Scrapy获取网易云音乐歌手全部歌曲(excel存取)
前言:
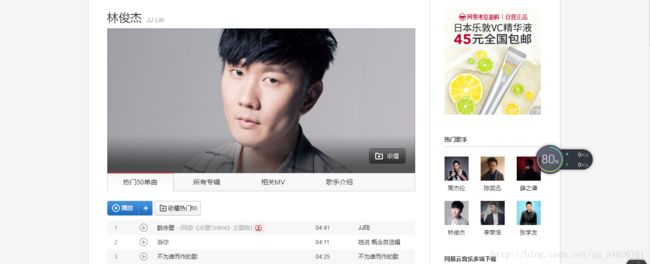
这个爬虫是为了之后爬取10W以上评论的歌曲做一下准备,这次以网易云音乐中的林俊杰为实验例子
爬虫思路:
爬取思路上,需要先通过歌手的所有专辑页面,获取到歌手的每个专辑的id,通过专辑的id转到专辑的界面,在专辑中获取歌曲id,转到歌曲界面后,我们就可以抓取歌曲上的信息了,不包括评论数,评论数是在另外的页面
爬虫过程:
首先展示一下爬虫的item部分
class WangyimusictestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
singer = scrapy.Field()#歌手
music = scrapy.Field()#歌曲
cd = scrapy.Field()在Item部分中,我的目标只是获取歌曲的歌名,歌手和歌曲所在的专辑
在主爬虫部分,我们首先需要解析网页
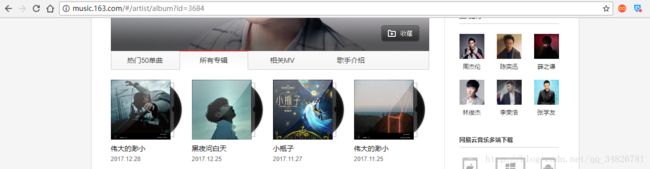
这个是林俊杰的界面,右键查看源代码发现并没有专辑内容
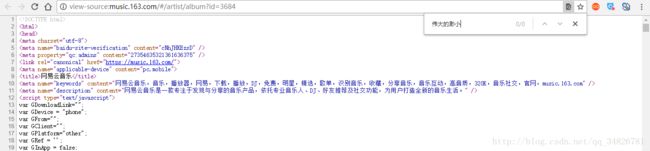
但是发现右键会有一个“查看框架源代码”的选项,发现在这里面可以查看到我们需要内容
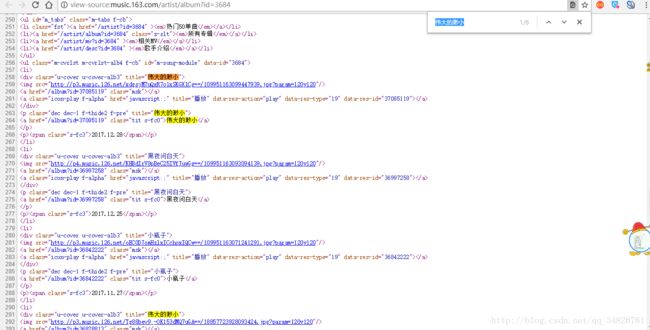
这里面正是存放着我们需要爬取的专辑,那么这个网页到底在哪里呢,我们可以F12查看审查元素,在Network中我们发现了我们需要的内容
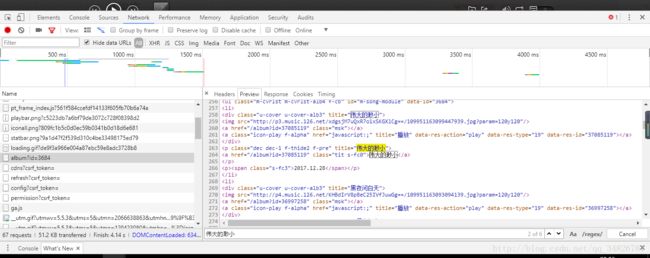
把鼠标放在左边这个网页上就会找到这个网页是什么,也就是我们在看框架代码时候的那个网页,也就是说需要的网页需要把#号去掉

这样我们就获得了真正需要爬取的网页,那么首先我们就需要获得歌手到底有多少页的专辑
def parse(self, response):
page = response.xpath('//a[@class="zpgi"]/text()').extract()
page_number = int(page[len(page)-1])
url = u'http://music.163.com/artist/album?id=3684&limit=12&offset='
if page_number == None :
page_number = int(1)
for i in range(page_number):
page_url = url + str(i*12)
yield scrapy.Request(url=page_url,callback=self.parse_cds) 在以上的代码中,我们通过xpath方法,获取到了page,表示一共有多少页,我们根据下一页专辑发现其中翻页的规律
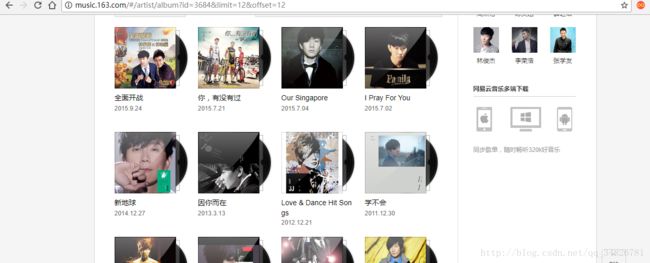
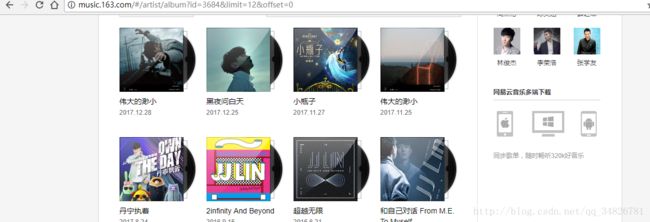
通过网站的规律,实现翻页方法
获取专辑页数之后我们就要去获取专辑id了
def parse_cds(self,response):
base_url = u'http://music.163.com'
cds = response.xpath('//ul[@class="m-cvrlst m-cvrlst-alb4 f-cb"]/li')
for i in range(len(cds)):
cd_message = cds.xpath('//li/p[@class="dec dec-1 f-thide2 f-pre"]/a/@href').extract()[i]
messages = base_url + cd_message
time.sleep(5)
yield scrapy.Request(url=messages,callback=self.parse_cd) 在这个代码中,我们用cds获取当前页面有多少个专辑,从而获取专辑的id
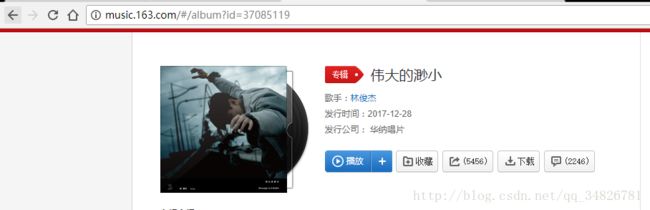

发现每个专辑的id就藏在href中,于是在第五行实现获取专辑id
获取到专辑id后我们就要获取专辑中的歌曲了
def parse_cd(self,response):
base_url = u'http://music.163.com'
songs = response.xpath('//ul[@class="f-hide"]/li')
for i in range(len(songs)):
song_id = songs.xpath('//li/a/@href').extract()[i]
song_url = base_url + song_id
yield scrapy.Request(url=song_url,callback=self.parse_song)方法与获取专辑id基本相同
获取到歌曲id后就可以进入到歌曲页面
def parse_song(self,response):
item = WangyimusictestItem()
