Redis技术总结
Redis的基本内容
1. 什么是redis
a) Nosql 泛指非关系型数据库(基于键值对,不需要SQL层解析,性能高,易扩展,内存存储,读写速度快,低成本)
b) Redis是nosql产品,其他的比如:mangoDB等,redis是开源的高性能键值对数据库
c) 拓展:关系型数据库(oracle,mysql)支持多表复杂查询,事物支持等
2. redis的特性

3. redis的应用场景
实现缓存(主流缓存技术:redis和Memcached),实现消息列队(利用redis的存储列表类型),分布式锁
二者谁的性能更高?
单纯从缓存命中的角度来说,是Memcached要高,Redis和Memcache的差距不大
但是,Redis提供的功能更加的强大
二者的区别是什么?
Memcache是多线程
Redis是单线程
4. Redis的多数据库:
redis中默认支持16个数据库,对外是以0开始的数字命名,可以通过参数databases来修改数据库个数,连接后默认选择0号数据库,可以通过select 1来选择1号数据库!各个数据库之前并不是完全隔离的,可以通过flushall来清空所有数据库,通过flushDB来清空当前数据
5. Redis的持久化
a. Redis支持2种持久化(半持久化RDB和全持久化AOF方式)
RDB持久化:指定时间间隔内将内存数据集以快照形式写入磁盘,以二进制文件保存,文件名默认:dump.rdb,redis重启后自动读取其中文件
AOP持久化:redis执行的每一个写操作命令,都会把它记录并追加到appendonly.aof文件文件中,当redis重启时,将会读取AOF文件进行“重放”以恢复
b. 如何实现持久化以及优缺点:
实现RDB:在redis.conf配置文件中:save N M表示在N秒之内,redis至少发生M次修改则redis抓快照到磁盘。也可以手动执行save或者bgsave(异步)做快照。是默认的持久化方式
如:save 900 1 表示:900秒之内,如果超过1个key被修改,则发起快照保存;
优点:RDB 可以最大化Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作
缺点:不能完全保证数据持久化,因为是定时保存,所以当redis服务down掉,就会丢失一部分数据,而且数据量大,fork子进程可能导致服务停止服务几毫秒到1秒,会影响性能
实现AOF:在redis.conf配置文件中,将appendonly修改为yes(默认为no)
优点:数据完整性好,可以配置策略什么时候从硬盘缓存写到硬盘AOF文件中(效率不同)
appendfsyncalways #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsyncno #从不同步。高效但是数据不会被持久化。
缺点:AOF文件比RDB文件大,AOF性能比RDB差
RDB ,AOF原理,运作方式 更多请参考:http://redisdoc.com/topic/persistence.html
6. Redis的基本命令
KEYS * 获取所有的键名列表(KEYS pattern (pattern可以是?:一个字符,*:任意个字符,[a-f]:a-f之间任意一个字符),\x:匹配字符x)
EXISTS key:判断key是否存在,存在返回1,不存在返回0
DEL key([k1,k2]):删除key,支持多个key,返回删除的个数
TYPE key([k1,k2]):获取key所对应值得类型,支持多个key(string,hash,list,set,zset)
HELP TAB键7. Redis的字符串数据类型
可以储存任意形式的字符串类型,二进制数据,json化对象,字节数组等,一个字符串类型存储的最大数据容量为512M
常用方法:
SET key value [NX|XX] [EX seconds] [PX milliseconds]
set(key, value, nxxx, expx, time)
EX:设置过期时间(单位秒)
PX:设置过期时间(单位毫秒)
NX:只有key不存在的时候设置value
XX:只有key存在的时候设置value
SETEX key seconds value :设置值的同时设置key的过期时间(秒)相当于SET mykey value +EXPIRE mykey seconds
