C++与T R C V(持续更新)
文章目录
- C++ 基础
- Vector向量
- int <-> string
- 手动编译
- vscode 配置并调试opencv代码
- 单例
- 图像的基础操作(read, write, attributes, pixels...)
- 图像质量评估算法
- 1、背景介绍
- 2、数据集
- 3、评价指标
- 4、常用算法
- 5、相关论文
C++ 基础
Vector向量
vector
int <-> string
int x1 = stoi(l4.c_str()); //c_str()返回的是一个临时指针,不能对其进行操作。
string s = tostring(x1);
手动编译
先准备好自己要编译的文件:main.cpp
gcc c语言,g++为c++.
在终端输入:
g++ main.cpp -o main.o 编译出可执行文件
./main.o 执行程序
最后 ,可以编写MakeFile文件:
可参考:https://www.cnblogs.com/wang_yb/p/3990952.html
vscode 配置并调试opencv代码
tasks可以被用来做编译,而launch用来执行编译好的文件。
1 先下载并编译C++ opencv
2 打开vscode ,写入自己要调试的程序:
#include 3 配置launch.json
主要关注三个参数:
1)program
这一参数指明debug时运行哪个程序,“program”: “ w o r k s p a c e F o l d e r / {workspaceFolder}/ workspaceFolder/{fileBasenameNoExtension}.o”,表明是要运行当前目录中与被编译文件同名的.o后缀文件
2)MIMode
这一参数指明要使用的debug工具,Ubuntu环境下当然是gdb。win10环境下是MinGW,MacOS环境下是lldb。
3)miDebuggerPath
这一句也很重要。在默认生成的launch.json文件中并没有这一参数的设置语句,但这一句却是最重要的,因为有了这一句,vscode在编译运行cpp文件时才能找到gdb程序。
一般情况下,gdb是被安装在/usr/bin/gdb目录下,所以这一句为:“miDebuggerPath”: “/usr/bin/gdb”,
当然这里的理解都很粗浅,要详细了解launch.json文件,还是到扩展的官网上去看看。
设置好launch.json文件后,按道理已经可以试着运行cpp文件了,当然你一试vscode就会提示你不存在jiayiju${fileBasenameNoExtension}.o,因为我们还没有编译呢。
所以,要在launch.json中加一句"preLaunchTask": “g++”,,指定一个运行前任务,编译我们写好的cpp文件。
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "(gdb) Launch",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/${fileBasenameNoExtension}.o",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": true,
"MIMode": "gdb",
"preLaunchTask": "build",
"miDebuggerPath": "/usr/bin/gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
]
}
]
}
4 配置task.json
vscode使用快捷键 Ctrl + Shift + B 开启自动编译。
一般情况下,在上一步运行失败之后,会直接提示你设置task.json文件,如果没有,你也可以点击Ctrl+Shift+P"调出命令面板,然后搜索Task,点击第一个.
“label”: “build"表示以下是名为build的任务配置
“command”: “g++”,表示调用的编译器是g++
args表示command的命令,其中“-I”表示包含目录,”-L"表示库目录路径,"-l"表示库文件,注意:/usr/local/lib目录下的库文件名为libopencv_core.so,但是我们只需要写opencv_core就行了。添加好自己需要的库文件,然后调试&运行opencv_test.cpp就可以了。
${workspaceRoot} VS Code当前打开的文件夹
${file} 当前打开的文件
${relativeFile} 相对于workspaceRoot的相对路径
${fileBasename} 当前打开文件的文件名
${fileDirname} 所在的文件夹,是绝对路径
${fileExtname} 当前打开文件的拓展名,如.json
${cwd} the task runner’s current working directory on startup
{
// See https://go.microsoft.com/fwlink/?LinkId=733558
// for the documentation about the tasks.json format
"version": "2.0.0",
"tasks": [
{
"label": "build",
"type": "shell",
"command": "g++",