item['music'] = response.xpath('//em[@class="f-ff2"]/text()').extract()[0]
item['singer'] = response.xpath('//p[@class="des s-fc4"]//a[@class="s-fc7"]/text()').extract()[0]
item['cd'] = response.xpath('//p[@class="des s-fc4"]//a[@class="s-fc7"]/text()').extract()[-1]
#time.sleep(2)
yield item以上是获取歌曲的专辑歌手以及唱片的代码
接下来是总的代码
import scrapy
import re
import time
from WangYiMusicTest.items import WangyimusictestItem
class MusicspiderSpider(scrapy.Spider):
name = 'MusicSpider'
start_urls = ['http://music.163.com/artist/album?id=3684']
def parse(self, response):
page = response.xpath('//a[@class="zpgi"]/text()').extract()
page_number = int(page[len(page)-1])
url = u'http://music.163.com/artist/album?id=3684&limit=12&offset='
if page_number == None :
page_number = int(1)
for i in range(page_number):
page_url = url + str(i*12)
yield scrapy.Request(url=page_url,callback=self.parse_cds)
def parse_cds(self,response):
base_url = u'http://music.163.com'
cds = response.xpath('//ul[@class="m-cvrlst m-cvrlst-alb4 f-cb"]/li')
for i in range(len(cds)):
cd_message = cds.xpath('//li/p[@class="dec dec-1 f-thide2 f-pre"]/a/@href').extract()[i]
messages = base_url + cd_message
time.sleep(5)
yield scrapy.Request(url=messages,callback=self.parse_cd)
def parse_cd(self,response):
base_url = u'http://music.163.com'
songs = response.xpath('//ul[@class="f-hide"]/li')
for i in range(len(songs)):
song_id = songs.xpath('//li/a/@href').extract()[i]
song_url = base_url + song_id
yield scrapy.Request(url=song_url,callback=self.parse_song)
def parse_song(self,response):
item = WangyimusictestItem()
item['music'] = response.xpath('//em[@class="f-ff2"]/text()').extract()[0]
item['singer'] = response.xpath('//p[@class="des s-fc4"]//a[@class="s-fc7"]/text()').extract()[0]
item['cd'] = response.xpath('//p[@class="des s-fc4"]//a[@class="s-fc7"]/text()').extract()[-1]
#time.sleep(2)
yield item存取部分
这次存取与以往不同,这次是存成excel的方式
import xlwt
from openpyxl import Workbook
class WangyimusictestPipeline(object):
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['歌手','歌曲名字','专辑名'])
def process_item(self, item, spider):
line = [item['singer'],item['music'],item['cd']]
self.ws.append(line)
self.wb.save(u'D:/python项目/Python_/爬虫项目实例/WangYiMusicTest/WangYiMusicTest/JJ.xlsx')
return item