crwalspider全站爬取-拉勾网职位信息
前言
这次我们使用scrapy中的CrawlSpiders爬取拉勾网。CrawlSpiders是Spider的派生类,用于全站爬取。
开始之前,先介绍一个工具——cmder
cmder是一款Windows环境下非常简洁美观易用的cmd替代者,它支持了大部分的Linux命令。支持ssh连接linux,使用起来非常方便。
下载cmder后,将其路径添加到path环境变量中,然后就可以运行了。

用cmder查看scrapy中可用的spider模板,然后新建一个crawlspider。
crawlspider源码解析
crawlspider定义了一些规则(rule)来提供跟进link的方便的机制,可以说是为全站爬取而生。
rules:
一个包含一个(或多个)Rule对象的集合。 每个Rule对爬取网站的动作定义了特定表现。如果多个Rule匹配了相同的链接,则根据他们在本属性中被定义的顺序,第一个会被使用。
使用实例如下:
rules = (
Rule(LinkExtractor(allow=("zhaopin/.*",)), follow=True),
Rule(LinkExtractor(allow=("gongsi/j\d+.html",)), follow=True),
Rule(LinkExtractor(allow=r'jobs/\d+.html'), callback='parse_job', follow=True)
)
源码分析
CrawlSpider的源码不是很多,就直接在它的源码加上注释的方式进行分析:
class CrawlSpider(Spider):
rules = ()
def __init__(self, *a, **kw):
super(CrawlSpider, self).__init__(*a, **kw)
self._compile_rules()
#由于CrawlSpider继承自Spider,所以入口仍然是start_requests。在start_requests中发起start_url请求,然后交给回调函数parse处理(也就是以下步骤)
#1、首先调用parse()方法来处理start_urls中返回的response对象。
#2、parse()将这些response对象传递给了_parse_response()函数处理,并设置回调函数为parse_start_url()。
#3、设置了跟进标志位True,即follow=True。
#4、返回response。
def parse(self, response):
return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True)
#处理start_url中返回的response,需要重写。
def parse_start_url(self, response):
return []
def process_results(self, response, results):
return results
def _build_request(self, rule, link):
#构造Request对象,并将Rule规则中定义的回调函数作为这个Request对象的回调函数。这个‘_build_request’函数在下面调用。
r = Request(url=link.url, callback=self._response_downloaded)
r.meta.update(rule=rule, link_text=link.text)
return r
#从response中抽取符合任一用户定义'规则'的链接,并构造成Resquest对象返回。
def _requests_to_follow(self, response):
if not isinstance(response, HtmlResponse):
return
seen = set()
#抽取所有链接,只要通过任意一个'规则',即表示合法。
#遍历所有规则
for n, rule in enumerate(self._rules):
links = [lnk for lnk in rule.link_extractor.extract_links(response)
if lnk not in seen]
if links and rule.process_links:
links = rule.process_links(links)
#将链接加入seen集合,为每个链接生成Request对象,并设置回调函数为_repsonse_downloaded()。
for link in links:
seen.add(link)
#构造Request对象,并将Rule规则中定义的回调函数作为这个Request对象的回调函数。这个‘_build_request’函数在上面定义。
r = self._build_request(n, link)
#对每个Request调用process_request()函数。该函数默认为indentify,即不做任何处理,直接返回该Request。
yield rule.process_request(r)
#处理通过rule提取出的连接,并返回item以及request。
def _response_downloaded(self, response):
rule = self._rules[response.meta['rule']]
return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
#解析response对象,使用callback解析处理他,并返回request或Item对象。
def _parse_response(self, response, callback, cb_kwargs, follow=True):
#1、首先判断是否设置了回调函数。(该回调函数可能是rule中的解析函数,也可能是 parse_start_url函数)
#2、如果设置了回调函数(parse_start_url()),那么首先用parse_start_url()处理response对象,
#3、然后再交给process_results处理。返回cb_res的一个列表。
if callback:
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_output(cb_res):
yield requests_or_item
#如果需要跟进,那么使用定义的Rule规则提取并返回这些Request对象。
if follow and self._follow_links:
#返回每个Request对象。
for request_or_item in self._requests_to_follow(response):
yield request_or_item
def _compile_rules(self):
def get_method(method):
if callable(method):
return method
elif isinstance(method, six.string_types):
return getattr(self, method, None)
self._rules = [copy.copy(r) for r in self.rules]
for rule in self._rules:
rule.callback = get_method(rule.callback)
rule.process_links = get_method(rule.process_links)
rule.process_request = get_method(rule.process_request)
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super(CrawlSpider, cls).from_crawler(crawler, *args, **kwargs)
spider._follow_links = crawler.settings.getbool(
'CRAWLSPIDER_FOLLOW_LINKS', True)
return spider
def set_crawler(self, crawler):
super(CrawlSpider, self).set_crawler(crawler)
self._follow_links = crawler.settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True)
运行流程:
(图片来源 https://blog.csdn.net/qianxin12345/article/details/77899672)

爬取拉勾
首先定义url规则:
rules = (
Rule(LinkExtractor(allow=("zhaopin/.*",)), follow=True),
Rule(LinkExtractor(allow=("gongsi/j\d+.html",)), follow=True),
Rule(LinkExtractor(allow=r'jobs/\d+.html'), callback='parse_job', follow=True)
)
解析数据项函数:
def parse_job(self, response):
item_loader = JobItemLoader(item=LagouItem(),response=response)
item_loader.add_value('url',response.url)
item_loader.add_value('url_object_id',get_md5(response.url))
item_loader.add_xpath('title','//div[@class="job-name"]/@title')
item_loader.add_xpath('salary', '//dd[@class="job_request"]/p/span[@class="salary"]/text()')
item_loader.add_xpath('job_city', '//dd[@class="job_request"]/p/span[2]/text()')
item_loader.add_xpath('work_years_min', '//dd[@class="job_request"]/p/span[3]/text()')
item_loader.add_xpath('work_years_max', '//dd[@class="job_request"]/p/span[3]/text()')
item_loader.add_xpath('degree_need', '//dd[@class="job_request"]/p/span[4]/text()')
item_loader.add_xpath('job_type', '//dd[@class="job_request"]/p/span[5]/text()')
item_loader.add_xpath('pulish_time', '//p[@class="publish_time"]/text()')
item_loader.add_xpath('tags', '//ul[@class="position-label clearfix"]/li[@class="labels"]/text()')
item_loader.add_xpath('job_advantage', '//dd[@class="job-advantage"]/p/text()')
item_loader.add_xpath('job_desc', '//div[@class="job-detail"]')
item_loader.add_xpath('job_addr', '//div[@class="work_addr"]')
item_loader.add_xpath('company_name', '//dl[@id="job_company"]//h2/text()')
item_loader.add_xpath('company_url', '//ul[@class="c_feature"]//a/@href')
item_loader.add_value('crawl_time', datetime.datetime.now())
job_item = item_loader.load_item()
return job_item
定义items:
from w3lib.html import remove_tags #去除html标签
class JobItemLoader(ItemLoader):
default_output_processor = TakeFirst()
def remove_line(value):
#去掉斜线
return value.replace('/','')
def handle_pubtime(value):
return value.split(' ')[0]
def remove_place(value):
#去掉空格与换行
return value.replace('\n','').replace('\xa0','').strip()
def year_min(value):
match_re = re.match(".*(\d+)-\d+.*",value)
if match_re:
return match_re.group(1)
else:
return value
def year_max(value):
match_re = re.match(".*\d+-(\d+).*",value)
if match_re:
return match_re.group(1)
else:
return value
def handle_jobaddr(value):
addr_list = value.split("\n")
addr_list = [item.strip() for item in addr_list if item.strip()!="查看地图"]
return "".join(addr_list)
class LagouItem(scrapy.Item):
url = scrapy.Field()
url_object_id = scrapy.Field()
title = scrapy.Field()
salary = scrapy.Field()
job_city = scrapy.Field(
input_processor = MapCompose(remove_line)
)
work_years_min = scrapy.Field(
input_processor=MapCompose(remove_line,year_min)
)
work_years_max = scrapy.Field(
input_processor=MapCompose(remove_line,year_max)
)
degree_need = scrapy.Field(
input_processor=MapCompose(remove_line)
)
job_type = scrapy.Field(
input_processor=MapCompose(remove_line)
)
pulish_time = scrapy.Field(
input_processor=MapCompose(handle_pubtime)
)
tags = scrapy.Field(
output_processor=Join(",")
)
job_advantage = scrapy.Field()
job_desc = scrapy.Field(
input_processor=MapCompose(remove_tags,remove_place)
)
job_addr = scrapy.Field(
input_processor=MapCompose(remove_tags,handle_jobaddr)
)
company_url = scrapy.Field()
company_name = scrapy.Field(
input_processor=MapCompose(remove_place)
)
crawl_time = scrapy.Field()
运行一下,立马被拉勾网判定为爬虫。

用浏览器访问拉勾依然没问题,说明拉勾网没有封我们的IP,先加个请求头试试(但是很多人也说要加cookies,我在加与不加之间都尝试了很多次,最终不加cookies也可以请求成功,很戏剧性):
注意在start_requests与_build_request都要加上headers
headers = {
"HOST": "www.lagou.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"
}
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url, headers=self.headers, dont_filter=True,callback=self.parse)
def _build_request(self, rule, link):
r = Request(url=link.url,headers=self.headers, callback=self._response_downloaded, dont_filter=True)
r.meta.update(rule=rule, link_text=link.text)
return r
运行一下,似乎可以拿到数据了。
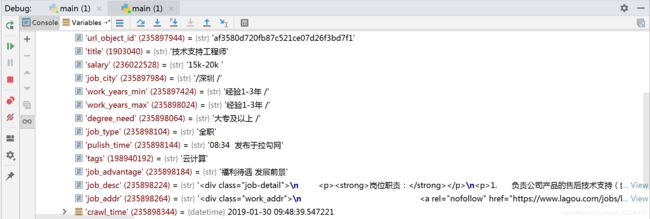
写入数据到Mysql:
1.设计数据表:
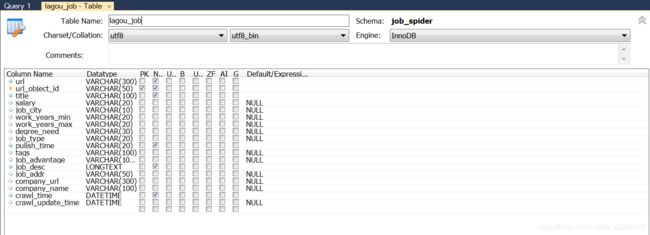
2.改写items
class LagouItem(scrapy.Item):
#省略部分代码。。。。
def get_sql(self):
#便于#根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql = """
insert into lagou_job(url,url_object_id,title,salary,job_city,work_years_min,work_years_max,degree_need,job_type,pulish_time,tags,job_advantage,job_desc,job_addr,company_url,company_name,crawl_time)
VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