"args": ["-g", "hello_world.cpp","-o","${fileBasenameNoExtension}.out",
"-I", "/usr/local/include",
"-I", "/usr/local/include/opencv",
"-I", "/usr/local/include/opencv2",
"-L", "/usr/local/lib",
"-l", "opencv_core",
"-l", "opencv_imgproc",
"-l", "opencv_imgcodecs",
"-l", "opencv_video",
"-l", "opencv_ml",
"-l", "opencv_highgui",
"-l", "opencv_objdetect",
"-l", "opencv_flann",
"-l", "opencv_imgcodecs",
"-l", "opencv_photo",
"-l", "opencv_videoio"
]
}
]
}
5 也可以不用json的方法 ,直接配置MakeFile
CROSS =
CC = $(CROSS)gcc
CXX = $(CROSS)g++
DEBUG = -g -O2
CFLAGS = $(DEBUG) -Wall -c
RM = rm -rf
SRCS = $(wildcard ./*.cpp)
OBJS = $(patsubst %.cpp, %.o, $(SRCS))
HEADER_PATH = -I/usr/local/include/ -I/usr/local/opencv -I/usr/local/opencv2
LIB_PATH = -L/usr/local/lib
LIBS = -lopencv_core -lopencv_highgui -lopencv_imgcodecs
VERSION = 1.0
TARGET = test_$(VERSION)
$(TARGET) : $(OBJS)
$(CXX) $^ -o $@ $(LIB_PATH) $(LIBS)
$(OBJS):%.o : %.cpp
$(CXX) $(CFLAGS) $< -o $@ $(HEADER_PATH)
.PHONY: clean
clean :
-$(RM) $(TARGET) *.o
wildcard通配符,wildcard把指定目录./下的所有后缀是cpp的文件全部展开;获取工作目录下的所有的.cpp文件列表
patsubst替换通配符,patsubst把KaTeX parse error: Expected 'EOF', got '#' at position 29: …缀是.cpp的全部替换成.o #̲@是自动变量,指目标的名字TARGET
#KaTeX parse error: Expected 'EOF', got '#' at position 19: …所有前置条件,之间以空格分隔 #̲<指代第一个前置条件
参考:https://blog.csdn.net/qq849635649/article/details/51564338
https://blog.csdn.net/u012435142/article/details/82952302
单例
单例模式,可以说设计模式中最常应用的一种模式了,据说也是面试官最喜欢的题目。但是如果没有学过设计模式的人,可能不会想到要去应用单例模式,面对单例模式适用的情况,可能会优先考虑使用全局或者静态变量的方式,这样比较简单,也是没学过设计模式的人所能想到的最简单的方式了。
一般情况下,我们建立的一些类是属于工具性质的,基本不用存储太多的跟自身有关的数据,在这种情况下,每次都去new一个对象,即增加了开销,也使得代码更加臃肿。其实,我们只需要一个实例对象就可以。如果采用全局或者静态变量的方式,会影响封装性,难以保证别的代码不会对全局变量造成影响。
考虑到这些需要,我们将默认的构造函数声明为私有的,这样就不会被外部所new了,甚至可以将析构函数也声明为私有的,这样就只有自己能够删除自己了。在Java和C#这样纯的面向对象的语言中,单例模式非常好实现,直接就可以在静态区初始化instance,然后通过getInstance返回,这种就被称为饿汉式单例类。也有些写法是在getInstance中new instance然后返回,这种就被称为懒汉式单例类,但这涉及到第一次getInstance的一个判断问题。
下面的我在定QT是传输深度学习标签值时用的代码:
<single.h>
#ifndef SINGLE_H
#define SINGLE_H
#include *********************************************************************
#include "single.h"
#include "extract_file.h"
Single* Single::m_instance = nullptr;
QMutex Single::m_mutex;
Single::Single()
{
}
Single::~Single()
{
if(m_instance)
{
m_mutex.unlock();
delete m_instance;
}
}
Single *Single::GetInstance()
{
if (m_instance == nullptr)
{
QMutexLocker locker(&m_mutex);
if (m_instance == nullptr)
{
m_instance = new Single();
}
}
return m_instance;
}