PSETEX key milliseconds valu:PSETEX和SETEX一样,唯一的区别是到期时间以毫秒为单位,而不是秒
SETNX key value :当key不存在的时候设置值,存在的时候不操作
SET key value
GET key
INCR key :将key中存储的数值+1,返回的是递增后的值。如果该key不存在,则初始化key为0。如果类型不对或者不是整数,则报错
INCRBY key i: 将key中存储的数值+i
DECR key: 将key中存储的数值-1
DECRBY key i: 将key中存储的数值-i
APPEND key value:将key中存储的值追加上value
STRLEN key:获取key中存储的值得长度
MSET k1,v1,k2,v2
MGET k1,k2
GETSET key newValue :将key对应的value值设置成newValue,并返回老的value
8. Redis的散列数据类型(hash)
数据结构:Map
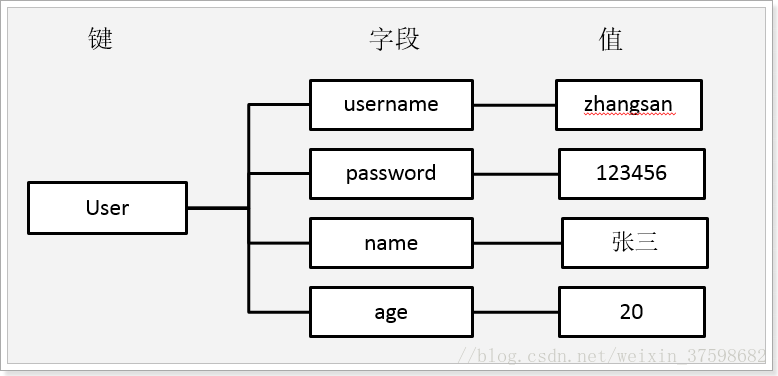
常用命令:
HSET key field value (不区分插入或更新操作,插入返回1,更新返回0)
HGET key field
HMSET key f1 v1 f2 v2…
HMGET key f1 f2..
HGETALL key 获取所有的
HEXISTS key field 判断value是否存在
HSETNX key field value: 插入数据(数据不存在,同HSET),不做任何操作(当数据存在时)
HINCRBY key field i:将key filed 对应的value值增加i
HDEL key f1 f2.. :删除,返回删除的个数
HKEYS key :获取字段名(即key 对应所有的field)
HVALS key :获取字段值(即key 对应所有的value)
HLEN key :获取字段的数量(即key 对应所有的field的数量)
9. Redis的列表数据类型
数据结构:Map

列表数据结构类型栈结构,用于存储简单的字符串类型的列表,按照插入顺序排序,先插入的在底部,最后插入的在头部
Lpush : 先插入的最右边,最后插入的最左边
Rpush:先插入的最左边,最后插入的最后边
常用方法:
LPUSH keyv1 v2 .. :将1个或多个值从左边依次插入,先插入v1在后边,再插入v2在左边 (右:RPUSHkey v1 v2 )
LPOP key :从左边移除列表第一个元素并返回 (右边移除: RPOP key)
LPUSHX keyv1 v2:将1个或多个值从左边插入到已经存在的列表中
LINDEX key index :通过索引获取列表中元素(最后插入的索引为0,依次往前推,负数表示从后往前,-1表示最后一个,-2表示倒数第二个,没有RINDEX)
LRANGE keyiStart iStop :通过索引范围(闭区间[ ])获取列表中元素(没有RRANGE)
LSET keyindex value :通过索引设置列表的元素的值
LTRIM keyiStart iStop :保留索引范围内(闭区间)的元素,其他元素删除
LREM keycount value :从列表中删除字段值为value的元素,删除个数是count的绝对值(count>0从左边删除,count=0全部删除,count<0从右边删除)
RPOPLPUSH resource destination:原子性的返回并移除resource 列表中最后一个元素(尾部)并把它添加到destination列表的第一个位置(列表头部)
例如:假设 source 存储着列表a,b,c, destination存储着列表 x,y,z。执行 RPOPLPUSH 得到的结果是 source 保存着列表 a,b ,而 destination 保存着列表 c,x,y,z。
如果 source 不存在,那么会返回 nil 值,并且不会执行任何操作。 如果 source 和 destination 是同样的,那么这个操作等同于 移除列表最后一个元素并且把该元素放在列表头部, 所以这个命令也可以当作是一个旋转列表的命令。
BLPOP key1key2.. timeout : 移除并获取列表的第一个元素,如果列表没有元素,则会一直阻塞列表知道等待超时或者发现可弹出元素(timeout=0则会一直等待),先从key1对应的列表取,取到就返回key1和对应的元素,没有去取key2,同前一个。