ON DUPLICATE KEY UPDATE salary=VALUES(salary), job_desc=VALUES(job_desc), job_advantage=VALUES(job_advantage),
pulish_time=VALUES(pulish_time),crawl_time=VALUES(crawl_time)
"""
#如果存在主键冲突,则更新数据。如果不存在,则插入数据
crawl_time = self["crawl_time"].strftime(SQL_DATETIME_FORMAT)
params = (self["url"], self["url_object_id"], self["title"], self["salary"], self["job_city"], self["work_years_min"], self["work_years_max"], self["degree_need"],self["job_type"],self["pulish_time"],self["tags"],self["job_advantage"],self["job_desc"],self["job_addr"],self["company_url"],self["company_name"], crawl_time)
return insert_sql,params
3.pipelines:
import MySQLdb
import MySQLdb.cursors
from twisted.enterprise import adbapi
class JobspiderPipeline(object):
def process_item(self, item, spider):
return item
class MysqlTwistedPipeline(object):
#采用异步机制写入mysql
def __init__(self,dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls,settings):
dbparms = dict(
host = settings["MYSQL_HOST"],
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset = 'utf8',
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode = True
)
dbpool = adbapi.ConnectionPool("MySQLdb",**dbparms)
return cls(dbpool)
def process_item(self,item,spider):
query = self.dbpool.runInteraction(self.do_insert,item)
query.addErrback(self.handle_error,item,spider)
def handle_error(self,failure,item,spider):
print(failure)
def do_insert(self,cursor,item):
insert_sql,params = item.get_sql()
cursor.execute(insert_sql,params)
现在可以看到数据成功入库了:
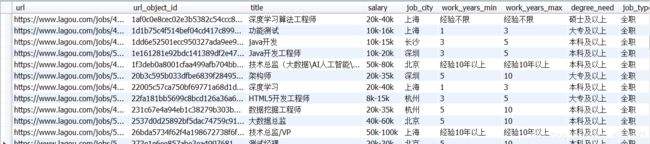
但是依然存在两个问题:
- itemloader处理空值存在问题:我们需要爬取拉勾网页上的信息,但不是所有职位网页中展示的信息都一样,例如有些职位信息网页上并没有附上职位标签tags,而如果没有需要在数据库相应的字段中赋值为空。 但是itemloader默认会略过空值,造成数据入库时KeyError(如下图所示)
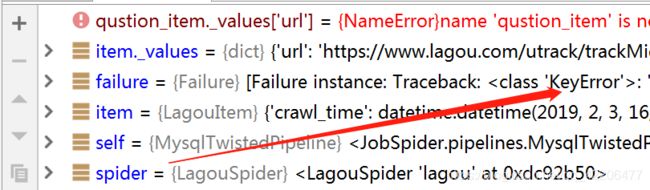
- 爬取了5分钟左右,拉勾网会出现302重定向

首先解决第一个问题:
我们需要对空列表赋值为空字符处理
使用itemloader爬取时,返回的数据类型是list,再存入item容器前,是支持对数据进行预处理的,即输入处理器和输出处理器,可以通过MapCompose这个类来依次对list的元素进行处理,但如果list为空则不会进行处理,这种情况需要重载MapCompose类的__call__方法,如下,给value增加一个空格str“ ”
class MapComposeCustom(MapCompose):
#自定义MapCompose,当value没元素时传入" "
def __call__(self, value, loader_context=None):
if not value:
value.append(" ")
values = arg_to_iter(value)
if loader_context:
context = MergeDict(loader_context, self.default_loader_context)
else:
context = self.default_loader_context
wrapped_funcs = [wrap_loader_context(f, context) for f in self.functions]
for func in wrapped_funcs:
next_values = []
for v in values:
next_values += arg_to_iter(func(v))
values = next_values
return values
tags = scrapy.Field(
input_processor=MapComposeCustom(remove_line),
output_processor=Join(",")
)
如此一来,第一个问题就解决了。
我们检查一下数据库情况:

tags字段中存在为空的数据,那么说明我们的第一个问题解决了。
(参考文章:https://blog.csdn.net/m0_37323771/article/details/83211816)
第二个问题:
经过试验,发现只要爬取时间超过5分钟,就会出现302重定向问题,此时我们便无法取到需要的数据。
但是稍微等一段时间,就可以正常爬取了。
这个问题,我还没解决,先占个坑。。。
学艺不精,不对的地方望大家指正~