垃圾短信分类
文章目录:
文章目录
- 一、如何导入数据?
- 1、导入数据集
- 2、数据预处理
- 3、导入短信数据
- 二、分词的相关知识
- 三、分隔训练集和测试集
- 四、提取文本特征
- 五、建立朴素贝叶斯分类器
- 六、数据预测
- 七、模型评估
- 八、完整代码
- 九、参考文章
一、如何导入数据?
学习两种数据导入方法:一种是导入scikit-learn内置的数据集。另外一种是导入本地的或者网络上的数据集。
1、导入数据集
使用load_*方法导入数据集,用于回归或者分类算法的实验,代码如下:
from sklearn.datasets import load_iris
iris = load_iris()
print(iris)
2、数据预处理
导入pandas模块以及numpy模块。
简单代码实现如下:
#导入库
import numpy as np
import pandas as pd
#第二步 导入数据集
dataset = pd.read_csv('Data.csv')
3、导入短信数据
需要对原始的短信数据(本地数据)进行处理,导入pandas、numpy、jieba模块。
#代码实现如下:
import pandas as pd
import numpy as np
import jieba
data = pd.read_csv(r"message.txt", encoding = 'utf-8', sep = '|', header = None)
如果想要详细了解numpy、pandas模块的具体用法可参考:
Numpy & Pandas 简介
二、分词的相关知识
在以上代码中,jieba模块适用于对短信分词,因为没有很多短信数据,所以只有几则短信数据。
0 1 2
0 1 0 商业秘密的秘密性那是维系其商业价值和垄断地位的前提条件之一
1 2 1 南口阿玛施新春第一批限量春装到店啦,春暖花开淑女裙、冰蓝色公主衫
2 3 0 带给我们大常州一场壮观的视觉盛宴
3 4 0 有原因不明的泌尿系统结石等
4 5 0 23年从盐城拉回来的麻麻的嫁妆
第一列为原始序号(运行时自己出来的序号)
第二列为短信的分类(0表示正常短信,1表示垃圾短信)
第三列就是短信的正文
数据读取后下一步需要进行文本域的分词,在使用jieba进行精准模式分词之前需要对一些非规范数据进行,如对电话号码xxx,特殊字符&“】等进行统一转换。对一些反复出现的无意义词汇,如‘的’等当用词进行筛选。
给出以下例子,简单了解jieba
import jieba
seg_list = jieba.cut("我觉得清华海星", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我觉得北大也还可以", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了麻省理工学院") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))

#对短信进行分词
data['分词短信'] = data[2].apply(lambda x:' '.join(jieba.cut(x)))
print(data.head)
而短信数据分词可得到:

三、分隔训练集和测试集
直接调用sklearn包,简直不要太方便,pip安装下载就好了,如果缺少包,用pip再安装下载就可以了。可以直接这么写
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=1/4, random_state=0)
简单解释一下代码,训练集(X_train),训练集标签(X_test),测试集(y_train),测试集标签(y_test)。test_size代表测试集的数据占总数据的1/4,相反训练集集则是占剩余的3/4。
注意 :
在环境:scikit-learn 0.18 , python3中 cross_validation 不可用
新的模块sklearn.model_selection,将以前的sklearn.cross_validation, sklearn.grid_search 和 sklearn.learning_curve模块组合到一起
详见: 官网
那么为什么要分割训练集和测试集呢 ?