QList<QVariant> Single::Get_file_data()
{
QString label_path="E:/datasets/VOCdevkit/VOC2011_2012/Annotations/2011_000003.xml";
Extract_file *extracter= new Extract_file();
extracter->do_run(label_path);
}
图像的基础操作(read, write, attributes, pixels…)
#include 图像质量评估算法
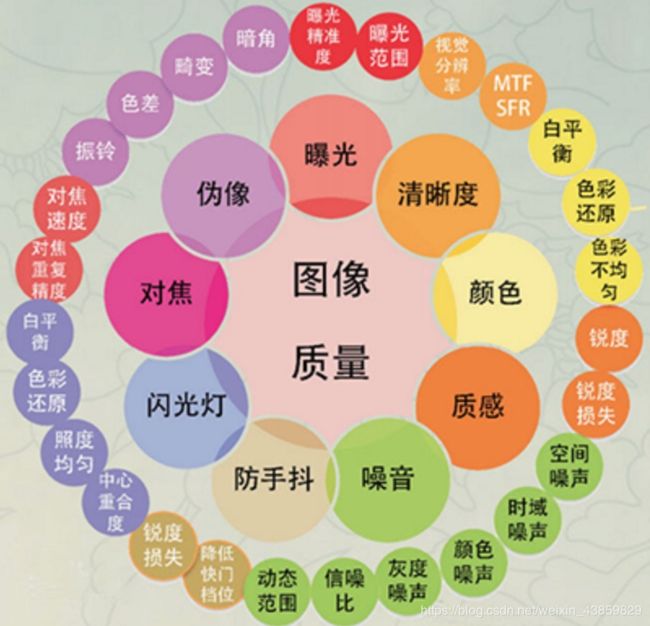
1、背景介绍
相关论文学汇总
在过去的几十年里,由于质量评估(Quality Assessment,QA)在许多领域有其广泛的实用性,比如图像压缩、视频编解码、视频监控等,并且对高效、可靠质量评估的需求日益增加。质量评估可分为图像质量评估(Image Quality Assessment, IQA)和视频质量评估(Video Quality Assessment, VQA)。
f ( x ) { 主 观 评 价 客 观 评 价 { 仿 生 学 的 客 观 质 量 评 价 : 引 入 H V S 特 性 工 程 学 的 客 观 质 量 评 价 f(x)\left\{\begin{matrix} 主观评价 \\ 客观评价\left\{\begin{aligned} 仿生学的客观质量评价:引入HVS特性\\ 工程学的客观质量评价 \end{aligned} \right. \end{matrix} \right. f(x)⎩⎪⎨⎪⎧主观评价客观评价{仿生学的客观质量评价:引入HVS特性工程学的客观质量评价
IQA按照原始参考图像提供信息的多少一般分成3类:全参考(Full Reference-IQA, FR-IQA)、半参考(Reduced Reference-IQA, RR-IQA)和无参考(No Reference-IQA, NR-IQA), 无参考也叫盲参考(Blind IQA, BIQA)。
仿生学法中有许多系统性缺陷制约着该类方法进一步发展,其根本原因是绝大多数心理物理学实验采样简单的视觉刺激来研究HVS机理,其结果并不能完整的表达高度复杂的视觉感知和处理过程。
工程学方法只考虑HVS的输入/输出关系,通过‘黑盒子’理论从整体功能上对HVS建模。相比仿生学方法,工程学方法计算复杂度低并能获得更好的评价准确性。
2、数据集
可参考 :https://blog.csdn.net/lanmengyiyu/article/details/53332680

3、评价指标
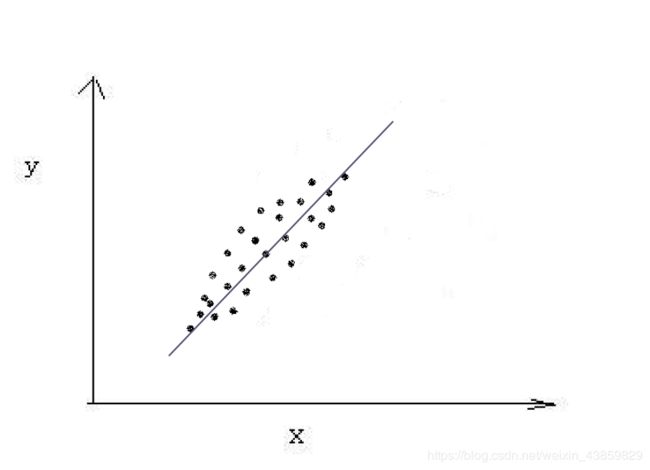
例如Y=a*X+b。但是当其相关系数的绝对值小于1时,就不会有这么明确的函数关系。此时的相关度较小。下图是两个变量相关的示例,图中的每一点是变量X,Y的一对取值。可以看出这两个变量近似于线性相关,其相关系数接近于1。
PLCC/LCC:
常见的2种评估指标是线性相关系数(Linear Correlation Coefficient, LCC)。LCC也叫Pearson相关系数(PLCC)
P L C C = C O V ( X , Y ) δ X δ Y PLCC=\frac{COV(X,Y)} {\delta_X\delta_Y} PLCC=δXδYCOV(X,Y)
s r o c c = ∑ i = 1 n ( u i − u ˉ ) ( v i − v ˉ ) ∑ i = 1 n ( u i − u ˉ ) 2 ∑ i = 1 n ( v i − v ˉ ) srocc=\frac{\sum_{i=1}^n (u_i-\bar u)(v_i-\bar v)}{\sqrt {\sum_{i=1}^n (u_i- \bar u)^2 \sum_{i=1}^n(v_i- \bar v)}} srocc=∑i=1n(ui−uˉ)2∑i=1n(vi−vˉ)∑i=1n(ui−uˉ)(vi−vˉ)

其中N表示失真图像数, y i 、 y ^ i y_i、\hat y_i yi、y^i分别表示第i幅图像真实值和测试分数, y i − 、 y ˉ i − y_i^-、\bar y_i ^- yi−、yˉi−分别表示真实平均值和预测平均值。
SROCC:
和Spearman秩相关系数(Spearman’s Rank Order Correlation Coefficient, SROCC)
SROCC衡量算法预测的单调性,计算公式为:
s r o c c = 1 − 6 ∑ i = 1 n d i 2 n ( n 2 − 1 ) , d i 为 图 片 在 整 个 数 据 集 上 的 排 序 位 置 差 ( d x − d y ) srocc=1-\frac{6\sum_{i=1}^n d_i^2}{n\left(n^2-1\right)} ,d_i为图片在整个数据集上的排序位置差(d_x-d_y) srocc=1−n(n2−1)6∑i=1ndi2,di为图片在整个数据集上的排序位置差(dx−dy)

其中 v i 、 p i v_i 、p_i vi、pi分别表示 y i 、 y ^ i y_i、\hat y_i yi、y^i在真实值和预测值序列中的排序位置。
KROCC:
KROCC的全称是the Kendall rank-order correlation coefficient,又简称为Kendall’s tau。和srocc一样这里我也是通过例子计算来解释它。在这里我还是用srocc中的那个例子。