BRPOP key1key2.. timeout : 移除并获取列表的最后一个元素,如果列表没有元素,则会一直阻塞列表知道等待超时或者发现可弹出元素
LINSERT keyBEFORE/AFTER target value : 在key对应的列表中找target元素,找到后在他之前或之后插入value元素
LLEN key :返回列表长度10. Redis的集合数据类型
数据结构Map
Redis集合数据类型是String类型的无序集合,集合成员是唯一的,不能出现重复的数据(插入重复元素,redis会忽略操作)
结构图如下

常用方法:
SADD key m1 m2.. :向key对应的集合中添加多个元素
SREM key m1 m2.. : 移除key对应集合中的多个元素
SPOP key :随机移除集合中的一个元素
SMEMBERS key :返回集合中的所有元素
SCARD key :返回集合中元素的个数
SISMEMBER key member : 判断member是否是集合元素
SMOVE resource destination member : 将resource集合的member元素移到destionation中
SDIFF key1 [key2..] : 以key1为基准,返回key1有且[key2 key3..等]没有的元素
SINTER key1 [key2…] :返回所有集合的交集!
SINTERSTORE destination key1 [key2..] :获取所有集合的交集并存储在destionation集合中
SUNION key1 [key2…] :返回所有集合的并集
SUNIONSTORE destination key1 [key2..] : 获取所有集合的交集并存储在destionation集合中
11. Redis的有序集合类型
数据结构Map
是String类型的元素的集合,不允许重复的值,每个元素都关联一个double类型的分数,分数可以重复,redis有序集合按照分数从小到大排序。
Redis有序集合默认是升序的,分数越小排名越靠前,即分数越低元素下标越小
命令格式 说明
ZADD key score1 member1 [score2 member2 ...] 添加一个或多个成员到有序集合,或者如果它已经存在更新其分数
ZRANGE key start stop [WITHSCORES] 把集合排序后,返回名次在[start,stop]之间的元素。 WITHSCORES是把score也打印出来
ZREVRANGE key start stop [WITHSCORES] 倒序排列(分数越大排名越靠前),返回名次在[start,stop]之间的元素
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset n] 集合(升序)排序后取score在[min, max]内的元素,并跳过offset个,取出n个
ZREM key member [member ...] 从有序集合中删除一个或多个成员
ZRANK key member 确定member在集合中的升序名次
ZREVRANK key member 确定member在集合中的降序名次
ZSCORE key member 获取member的分数
ZCARD key 获取有序集合中成员的数量
ZCOUNT key min max 计算分数在min与max之间的元素总数
ZINCRBY key increment member 给member的分数增加increment
ZREMRANGEBYRANK key start stop 移除名次在start与stop之间的元素
ZREMRANGEBYSCORE key min max 移除分数在min与max之间的元素
12. 设置redis的生存时间
缓存设置生存时间,到期自动销毁
EXPIRE key seconds
TTL key :查看生存时间(-1 表示没有生存时间,永久存储,-2表示数据已经被删除,>0的数字表示剩余的秒数)
PERSIST key :消除生存时间(重新设置值也会清空生存时间)Redis的java客户端操作
1. java的客户端Redis支持主要通过jedis的支持(需要导入jedis的依赖),jedis是redis官方推出的一款面向Java的客户端,提供了很多接口供Java语言调用
通过jedis的API来操作redis键值对,设置,获取等操作!