在机器学习中,我们是依靠对学习器的泛化误差进行评估的方法来选择学习器。具体方法如下:我们需要从训练集数据中产出学习器,再用测试集来测试所得学习器对新样本的判别能力,以测试集上的测试误差作为泛化误差的近似,来选取学习器。
通常我们假设训练集、测试集都是从样本集中独立同分布采样得到,且测试集、训练集中的样本应该尽可能互斥(测试集中的样本尽量不在训练集中有出现、尽量不在训练过程中被使用)
测试样本为什么要尽可能不出现在训练集中呢?好比老师出了10道练习题给大家做,考试时候又用这10道练习题考试,这个考试成绩显然“过于乐观”,不能真实的反映同学的学习情况。我们是希望得到泛化性能强的模型,好比同学做完10道练习题能“举一反三”。
如果我们自己已经有了一个大的标注数据集,想要完成一个有监督模型的测试,那么通常使用均匀随机抽样的方式,将数据集划分为训练集、验证集、测试集,这三个集合不能有交集,常见的比例是8:1:1,当然比例是人为的。从这个角度来看,三个集合都是同分布的。
这样就很好理解,测试集与训练集是不能有交集的,要做到互相不干扰,就要把数据分割开来。
四、提取文本特征
从文本中提取特征,需要利用到scikit-learn中的CountVectorizer()方法和TfidfTransformer()方法。
CountVectorizer()用于将文本从标量转换为向量,TfidfTransformer()则将向量文本转换为tf-idf矩阵。
文本特征提取:
将文本数据转化成特征向量的过程,比较常用的文本特征表示法为词袋法
词袋法:
不考虑词语出现的顺序,每个出现过的词汇单独作为一列特征,这些不重复的特征词汇集合为词表 每一个文本都可以在很长的词表上统计出一个很多列的特征向量 ,如果每个文本都出现的词汇,一般被标记为 停用词 不计入特征向量
主要有两个api来实现 CountVectorizer 和 TfidfVectorizer
CountVectorize :只考虑词汇在文本中出现的频率
TfidfVectorizer :除了考量某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量 能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征 。相比之下,文本条目越多,Tfid的效果会越显著。
将文本数据转化为特征向量后,还要将其转化为tf-id矩阵,TfidfTransformer()方法就是为了这一步的。具体代码如下:
from sklearn.feature_extraction.text import TfidfTransformer,CountVectorizer#提取文本特征
vectorizer = CountVectorizer()
X_train_termcounts = vectorizer.fit_transform(train_X)
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_termcounts) #训练集文本提取特征
X_input_termcounts = vectorizer.transform(test_x) #测试集进行文本特征提取
X_input_tfidf = tfidf_transformer.transform(X_input_termcounts)
五、建立朴素贝叶斯分类器
朴素贝叶斯分类器是分类算法集合中基于贝叶斯理论的一种算法。它不是单一存在的,而是一个算法家族,在这个算法家族中它们都有共同的规则。例如每个被分类的特征对与其他的特征对都是相互独立的。
那么贝叶斯理论是什么?
贝叶斯理论指的是,根据一个已发生事件的概率,计算另一个事件的发生概率。贝叶斯理论从数学上的表示可以写成这样:
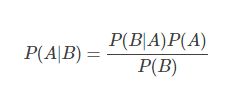
在这里A和B都是事件,P(B)不为0。用文字表述:后验概率=先验概率×相似度/标准化常量
- 基本上,只要我们给出了事件B为真,那么就能算出事件A发生的概率,事件B也被称为证据。
- P(A)是事件A的先验(先验概率,例如,在证据之前发生的概率)。证据是一个未知事件的一个属性值(在这里就是事件B)。
- P(A|B)是B的后验概率,例如在证据之后发生的概率。
而朴素贝叶斯分类器就是采用了“很不科学”的属性条件独立性假设。我们假设没有特征对是相互依赖的。温度热不热跟湿度没有任何关系,天气是否下雨也不影响是否刮风。因此,这就是假设特征相互独立。总的来说,这个假设认为每个属性取它的各个值的可能性是独立的,与其它属性的取值不相关。
更多基于数学算法的解释详情请看: 朴素贝叶斯分类器
如何使用 ?