在这里我先讲一些基本的概念。假设我们现在需要评价两个变量X和Y的相关性,(x1,y1)(x1,y1) ,(x2,y2)(x2,y2),……., (xn,yn)(xn,yn)是变量X和Y的一些数据对,(xi,yi)(xi,yi)可以看做是上面例子中第i个学生的数学成绩和英语成绩组成的数据对。现在我们从这n个数据对中任意选两个数据对(xi,yi)(xi,yi)和(xj,yj)(xj,yj)形成[(xi,yi),(xj,yj)][(xi,yi),(xj,yj)],其中i!=j且[(xi,yi),(xj,yj)][(xi,yi),(xj,yj)]和[(xj,yj),(xi,yi)][(xj,yj),(xi,yi)],这样的对子一种有N=n(n+1)2N=n(n+1)2种。对于任意的[(xi,yi),(xj,yj)][(xi,yi),(xj,yj)],若xi>xjxi>xj且yi>yjyi>yj或者xi
RMSE:
很简单不多说。
M S E = 1 N ∑ i = 1 N ( x i − y i ) 2 MSE=\frac{1}{N}\sum_{i=1}^{N}(x_i-y_i)^2 MSE=N1i=1∑N(xi−yi)2
R M S E = ∑ i = 1 n ( x i − y i ) 2 n RMSE=\sqrt \frac{\sum_{i=1}^n{(x_i-y_i)^2}}{n} RMSE=n∑i=1n(xi−yi)2
参考:https://zhuanlan.zhihu.com/p/32553977 ; https://blog.csdn.net/caoleiwe/article/details/49045633
4、常用算法
传统算法:
一些常用的算法代码可以参考这儿
峰 值 信 噪 比 ( P S N R ) = 10 ∗ l o g 10 ( M A X 2 M S E ) 均 方 误 差 ( M S E ) = 1 M N ∑ i = 0 M − 1 ∑ j = 0 N − 1 [ X ( i , j ) − Y ( i , j ) ] 2 峰值信噪比(PSNR)=10*log_{10}(\frac{MAX^2}{MSE}) \\ 均方误差(MSE) = \frac{1}{MN}\sum_{i=0}^{M-1}\sum_{j=0}^{N-1}[X(i,j)-Y(i,j)]^2 峰值信噪比(PSNR)=10∗log10(MSEMAX2)均方误差(MSE)=MN1i=0∑M−1j=0∑N−1[X(i,j)−Y(i,j)]2
其中X 、Y 表示两个MxN的单色图像。MAX表示图像点颜色的最大值,如果每个采样点用 8 位表示,那么就是 255。对于彩色图像来说PSNR的定义类似,只是MSE是所有方差之和除以图像尺寸再除以通道数 3。
结构相似度(Structure similarity Index, SSIM):
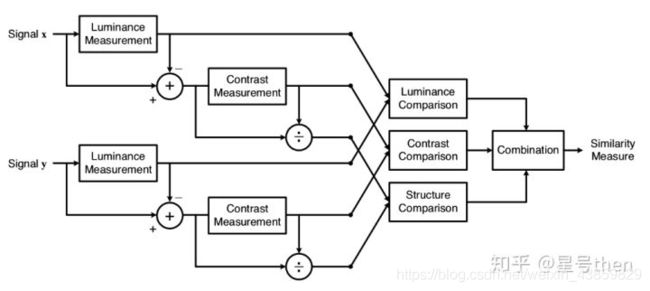
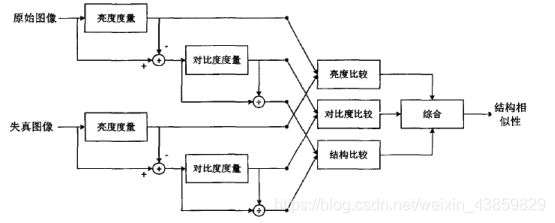
公式:(先求均值、方差、协方差,再求亮度因子、对比度因子、结构相似因子,最后将三个因子乘在一起)
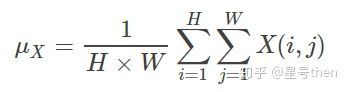






当C3 = C2/2时,SSIM可简化成:
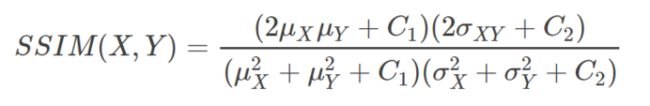
此外可以求其平均值,即MSSIM:

优点:通过感知结构信息来评价失真更接近人眼
缺点:人类视觉系统很是高度非线性的,仅仅比较两个信号结构的相似性是不够的,还有很大的空间未被挖掘。

PSNR是图像、视频处理领域应用最广的性能量化方法,计算复杂度小,实现速度快,已经应用在视频编码标准H.264、H.265中。尽管PSNR具有上述特点,但是局限性很明显,受像素点的影响比较大,与主观评价一致性比较低,没有考虑人类视觉系统(Human Visual System, HVS)的一些重要的生理、心理、物理学特征。基于HVS,提出了误差灵敏度分析和结构相似度分析(Structural SIMilarity Index, SSIM)[1]的评价方法。结构相似性假定HVS高度适应于从场景中提取结构信息,试图模拟图像的结构信息,实验表明场景中物体的结构与局部亮度和对比度无关,因此,为了提取结构信息,我们应该分离照明效果。后来又发展出多尺度的结构相似性(Multi-Scale Structural SIMilarity Index, MS-SSIM)[1]和信息量加权的结构相似性(Information Content Weighted Structural Similarity Index, IW-SSIM)[13],在多尺度方法中,将不同分辨率和观察条件下的图像细节结合到质量评估算法中。 VIF[12]算法使用高斯尺度混合(Gaussian Scale Mixtures, GSMs)在小波域对自然图像进行建模,由源模型,失真模型和HVS模型三部分组成。MAD[8]算法假定HVS在判断图像质量时采用不同的策略,即使用局部亮度、对比度掩蔽和空间频率分量的局部统计量的变化来寻找失真。FSIM[1]算法强调人类视觉系统理解图像主要根据图像低级特征,选择相位一致性(Phase Congruency, PC)和图像梯度幅度(Gradient Magnitude, GM)来计算图像质量。后又加入颜色特征并用相位一致性信息做加权平均,发展出FSIMc[1]算法。VSI[15]算法把FSIMc中的相位一致性特征换成了显著图,保留FSIMc中的梯度和颜色信息,提高了效果。GMSD[14]只用梯度作为特征,采用标准差pooling代替以前的均值pooling,达到了较好的效果。总体上来说,FR-IQA算法性能和速度都在提高,准确率也达到了新高度,如下表:
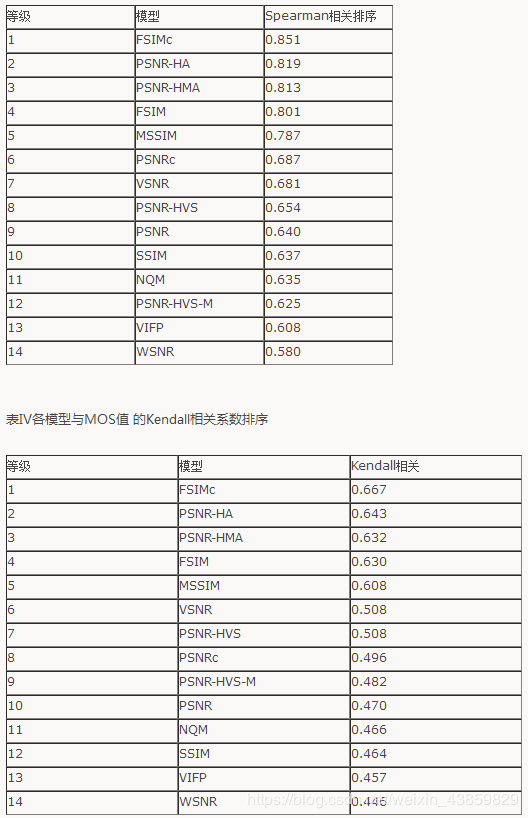


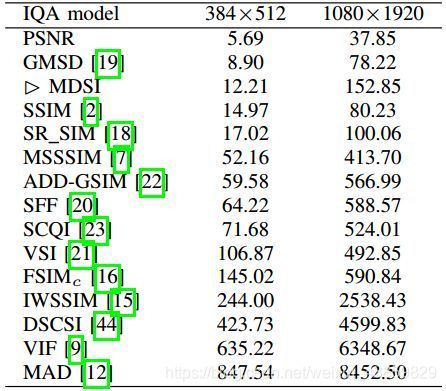
5、相关论文
参考相关论文:
Image数据库:
LIVE CSIQ TID BID CID CLIVE KONIQ10K AVA…
Analysis of Public Image and Video Databases for Quality Assessment. 2012 JSTSP
Video数据库:
Study of Subjective and Objective Quality Assessment of Video. 2010 IEEE TIP
CVD2014 A Database for Evaluating No-reference Video Quality Assessment Algorithms. 2016 IEEE TIP
The Konstanz Natural Video Database. 2017 QoMEX
Waterloo Exploration Database New Challenges for Image Quality Assessment Models. 2017 IEEE TIP
Large Scale Study of Perceptual Video Quality. 2018 IEEE CVPR
Image Quality Assessment:
1. 传统方法
【SSIM】【FR】Image Quality Assessment From Error Visibility to Structural Similarity. 2004 IEEE TIP
【MS-SSIM】【FR】Multi-scale Structural Similarity for Image Quality Assessment. 2003
【FSIM】【FR】FSIM A Feature Similarity Index for Image Quality Assessment. 2011 IEEE TIP
【IW-SSIM】【FR】Information Content Weighting for Perceptual Image Quality Assessment. 2011 IEEE TIP
【GSIM】【FR】Image Quality Assessment based on Gradient Similarity. 2012 IEEE TIP
【RFSIM】【FR】RFSIM A Feature based Image Quality Assessment Metric Using RIESZ Transforms. 2010 IEEE ICIP
【SRSIM】【FR】SR-SIM A Fast and High Performance IQA Index based on Spectral Residual. 2012 IEEE ICIP
【SPSIM】【FR】SPSIM A Superpixel-based Similarity Index for Full-reference Image Quality Assessment. 2018 IEEE TIP
【MDSI】Mean Deviation Similarity Index Efficient and Reliable Full-reference Image Quality Evaluator. 2016 IEEE Access
【GMSD】【FR】Gradient Magnitude Similarity Deviation: A Highly Efficient Perceptual Image Quality Index. 2014 IEEE TIP
【VSI】【FR】 VSI A Visual Saliency-induced Index for Perceptual Image Quality Assessment. 2014 IEEE TIP
【VIF】【FR】Image Information and Visual Quality. 2006 IEEE TIP
【IFC】【FR】An Information Fidelity Criterion for Image Quality Assessment Using Natural Scene Statistics. 2005 IEEE TIP
【VSNR】【FR】VSNR A Wavelet-based Visual Signal-to-Noise Ratio for Natural Images. 2007 IEEE TIP
【MAD】【FR】Most Apparent Distortion Full-reference Image Quality Assessment and the Role of Strategy. 2010 JEI
【QAC】【FR】Learning without Human Scores for Blind Image Quality Assessment. 2013 IEEE CVPR
【RRED】【RR】RRED Indices: Reduced Reference Entropic Differencing for Image Quality Assessment. 2012 IEEE TIP
