非线性时间序列回归模型代码实现(R语言)
非线性时间序列回归模型代码实现(R语言)
Financial Metrology Semester end Project
一、引言
时间序列建模大部分局限于线性自回归滑动平均模型(ARMA),但仍存在许多超出其建模能力的非线性特征因此考虑引入非线性时间序列建模,本文采用函数系数建模技术对非线性时间序列数据进行分析。该方法在不受“维数诅咒”影响的情况下,使拟合模型的结构具有相当大的灵活性。
函数系数模型建模如下:
令 { U i , X i , Y i } i = − ∞ ∞ \left\{\mathbf{U}_{i}, \mathbf{X}_{i}, Y_{i}\right\}_{i=-\infty}^{\infty} {Ui,Xi,Yi}i=−∞∞为共同严格平稳过程, U i U_{i} Ui 在 ℜ κ \Re^{\kappa} ℜκ 处取值, X i \mathbf{X}_{i} Xi 在 ℜ p \Re^{p} ℜp处取值. 并且确保 K K K值较小,进而定义多元回归函数:
m ( u , x ) = E ( Y ∣ U = u , X = x ) m(\mathbf{u}, \mathbf{x})=E(Y \mid \mathbf{U}=\mathbf{u}, \mathbf{X}=\mathbf{x}) m(u,x)=E(Y∣U=u,X=x)
二、Project(ESTIMATION)
1.局部线性回归估计(Local Linear Regression Estimation)
1.1证明
首先,局部线性估计量定义为 a ^ j ( u 0 ) = a ^ j \hat{a}_{j}\left(u_{0}\right)=\hat{a}_{j} a^j(u0)=a^j我们要证明 { ( a ^ j , b ^ j ) } \left\{\left(\hat{a}_{j}, \hat{b}_{j}\right)\right\} {(a^j,b^j)}使加权平方和最小化:
∑ i = 1 n [ Y i − ∑ j = 1 p { a j + b j ( U i − u 0 ) } X i j ] 2 K h ( U i − u 0 ) ( 1 ) \sum_{i=1}^{n}\left[Y_{i}-\sum_{j=1}^{p}\left\{a_{j}+b_{j}\left(U_{i}-u_{0}\right)\right\} X_{i j}\right]^{2} K_{h}\left(U_{i}-u_{0}\right) (1) i=1∑n[Yi−j=1∑p{aj+bj(Ui−u0)}Xij]2Kh(Ui−u0)(1)
X i j X_{i j} Xij在这里是 j j j行的列向量,我们将式子 ( 1 ) (1) (1)后半部分展开,得到:
{ a 1 + b 1 ( U i − u 0 ) , … , a n + b n ( U i − u 0 ) } [ X i 1 X i 2 ⋮ X i n ] \left\{a_{1}+b_{1}\left(U_{i}-u_{0}\right), \ldots, a_{n}+b_{n}\left(U_{i}-u_{0}\right)\right\}\left[\begin{array}{c} X_{i 1} \\ X_{i 2} \\ \vdots \\ X_{i n} \end{array}\right] {a1+b1(Ui−u0),…,an+bn(Ui−u0)}⎣⎢⎢⎢⎡Xi1Xi2⋮Xin⎦⎥⎥⎥⎤
= [ a 1 , a 2 , … , a n , b 1 , b 2 , … , b n ] [ X i 1 ⋮ X i n X i 1 ( U i − u 0 ) ⋮ X i n ( U i − u 0 ) ] ( 2 ) =\left[a_{1}, a_{2}, \ldots, a_{n}, b_{1}, b_{2}, \ldots, b_{n}\right]\left[\begin{array}{c} X_{i 1} \\ \vdots X_{i n} \\ X_{i 1}\left(U_{i}-u_{0}\right) \\ \vdots \\ X_{i n}\left(U_{i}-u_{0}\right) \end{array}\right](2) =[a1,a2,…,an,b1,b2,…,bn]⎣⎢⎢⎢⎢⎢⎢⎡Xi1⋮XinXi1(Ui−u0)⋮Xin(Ui−u0)⎦⎥⎥⎥⎥⎥⎥⎤(2)