a. 直接使用jedis:创建jedis对象并指定ip和端口,通过jedis来设置或者获取值
//通过jedis操作redis
public class JedisDemo {
public static void main(String[] args) {
Jedis jedis = new Jedis("112.162.184.15",6379);
jedis.set("a", "1");
System.out.println(jedis.get("a"));
//pool.returnResource(jedis);
jedis.close();//新版本 关闭的时候自动还给连接池
pool.close();
}b . 从连接池中获取jedis : 构建连接池配置信息并指定最大连接数,构建连接池对象指定连接池配置信息,IP,端口,然后从连接池中获取jedis连接来操作!用完后要把jedis连接返回给连接池并关闭连接池。
//通过连接池jedisPool操作jedis
public class JedisDemo {
public static void main(String[] args) {
//构建连接池配置信息
JedisPoolConfig config = new JedisPoolConfig();
//设置最大连接数
config.setMaxTotal(1024);
//保存idle状态对象的最大个数
config.setMaxIdle(200);
//池内没有对象最大等待时间
config.setMaxWaitMillis(1000);
//当调用borrow Object方法时,是否进行有效性检查
config.setTestOnBorrow(false);
//当调用return Object方法时,是否进行有效性检查
config.setTestOnReturn(false);
//构建连接池
JedisPool pool =new JedisPool(config, "10.116.184.15", 6376);
Jedis jedis = pool.getResource();
jedis.set("a", "1");
System.out.println(jedis.get("a"));
//pool.returnResource(jedis);
jedis.close();//新版本 关闭的时候自动还给连接池
pool.close();
}c. redis的集群
redis的分片式集群
主要思想:采用哈希算法将redis数据的key进行散列,通过hash函数,特定的key会被映射到特定的redis节点,这样客户端就知道该指向那个redis节点
分片:就是把数据拆分到多个redis实例的过程,这样每个redis实例将包含完整数据的一部分
分片的方式:哈希分片
哈希分片:适用于任何键,使用哈希函数将键名转换成一个数字,在对这个数字进行取模运算,得到的数字映射不同的redis 实例
存在的问题:无法动态的增加或者减少节点,扩容麻烦,数据备份麻烦等
Jedis的分片特点:采用一致性哈希算法,将key和节点name同时hashing,然后进行映射匹配,采用一致性哈希匹配而不是采用一般的哈希求模映射,主要原因是当增加或减少节点的时候,不会产生由于重新分配而造成的rehashing,一致性哈希算法只会影响相邻节点key的分配,影响较小。
public class ShardedJedisPoolDemo {
public static void main(String[] args) {
// 构建连接池配置信息
JedisPoolConfig config = new JedisPoolConfig();
//设置最大连接数
config.setMaxTotal(1024);
//保存idle状态对象的最大个数
config.setMaxIdle(200);
//池内没有对象最大等待时间
config.setMaxWaitMillis(1000);
//当调用borrow Object方法时,是否进行有效性检查
config.setTestOnBorrow(false);
//当调用return Object方法时,是否进行有效性检查
config.setTestOnReturn(false);
// 定义集群信息
List shards = new ArrayList();
shards.add(new JedisShardInfo("127.0.0.1", 6379));
shards.add(new JedisShardInfo("192.168.29.112", 6379));
// 定义集群连接池
ShardedJedisPool shardedJedisPool = new ShardedJedisPool(poolConfig, shards);
ShardedJedis shardedJedis = null;
try {
// 从连接池中获取到jedis分片对象
shardedJedis = shardedJedisPool.getResource();
// for (int i = 0; i < 100; i++) {
// shardedJedis.set("key_" + i, "value_" + i);
// }
System.out.println(shardedJedis.get("key_49"));
System.out.println(shardedJedis.get("key_7"));
} catch (Exception e) {
e.printStackTrace();
} finally {
if (null != shardedJedis) {
// 关闭,检测连接是否有效,有效则放回到连接池中,无效则重置状态
shardedJedis.close();
}
}
// 关闭连接池
shardedJedisPool.close();
}
} 使用JedisCluster操作redis集群
private static void init() throws Exception {
// 获取REDISS配置
Properties pro = SystemResourceUtil.getPropertisByName("redis.properties");
// 初始化REDIS服务节点
Set jedisClusterNodes = initJedisClusterNodes(pro);
// 池初始化
GenericObjectPoolConfig poolConfig = initGenericObjectPoolConfig(pro);
jedisCluster = new JedisCluster(jedisClusterNodes, poolConfig);
}
//初始化redis的服务节点
private static Set initJedisClusterNodes(Properties pro) {