【NQM】【NR】Image Quality Assessment based on a Degradation Model. 2000 IEEE TIP
【NIQE】【NR】Making a “Completely Blind” Image Quality Analyzer. 2013 IEEE SPL
【BRISQUE】【NR】No-reference Image Quality Assessment in the Spatial Domain. 2012 IEEE TIP
【CORNIA】【NR】Unsupervised Feature Learning Framework for No-reference Image Quality Assessment. 2012 IEEE CVPR
【ILNIQE】【NR】A Feature-enriched Completely Blind Image Quality Evaluator. 2015 IEEE TIP
【BLISS】Beyond Human Opinion Scores: Blind Image Quality Assessment based on Synthetic Scores. 2014 IEEE CVPR
【FRIQUEE】Perceptual Quality Prediction on Authentically Distorted Images Using a Bag of Features Approach. 2016 JOV
A Statistical Evaluation of Recent Full Reference Image Quality Assessment Algorithms. 2006 IEEE TIP
Learning a Blind Measure of Perceptual Image Quality. 2011 IEEE CVPR
A Perceptually Weighted Rank Correlation Indicator for Objective Image Quality Assessment. 2018 IEEE TIP
Predicting Encoded Picture Quality in Two Steps in a Better Way. 2018 Arxiv
Stereoscopic Image Quality Assessment by Deep Convolutional Neural Network. 2018 JVCIR Yan
Learning a No-reference Quality Predictor of Stereoscopic Images by Visual Binocular Properties. 2018 peprint Yan
Quality Assessment of Asymmetric Stereo Pair Formed from Decoded and Synthesized Views. 2012 QoMEX
A Detail-based Method for Linear Full Reference Image Quality Prediction. TIP IEEE 2018
2. deep-based
【BIQI】A Two-step Framework for Constructing Blind Image Quality Indices. 2010 IEEE SPL
【CNN】Convolutional Neural Networks for No-reference Image Quality Assessment. 2014 IEEE CVPR
【GRNN】Blind Image Quality Assessment Using a General Regression Neural Network. 2011 IEEE TNN
【DLIQA】Blind Image Quality Assessment via Deep Learning. 2015 IEEE TNN
【deepiqa】 A Deep Neural Network for Image Quality Assessment. 2016 ICIP
【DeepQA】Deep Learning of Human Visual Sensitivity in Image Quality Assessment Framework. 2017 IEEE CVPR
【deepIQA】Deep Neural Networks for No-reference and Full-reference Image Quality Assessment. 2017 IEEE TIP
【dipIQ】Blind Image Quality Assessment by Learning-to-rank Discriminable Image Pairs. 2017 IEEE TIP kede
【MEON】End-to-end Blind Image Quality Assessment Using Deep Neural Networks. 2018 IEEE TIP kede
Group MAD Competition A New Methodology to Compare Objective Image Quality Models. 2016 IEEE CVPR/2019 PAMI kede
Deep Bilinear Pooling for Blind Image Quality Assessment. 2019 IEEE CSVT kede