由(2)结合 X ~ \tilde{\mathbf{X}} X~ = ( X i T , X i T ( U i − u 0 ) ) \left(\mathbf{X}_{i}^{T}, \mathbf{X}_{i}^{T}\left(U_{i}-u_{0}\right)\right) (XiT,XiT(Ui−u0)) 为 n × 2 p n \times 2 p n×2p 矩阵可以得到:
X ~ = [ X 1 T X 1 T ( U 1 − u 0 ) X 2 T X 2 T ( U 2 − u 0 ) ⋮ X n T X n T ( U n − u 0 ) ] \widetilde{X}=\left[\begin{array}{c} X_{1}^{T} X_{1}^{T}\left(U_{1}-u_{0}\right) \\ X_{2}^{T} X_{2}^{T}\left(U_{2}-u_{0}\right) \\ \vdots \\ X_{n}^{T} X_{n}^{T}\left(U_{n}-u_{0}\right) \end{array}\right] X =⎣⎢⎢⎢⎡X1TX1T(U1−u0)X2TX2T(U2−u0)⋮XnTXnT(Un−u0)⎦⎥⎥⎥⎤
我 们 令 : α = [ a 1 ⋮ a p b 1 ⋮ b p ] 也 为 2 p × 1 矩 阵 我们令:\alpha=\left[\begin{array}{c} a_{1} \\ \vdots \\ a_{p} \\ b_{1} \\ \vdots \\ b_{p} \end{array}\right] 也为2p\times1矩阵 我们令:α=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡a1⋮apb1⋮bp⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤也为2p×1矩阵
同时 W = diag { K h ( U 1 − u 0 ) , … , K h ( U n − u 0 ) } \mathbf{W}=\operatorname{diag}\left\{K_{h}\left(U_{1}-\right.\right.\left.\left.u_{0}\right), \ldots, K_{h}\left(U_{n}-u_{0}\right)\right\} W=diag{Kh(U1−u0),…,Kh(Un−u0)}
于是可以得到:
f ( α ) = ( X ~ β − Y ) T W ( X ~ β − Y ) f(\alpha)=(\widetilde{X} \beta-Y)^{T} W(\widetilde{X} \beta-Y) f(α)=(X β−Y)TW(X β−Y)
逐步展开:
∂ ∂ α f ( α ) = ∂ ∂ α ( X ~ α − Y ) T W ( X ~ α − Y ) = ∂ ∂ α ( α T X ~ T W X ~ α − α T X ~ T W Y − Y T W X ~ α + Y T W Y ) = 2 ( X ~ T W X ~ α − X ~ T W Y ) \begin{array}{c} \frac{\partial}{\partial \alpha} f(\alpha)=\frac{\partial}{\partial \alpha}(\widetilde{X} \alpha-Y)^{T} W(\widetilde{X} \alpha-Y) \\ =\frac{\partial}{\partial \alpha}\left(\alpha^{T} \widetilde{X}^{T} W \widetilde{X} \alpha-\alpha^{T} \widetilde{X}^{T} W Y-Y^{T} W \widetilde{X} \alpha+Y^{T} W Y\right) \\ =2\left(\widetilde{X}^{T} W \widetilde{X} \alpha-\widetilde{X}^{T} W Y\right) \end{array} ∂α∂f(α)=∂α∂(X α−Y)TW(X α−Y)=∂α∂(αTX TWX α−αTX TWY−YTWX α+YTWY)=2(X TWX α−X TWY)
由于其一阶导为 0 0 0,我们可以得到下式:
α = ( X ~ T W X ~ ) − 1 X ~ T W Y \alpha=\left(\widetilde{X}^{T} W \widetilde{X}\right)^{-1} \widetilde{X}^{T} W Y α=(X TWX )−1X TWY
1.2代码逻辑
(1)核函数
定义核密度函数
Q<-4
p.max<-2
kernel<-function(x){
0.75*(1-x^2)*(abs(x)<=1)
}
Kh <- function(x, h){
Kh = kernel(x / h) / h
return(Kh)
}
(2) β \beta β估计
该函数返回假设系数非线性的beta估计
beta_hat<-function(y,x,h,u0,u00){
z<-length(u0) #网格点数
n<-length(y) #data的长度
beta_hat<-rep(0,z*2)
dim(beta_hat)<-c(z,2) #beta_hat的维度
for (i in 1:z){
X_hat<-cbind(x,(u0-u00[i])*x)#定义U为X(t-1)
w0<-Kh((u0-u00[i]),h)#由Kh组成的W矩阵
beta<-solve(t(X_hat)%*%(w0*X_hat)+0.001*diag(2*2))%*%(t(X_hat)%*%(w0*y))#用来返回每个网格点出beta的估计值
beta_hat[i,]<-beta[1:2]
}
return(beta_hat)
}
2.带宽选择(Bandwidth Selection)
本文的带宽选择法可以看作是一种针对平稳时间序列数据结构的改进版多重交叉验证准则。主要求解下式平均均方误差最小值,并返回h:
AMS q ( h ) = 1 m ∑ i = n − q m + 1 n − q m + m { Y i − ∑ j = 1 p a ^ j , q ( U i ) X i , j } 2 \operatorname{AMS}_{q}(h)=\frac{1}{m} \sum_{i=n-q m+1}^{n-q m+m}\left\{Y_{i}-\sum_{j=1}^{p} \hat{a}_{j, q}\left(U_{i}\right) X_{i, j}\right\}^{2} AMSq(h)=m1i=n−qm+1∑n−qm+m{Yi−j=1∑pa^j,q(Ui)Xi,j}2
2.1代码逻辑
(1)带宽选择
h_min<-function(h0){
n<-length(y)
m<-floor(0.1*n)
ams<-rep(0,4*1)
dim(ams)<-c(1,4)
for(q in 1:4){
n1<-n-q*m#AMS方程求和符号的上下界公有部分
y0<-y[1:n1]
x0<-x[1:n1,]
u0<-u[1:n1]
u00<-u[(n1+1):(n1+m)] #求和上下界
h<-h0*(n/n1)^0.2 #rescale之后的h,可以被认为是最优的h
beta_hat<-beta_hat(y0,x0,h,u0,u00)#预测
yhat<-apply(beta_hat*x[(n1+1):(n1+m),],1,sum)#对每一行求和
ams[,q]<-mean((y[(n1+1):(n1+m)]-yhat)^2)}
ams<-apply(ams,1,sum)#对每一行求和