示例来自官方文档
import numpy as np
X = np.random.randint(5, size=(6, 100)) ##返回随机整数值:范围[0,5) 大小6*100 6行100列
y = np.array([1, 2, 3, 4, 5, 6])
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB()
clf.fit(X, y)
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
print(clf.predict(X[2]))
[3]
而我们所需要写的代码为:
from sklearn.naive_bayes import GaussianNB,MultinomialNB
classifier = MultinomialNB().fit(X_train_tfidf, train_y) #建立朴素贝叶斯分类器并进行训练
在scikit-learn中,每一个模型都会有一个fit()方法用来模型训练。
六、数据预测
模型训练好之后,我们可以直接使用模型的predict()方法来测试与预测数据。
简单的找一个例子做一个示范:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.cross_validation import train_test_split
#用pandas加载数据.csv文件,然后用train_test_split分成训练集(75%)和测试集(25%):
X_train_raw, X_test_raw, y_train, y_test = train_test_split(df[1],df[0])
#我们建一个TfidfVectorizer实例来计算TF-IDF权重:
vectorizer=TfidfVectorizer()
X_train=vectorizer.fit_transform(X_train_raw)
X_test=vectorizer.transform(X_test_raw)
#LogisticRegression同样实现了fit()和predict()方法
classifier=LogisticRegression()
classifier.fit(X_train,y_train)
predictions=classifier.predict(X_test)这个项目应该写以下代码:
predicted_categories = classifier.predict(X_input_tfidf)
print(predicted_categories)那么 predicted_categories 就包含了数据预测的值,打印出来可看到(因为我本身数据很少,所以测试数据只有三则):
(0,0,0)
代表了三则短信内容预测值为正常。
七、模型评估
如何评价模型在现实中的表现呢?模型评估就可以评测这个模型是否够“A”,换句话说我已经让机器学习到怎么分辨是否是垃圾消息了,那我是不是应该检测一下他,是否能够真的完全分辨信息的有效性。
有了预测值,我们就要进行模型评估啦~
scikit-learn模块中内置了很多模型评估的方法,通常使用sklearn中的score方法计算结果的精度(正确预测比例),但对于分类问题,我们可以直接使用accuracy_score()方法,其返回一个数值,得分最高为1。
scikit-learn中的各种衡量指标
from sklearn.metrics import mean_squared_error #均方误差
from sklearn.metrics import mean_absolute_error #平方绝对误差
from sklearn.metrics import r2_score#R square调用
mean_squared_error(y_test,y_predict)
mean_absolute_error(y_test,y_predict)
r2_score(y_test,y_predict)
而我们的代码为:
#模型评估
from sklearn.metrics import accuracy_score
print(accuracy_score(test_y, predicted_categories))
得出结果(还是数据不多的原因,才会造成预测不够准确):
0.66666666
可以打印部分测试的短信数据以及预测的结果来看:

八、完整代码
import pandas as pd
import numpy as np
import jieba
data = pd.read_csv(r"message.txt", encoding = 'utf-8', sep = '-', header = None)
print(data.head())
#第二列为短信的分类,0表示正常短信,1表示垃圾短信,第三列就是短信的正文。
#我们只需要关注第二和第三列。
#查看一下这个短信数据集的形状
print(data.shape)
#对短信进行分词
data['分词短信'] = data[2].apply(lambda x:' '.join(jieba.cut(x)))
data.head()
#提取特征和目标数据
X = data['分词短信'].values
y = data[1].values
#分割训练集和测试集
from sklearn.model_selection import train_test_split #cross_validation 不可用 环境:scikit-learn 0.18 , python3
train_X,test_x,train_y,test_y = train_test_split(X, y, test_size = 0.2)
#提取文本特征
from sklearn.feature_extraction.text import TfidfTransformer,CountVectorizer
vectorizer = CountVectorizer()
X_train_termcounts = vectorizer.fit_transform(train_X)
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_termcounts)
#建立朴素贝叶斯分类器并进行训练
from sklearn.naive_bayes import GaussianNB,MultinomialNB
classifier = MultinomialNB().fit(X_train_tfidf, train_y)
#模型测试
X_input_termcounts = vectorizer.transform(test_x)
X_input_tfidf = tfidf_transformer.transform(X_input_termcounts)
predicted_categories = classifier.predict(X_input_tfidf)
print(predicted_categories)
#模型评估
from sklearn.metrics import accuracy_score
print(accuracy_score(test_y, predicted_categories))
#打印部分测试的短信数据以及预测的结果来看
category_map = {
0:'正常',
1:'垃圾'
}
#打印真实类型和预测类型
for sentence, category, real in zip(test_x[:10], predicted_categories[:10],test_y[:10]):
print('\n短信内容: ', sentence, '\nPredicted 分类: ', category_map[category], "真实值: ", category_map[real])九、参考文章
scikit-learn系列之如何导入数据
Scikit-Learn机器学习实践——垃圾短信识别
cross_validation等模块弃用
机器学习—— SVM分类垃圾短信
优雅地学会机器学习
从样本集合分得训练集、测试集的三种方法
训练集、验证集和测试集的意义
朴素贝叶斯分类器python中如何使用朴素贝叶斯算法