NIMA Neural Image Assessment. 2018 IEEE TIP
Learning to Rank for Blind Image Quality Assessment. 2015 IEEE TNN
【BPSQM】Blind Predicting Similar Quality Map for Image Quality Assessment. 2018 IEEE CVPR
【BIECON】Full Deep Blind Image Quality Predictor. 2017 JSTSP
【DIQA】Deep CNN-based Blind Image Quality Predictor. 2018 IEEE TNN
Deep Convolutional Neural Models for Picture-quality Prediction. 2017 IEEE Signal Processing Magazine
Blind Image Quality Assessment via Vector Regression and Object Oriented Pooling. 2017 IEEE TMM
Image Quality Assessment Guided Deep Neural Networks Training. 2017 Arxiv
A Probabilistic Quality Representation Approach to Deep Blind Image Quality Prediction. 2017 Arxiv
【MGDNN】Difference of Gaussian Statistical Features based Blind Image Quality Assessment A Deep Learning Approach. 2015 IEEE ICIP
Learning Deep Vector Regression Model for No-reference Image Quality Assessment. 2017 IEEE ICASSP
An Accurate Deep Convolutional Neural Networks Model for No-reference Image Quality Assessment. 2017 IEEE ICME
Blind Proposal Quality Assessment via Deep Objectness Representation and Local Linear Regression. 2017 IEEE ICME
RankIQA Learning from Rankings for No-reference Image Quality Assessment. 2017 IEEE ICCV
PieAPP: Perceptual Image-error Assessment through Pairwise Preference. 2018 IEEE CVPR
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. 2018 IEEE CVPR
Hallucinated-IQA No-reference Image Quality Assessment via Adversarial Learning. 2018 IEEE CVPR
An Attention-driven Approach of No-reference Image Quality Assessment. 2017 Arxiv
Deep Multi-patch Aggregation Network for Image Style, Aesthetics and Quality Estimation. 2015 IEEE ICCV
SOM: Semantic Obviousness Metric for Image Quality Assessment. 2015 IEEE CVPR
Deep HVS-IQA Net: Human Visual System Inspired Deep Image Quality Assessment Networks. Arxiv
Learning to Compare Image Patches via Convolutional Neural Networks. 2015 IEEE CVPR
PATCH-IQ A Patch based Learning Framework for Blind Image Quality Assessment. 2017 Information Science
Generating Image Distortion Maps Using Convolutional Autoencoders with Application to No Reference Image Quality Assessment. 2018 IEEE SPL
VeNICE: A Very Deep Neural Network Approach to No-reference Image Assessment.
Blind Deep S3D Image Quality Evaluation via Local to Global Feature Aggregation. 2017 IEEE TIP
On the Use of Deep Learning for Blind Image Quality Assessment.