return(ams)
}
3.拟合优度检验
本文提出了一种基于参数拟合和非参数拟合残差平方和(RSS)的拟合优度检验方法,主要通过构建
T n = ( R S S 0 − R S S 1 ) / R S S 1 = R S S 0 / R S S 1 − 1 \mathbf{T}_{n}=\left(\mathrm{RSS}_{0}-\mathrm{RSS}_{1}\right) / \mathrm{RSS}_{1}=\mathrm{RSS}_{0} / \mathrm{RSS}_{1}-1 Tn=(RSS0−RSS1)/RSS1=RSS0/RSS1−1
再通过Bootstrap抽样法完成非参数拟合估计,将 T n ∗ ≥ T n \mathbf{T}_{n}^{*} \geq \mathbf{T}_{n} Tn∗≥Tn作为事件,当 T n Tn Tn大于 T n ∗ T^*_n Tn∗条件分布的上的upper- α \alpha α 点时,拒绝原假设,并判断p-value。
3.1代码逻辑
(1)Bootstrap
temp=c(0,0.2,0.4,0.6,0.8,1)
power=c()
for (i in 1:4){
power_temp<-c()
for (beta_linear in temp){ #每取一个beta就bootstrap一次,bootstrap的循环
#假设:系数为常数 SSR_0
theta=solve(t(X)%*%X)%*%t(X)%*%Y#假设为线性时候的最小二乘估计量 a_j=theta_j
SSR_0<-(sum(Y-X%*%theta)^2)/400
#假设:系数不为常数 SSR_1
#估计系数的值
beta<-beta_hat(y0,x0,0.41,u0,Z)
#加入线性程度beta,先用0,0.5和1尝试
a_j_1=mean(beta[,1])+beta_linear*(beta[,1]-mean(beta[,1]))
a_j_2=mean(beta[,2])+beta_linear*(beta[,2]-mean(beta[,2]))
a_j=c(a_j_1,a_j_2)
y_hat<-apply(a_j*X,1,sum)#估计的y_hat
SSR_1<-(sum(Y-y_hat)^2)/400
#计算残差平方和和T_n值
T_n=(SSR_0/SSR_1-1)
epsil<-Y-y_hat#残差
epsil_bar=sum(epsil)/400#平均的残差
epsil<-epsil-(epsil_bar)#中心化的残差
T_n_rej<-c()
for (i in 1:100){#bootstrap
ee_star=sample(epsil,400,replace = TRUE)
x_boot = numeric()
x_boot[1] = 1
x_boot[2] = 1
for (i in 1:400) {
x_boot[i+2] = cbind(x_boot[i+1],x_boot[i])%*%theta+ee_star[i]
}
X_boot = cbind(x_boot[2:401],x_boot[1:400])
Y_boot = x_boot[3:402]#bootstrap样本
#原假设:系数为常数 SSR_b_0
theta_b=((solve(t(X_boot)%*%X_boot)%*%t(X_boot))%*%Y_boot)#假设为线性时,经过bootstrap得到的系数
#计算bootstrap的SSR_0
SSR_b<-((Y_boot-X_boot%*%theta_b)^2)/400
#备择假设:系数不为常数 SSR_b_1
#取bootstrap样本
y_b<-Y_boot[1:360]
x_b<-X_boot[1:360,]
U0=matrix(data=x_boot[2:401],nrow=400,ncol=1,byrow=FALSE)
U0=cbind(U0,U0)
U_b<-U0[1:360]
