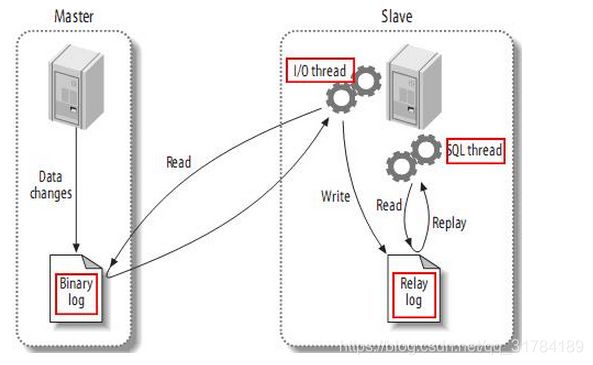
MySQL服务器之间的主从同步是基于
二进制日志机制,主服务器使用二进制日志来记录数据库的变动情况,从服务器通过读取和执行该日志文件来保持和主服务器的数据一致。
2. Docker安装运行MySQL从机
提示:
- 本项目中我们搭建
一主一从的主从同步。 - 主服务器:ubuntu操作系统中的MySQL。
- 从服务器:Docker容器中的MySQL。
1.获取MySQL镜像
- 主从同步尽量保证多台MySQL的版本相同或相近。
$ sudo docker image pull mysql:5.7.22
或
$ sudo docker load -i 文件路径/mysql_docker_5722.tar
2.指定MySQL从机配置文件
- 在使用Docker安装运行MySQL从机之前,需要准备好从机的配置文件。
- 为了快速准备从机的配置文件,我们直接把主机的配置文件拷贝到从机中。
$ cd ~
$ mkdir mysql_slave
$ cd mysql_slave
$ mkdir data
$ cp -r /etc/mysql/mysql.conf.d ./
3.修改MySQL从机配置文件
- 编辑
~/mysql_slave/mysql.conf.d/mysqld.cnf文件。- 由于主从机都在同一个电脑中,所以我们选择使用不同的端口号区分主从机,从机端口号是8306。
# 从机端口号
port = 8306
# 关闭日志
general_log = 0
# 从机唯一编号
server-id = 2
4.Docker安装运行MySQL从机
MYSQL_ROOT_PASSWORD:创建 root 用户的密码为 mysql。
$ sudo docker run --name mysql-slave -e MYSQL_ROOT_PASSWORD=mysql -d --network=host -v /home/python/mysql_slave/data:/var/lib/mysql -v /home/python/mysql_slave/mysql.conf.d:/etc/mysql/mysql.conf.d mysql:5.7.22
5.测试从机是否创建成功
$ mysql -uroot -pmysql -h 127.0.0.1 --port=8306
3. 主从同步实现
1.配置主机(ubuntu中MySQL)
- 配置文件如有修改,需要重启主机。
sudo service mysql restart
# 开启日志
general_log_file = /var/log/mysql/mysql.log
general_log = 1
# 主机唯一编号
server-id = 1
# 二进制日志文件
log_bin = /var/log/mysql/mysql-bin.log
2.从机备份主机原有数据
- 在做主从同步时,如果从机需要主机上原有数据,就要先复制一份到从机。
# 1. 收集主机原有数据
$ mysqldump -uroot -pmysql --all-databases --lock-all-tables > ~/master_db.sql
# 2. 从机复制主机原有数据
$ mysql -uroot -pmysql -h127.0.0.1 --port=8306 < ~/master_db.sql
3.主从同步实现
- 1.创建用于从服务器同步数据的帐号
# 登录到主机
$ mysql –uroot –pmysql
# 创建从机账号
$ GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' identified by 'slave';
# 刷新权限
$ FLUSH PRIVILEGES;
- 2.展示ubuntu中MySQL主机的二进制日志信息
$ SHOW MASTER STATUS;
- 3.Docker中MySQL从机连接ubuntu中MySQL主机
# 登录到从机
$ mysql -uroot -pmysql -h 127.0.0.1 --port=8306
# 从机连接到主机
$ change master to master_host='127.0.0.1', master_user='slave', master_password='slave',master_log_file='mysql-bin.000250', master_log_pos=990250;
# 开启从机服务
$ start slave;
# 展示从机服务状态
$ show slave status \G
测试:
在主机中新建一个数据库后,直接在从机查看是否存在。
Django实现MySQL读写分离
1. 增加slave数据库的配置
DATABASES = {
'default': { # 写(主机)
'ENGINE': 'django.db.backends.mysql', # 数据库引擎
'HOST': '192.168.103.158', # 数据库主机
'PORT': 3306, # 数据库端口
'USER': 'itcast', # 数据库用户名
'PASSWORD': '123456', # 数据库用户密码
'NAME': 'meiduo_mall' # 数据库名字
},
'slave': { # 读(从机)
'ENGINE': 'django.db.backends.mysql',
'HOST': '192.168.103.158',
'PORT': 8306,
'USER': 'root',
'PASSWORD': 'mysql',
'NAME': 'meiduo_mall'
}
}
2. 创建和配置数据库读写路由
1.创建数据库读写路由
- 在
meiduo_mall.utils.db_router.py中实现读写路由
class MasterSlaveDBRouter(object):
"""数据库读写路由"""
def db_for_read(self, model, **hints):
"""读"""
return "slave"
def db_for_write(self, model, **hints):
"""写"""
return "default"
def allow_relation(self, obj1, obj2, **hints):
"""是否运行关联操作"""
return True
2.配置数据库读写路由
DATABASE_ROUTERS = ['meiduo_mall.utils.db_router.MasterSlaveDBRouter']