Pairwise Comparison and Rank Learning for Image Quality Assessment. 2016 Displays
Learning to Blindly Assess Image Quality in the Laboratory and Wild. 2019 preprint
Video Quality Assessment:
1. 传统方法
【FR】A Perception-based Hybrid Model for Video Quality Assessment. 2016 IEEE CSVT
【FR】An Optical Flow-based Full Reference Video Quality Assessment Algorithm. 2016 IEEE TIP
【FR】Objective Video Quality Assessment based on Perceptually Weighted Mean Squared Error. 2017 IEEE CSVT
【FR】Spatiotemporal Feature Integration and Model Fusion for Full Reference Video Quality Assessment. 2018 IEEE CSVT
【3D-SSIM】【FR】3D-SSIM for Video Quality Assessment. 2012 IEEE ICIP
【MOVIE】【FR】Motion Tuned Spatio-temporal Quality Assessment of Natural Videos. 2010 IEEE TIP
【STMAD】【FR】A Spatiotemporal Most-apparent-distortion Model for Video Quality Assessment. 2011 IEEE ICIP
【V-SSIM】【FR】Video Quality Assessment based on Structural Distortion Measurement. 2004 SPIC
【VQM】【RR】A New Standardized Method for Objectively Measuring Video Quality. 2004 IEEE TOB
【STRRED】【RR】Video Quality Assessment by Reduced Reference Spatio-temporal Entropic Differencing. 2013 IEEE CSVT
【VIIDEO】【NR】A Completely Blind Video Integrity Oracle. 2016 IEEE TIP
【BLIINDS】【NR】Blind Prediction of Natural Video Quality. 2014 IEEE TIP
【V-CORNIA】【NR】No-reference Video Quality Assessment via Feature Learning. 2015 IEEE ICIP
Spatiotemporal Statistics for Video Quality Assessment. 2016 IEEE TIP
Spatiotemporal Feature Combination Model for No-reference Video Quality Assessment. 2018 QoMEX
Flicker Sensitive Motion Tuned Video Quality Assessment. 2016 SSIAI
Free-energy Principle Inspired Video Quality Metric and Its Use in Video Coding. 2016 IEEE TMM
Study of Saliency in Objective Video Quality Assessment. 2017 IEEE TIP
SpEED-QA: Spatial Efficient Entropic Differencing for Image and Video Quality. 2017 IEEE SPL
Video Quality Pooling Adaptive to Perceptual Distortion Severity. 2013 IEEE TIP
Detecting and Mapping Video Impairments. preprint
A Fast Stereo Video Quality Assessment Method based on Compression Distortion. preprint
2. deep-based
【V-MEON】End-to-End Blind Quality Assessment of Compressed Video Using Deep Neural Networks. 2018 ACM MM
No-reference Video Quality Assessment with 3D Shearlet Transform and Convolutional Neural Networks. 2016 IEEE CSVT
【DeepVQA】Deep Video Quality Assessor From Spatio-temporal Visual Sensitivity to A Convolutional Neural Aggregation Network. 2018 ECCV
Viewport-based CNN: A Multi-task Approach for Assessing 360 Video Quality. preprint
Related paper:
【NLPD】 Perceptually Optimized Image Rendering. 2017 arXiv
Learning Spatiotemporal Features with 3D Convolutional Networks. 2015 IEEE ICCV
Large-scale Video Classification with Convolutional Neural Networks. 2014 IEEE CVPR
3D Convolutional Neural Networks for Human Action Recognition. 2013 IEEE PAMI
Interpretable Convolutional Neural Networks. 2018 arXiv
Rethinking ImageNet Pre-training. 2018 ArXiv
Repr: Improved Training of Convolutional Filters.
UberNet: Training a Universal Convolutional Neural Network for Low-, Mid-, and High-level Vision using Diverse Datasets and Limited Memory. 2017 IEEE CVPR
Kervolutional Neural Networks. Arxiv
Network in Network. 2014 ICLR
Deformable Convolutional Networks. 2017 Arxiv
Deep Unsupervised Saliency Detection A Multiple Noisy Labeling Perspective. 2018 ArXiv
Learning without Forgetting. 2018 IEEE PAMI
Learning from Crowds. 2010 Machine Learning Research
Supervised Learning from Multiple Experts Whom to trust when everyone lies a bit. 2009 ICML
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? 2017 NIPS
Quantifying Uncertainties in Natural Language Processing Task. 2018 ArXiv
Objective Assessment of Multiresolution Image Fusion Algorithms for Context Enhancement in Night Vision A Comparative Study. 2012 IEEE PAMI
Geometry-consistent Adversarial Networks for One-sided Unsupervised Domain Mapping. 2018 ArXiv
Unsupervised Deep Embedding for Clustering Analysis. 2016 ICML
A New Three-step Search Algorithm for Block Motion Estimation. 1994 IEEE CSVT
Spatial Frequency, Phase, and the Contrast of Natural Images. 2002
Community-aware Retargeting by Probabilistic Encoding of Noise-tolerant Deep Features. preprint
参考:https://zhuanlan.zhihu.com/p/32553977;https://zhuanlan.zhihu.com/p/54539091