beta_b<-beta_hat(y_b,x_b,0.41,U_b,Z)#用bootstrap生成的数据对系数进行估计,部分,长度为 360
a_j_1=mean(beta[,1])+beta_linear*(beta[,1]-mean(beta[,1]))
a_j_2=mean(beta[,2])+beta_linear*(beta[,2]-mean(beta[,2]))
a_j=c(a_j_1,a_j_2)
y_hat_b<-apply(a_j*X_boot,1,sum)#估计bootstrap下的y_hat
#计算bootstrap的T_n_star
SSR_b_1<-(((Y_boot-y_hat_b)^2)/400)
T_n_star=(SSR_b/SSR_b_1)-1
T_n_rej<-cbind(T_n_rej,rejection(T_n,T_n_star))
}
T_n_rej<-sum(T_n_rej)/100
power_temp<-cbind(power_temp,T_n_rej)
}
power<-rbind(power,power_temp)
}
power<-matrix(power,ncol=6)
三、实例检验(NUMERICAL PROPERTIES )
1.例1(Simulated Examples)
1.1估计值与真实值绘图
生成数据如下
a1 <- function(x){
y = .138 + (.316 + .982 * x) * exp(-3.89 * x^2)
return(y)
}
a2 <- function(x){
y = -.437 - (.659 + 1.26 * x) * exp(-3.89 * x^2)
return(y)
}
epsil= rnorm(1000, 0, .2)
x = numeric()
x[1] = 1
x[2] = 1
for (i in 1:1000) {
x[i+2] = a1(x[i+1]) * x[i+1] + a2(x[i+1]) * x[i] + epsil[i]
}
X = cbind(x[602:1001],x[601:1000])
Y = x[603:1002]
根据题意,定义U为X的滞后一期
U=matrix(data=X[602:1001],nrow=400,ncol=1,byrow=FALSE)
U=cbind(U,U)
接下来通过生成的数据进行真实值 a 1 ( u ) a1(u) a1(u)与估计值图像绘制:

同理,再次生成数据,测绘 a 2 ( u ) a2(u) a2(u)与估计值图像
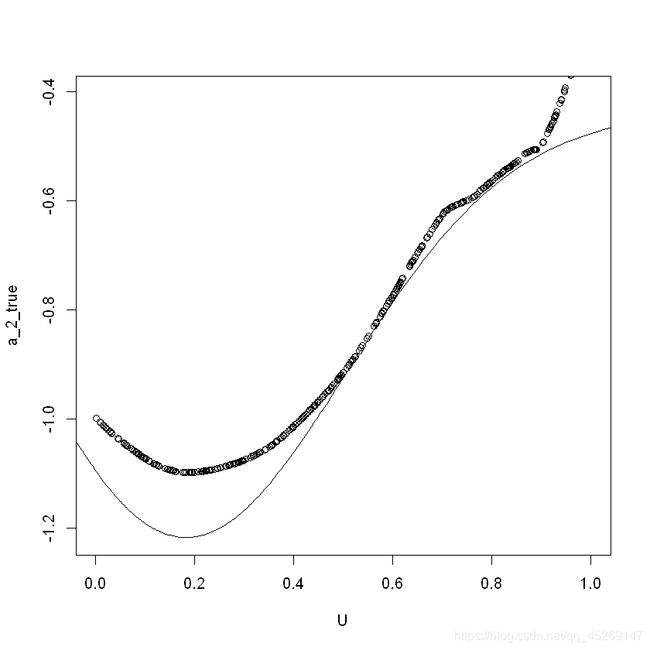
1.2RASE箱线图
最后,我们对本例 a 1 ( ⋅ ) and a 2 ( ⋅ ) a_{1}(\cdot) \text { and } a_{2}(\cdot) a1(⋅) and a2(⋅)估计中400个RASE值进行绘制。
RASE<-function(Z){
RASE_1<-c()
RASE_2<-c()
RASE<-c()
for (i in 1:400){
varepsilon = rnorm(1000, 0, .2)
x = numeric()
x[1] = 0
x[2] = 0
for (i in 1:1000) {
x[i+2] = a1(x[i+1]) * x[i+1] + a2(x[i+1]) * x[i] + varepsilon[i]
}
X1 = cbind(x[602:1001],x[601:1000])
Y1 = x[603:1002]
U1=matrix(data=x[602:1001],nrow=400,ncol=1,byrow=FALSE)
U1=cbind(U1,U1)
y10<-Y1[1:360]
x10<-X1[1:360,]
u10<-U1[1:360]
beta<-beta_hat(y10,x10,0.41,u10,Z)
y_hat<-beta[,1]
y_true<-.138 + (.316 + .982 * Z) * exp(-3.89 * Z^2)
y_hat1<-beta[,2]