String addressStr = pro.getProperty("redis.address");
Set jedisClusterNodes = new HashSet();
if (StringUtils.isNoneBlank(addressStr)) {
// redis密码
String pw = PasswordUtil.getPasswordByKey("redis.password");
// 解析服务地址格式10.31.225.212:5762,10.31.225.213:5763,10.31.225.212:5764
String[] addresses = addressStr.split(",");
for (String address : addresses) {
String[] s = address.split(":");
jedisClusterNodes.add(new HostAndPort(s[0], Integer.parseInt(s[1]), pw));
}
} else {
logger.error(" redis server address is null,check the redis.properties");
}
return jedisClusterNodes;
}
//初始化GenericObjectPool
private static GenericObjectPoolConfig initGenericObjectPoolConfig(Properties pro) {
String maxTotal = pro.getProperty("redis.maxTotal");
String maxIdle = pro.getProperty("redis.maxidle");
String maxWait = pro.getProperty("redis.maxwait");
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
if (StringUtils.isBlank(maxTotal) || StringUtils.isBlank(maxIdle) || StringUtils.isBlank(maxWait)) {
logger.warn("redis.properties is not config!");
} else {
poolConfig.setMaxTotal(Integer.parseInt(maxTotal));
poolConfig.setMaxIdle(Integer.parseInt(maxIdle));
poolConfig.setMaxWaitMillis(Long.parseLong(maxWait));
poolConfig.setTestOnBorrow(Boolean.parseBoolean(pro.getProperty("redis.testonborrow")));
poolConfig.setTestOnReturn(Boolean.parseBoolean(pro.getProperty("redis.testonreturn")));
}
return poolConfig;
} redis.properties如下
#REDIS服务地址
redis.address=10.20.131.117:4772,10.20.131.118:4773,10.20.131.117:4774
#最大的实例个数
redis.maxtotal=1024
#保存idle状态对象的最大个数
redis.maxidle=200
#池内没有对象最大等待时间
redis.maxwait=1000
#当调用borrow Object方法时,是否进行有效性检查
redis.testonborrow=false
#当调用return Object方法时,是否进行有效性检查
redis.testonreturn=false 利用jedis封装操作redis的工具类
d . spring整合jedis,使用的时候注入 ShardedJedisPool,通过ShardJedisPool来获取.getResource()来获取ShardJedis操作redis
e. 使用spring整合redis的spring-data-redis,是对jedis的封装,集成jedis的一些命令和方法,与spring整合,通过redisTemplate来操作!
redis的过期策略以及内存淘汰机制
三种过期策略
定时删除
含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
优点:保证内存被尽快释放
缺点:
若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
没人用
惰性删除
含义:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
定期删除
含义:每隔一段时间执行一次删除过期key操作
优点:
通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点
定期删除过期key--处理"惰性删除"的缺点
缺点
在内存友好方面,不如"定时删除"
在CPU时间友好方面,不如"惰性删除"
难点
合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
Redis采用的是惰性删除+定期删除
惰性删除流程
在进行get或setnx等操作时,先检查key是否过期,
若过期,删除key,然后执行相应操作;
若没过期,直接执行相应操作
定期删除流程(简单而言,对指定个数个库的每一个库随机删除小于等于指定个数个过期key)
遍历每个数据库(就是redis.conf中配置的"database"数量,默认为16)
检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次,循环体时下边的描述)
如果当前库中没有一个key设置了过期时间,直接执行下一个库的遍历
随机获取一个设置了过期时间的key,检查该key是否过期,如果过期,删除key
判断定期删除操作是否已经达到指定时长,若已经达到,直接退出定期删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
在redis.conf中有一行配置
# maxmemory-policy volatile-lru
该配置就是配内存淘汰策略的
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
此外:附加redis资料查询地址:
http://www.redis.cn/commands.html
http://www.redis.cn/topics/distlock(官方分布式锁的讲解)
http://blog.csdn.net/liubenlong007/article/details/53782934(其他redis讲解的博客)