y_true1<--.437 - (.659 + 1.26 * Z) * exp(-3.89 * Z^2)
RASE_2<-c(RASE_2,(sum((y_hat1-y_true1)^2/length(Z)))^(1/2))
RASE_1<-c(RASE_1,(sum((y_hat-y_true)^2/length(Z)))^(1/2))
}
RASE<-c(RASE_1,RASE_2)
return (RASE)
}
得到如下结果:
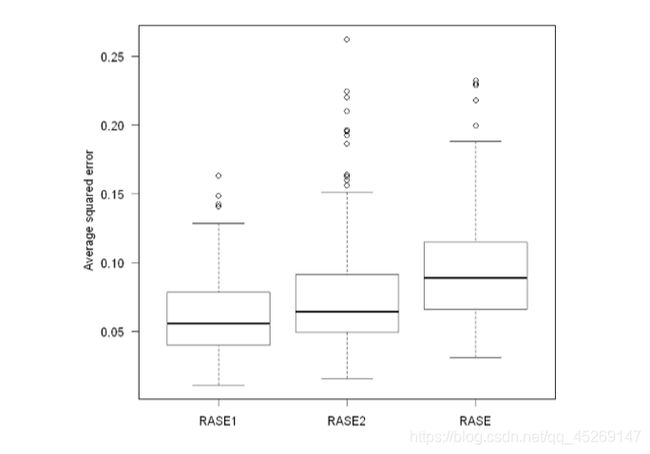
可以看到400次估计的均方误差离论文结果较为接近,仍有改良空间,主要为估计值算法的优化。
2.例2 TAR model
1.1估计值与真实值绘图
由于本例 a ( . ) a(.) a(.)为示性函数结果,所以数据生成与前文略微不同,设置了分段函数,同时,本例X值为U的滞后两期.
生成数据如下(改)
a11 <- function(Z){
for (i in 1:length(Z)){
if(Z[i]<=1)
Z[i]=0.4
else
Z[i]=-0.8
}
return(Z)
}
a22 <- function(Z){
for (i in 1:length(Z)){
if(Z[i]<=1)
Z[i]=-0.6
else
Z[i]=0.2
}
return(Z)
}
epsil= rnorm(1000, 0, .2)
x = numeric()
x[1] = 1
x[2] = 1
for (i in 1:1000) {
x[i+2] = a1(x[i]) * x[i+1] + a2(x[i]) * x[i] + epsil[i]
}
X = cbind(x[602:1001],x[601:1000])
Y = x[603:1002]
根据题意,设X为U的滞后两期
U1=matrix(data=x[501:1000],nrow=500,ncol=1,byrow=FALSE)
U1=cbind(U1,U1)
接下来通过生成的数据进行真实值 a 1 ( u ) a1(u) a1(u)与估计值图像绘制:
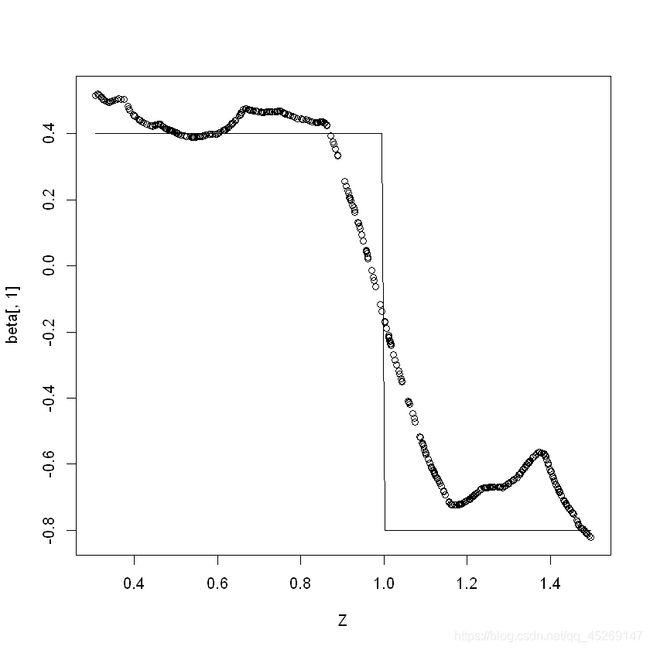
同理,再次生成数据,测绘 a 2 ( u ) a2(u) a2(u)与估计值图像
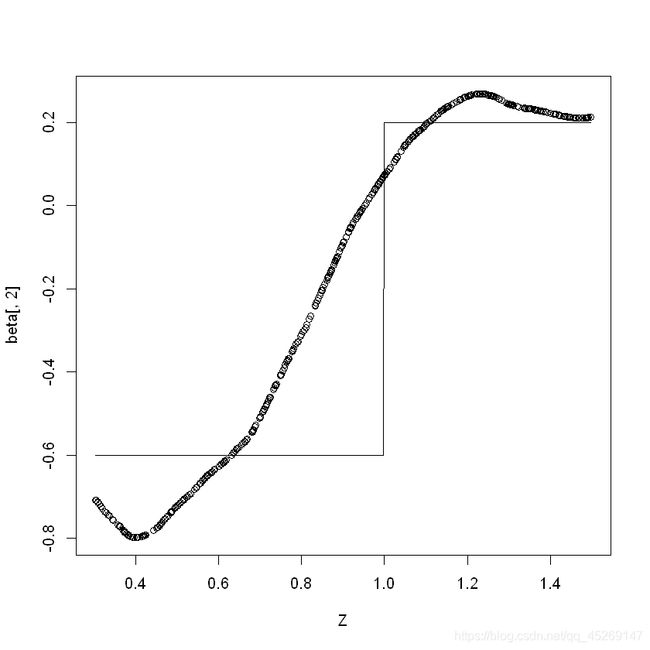
1.2RASE箱线图
RASE<-function(Z){
RASE_1<-c()
RASE_2<-c()
RASE<-c()
for (i in 1:400){
varepsilon = rnorm(1000, 0,1)
x = numeric()
x[1] = 0
x[2] = 0
for (i in 1:1000) {
x[i+2] = a11(x[i]) * x[i+1] + a22(x[i]) * x[i] + varepsilon[i]
}
X1 = cbind(x[502:1001],x[501:1000])
Y1 = x[503:1002]
U1=matrix(data=x[501:1000],nrow=500,ncol=1,byrow=FALSE)
U1=cbind(U1,U1)
y10<-Y1[1:450]
x10<-X1[1:450,]
u10<-U1[1:450]
beta<-beta_hat(y10,x10,0.325,u10,Z)
y_hat<-beta[,1]
y_true<-a11(Z)
y_hat1<-beta[,2]
y_true1<-a22(Z)
RASE_2<-c(RASE_2,(sum((y_hat1-y_true1)^2/length(Z)))^(1/2))
RASE_1<-c(RASE_1,(sum((y_hat-y_true)^2/length(Z)))^(1/2))
}
RASE<-c(RASE_1,RASE_2)
return (RASE)
}
图示如下:
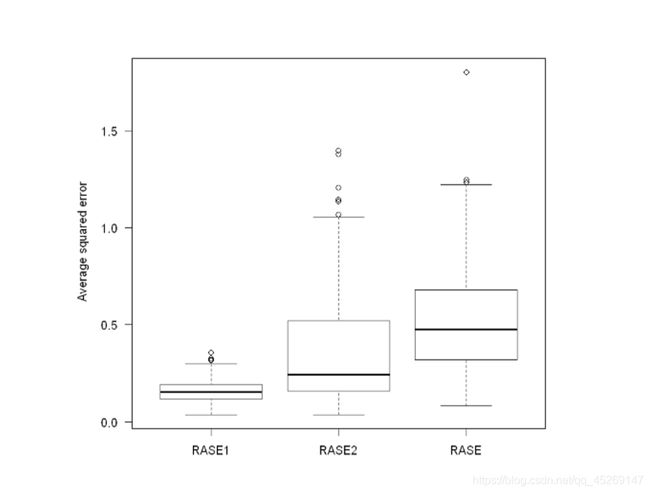
和论文中的RASE值有一定差距.