《精通正则表达式》第2章Java例子
Text-to-HTML转换例子(76页)
package zcw.com.lib_regex.master;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Created by zcw on 2019/4/28.
*/
public class P72 {
public static void main(String[] args) {
String filePath = "lib_regex\\text.txt";
StringBuilder builder = new StringBuilder();
try {
FileReader fileReader = new FileReader(filePath);
BufferedReader bufferedReader = new BufferedReader(fileReader);
// 从文件一行一行读取字符串到builder,每行以\n结束
String content;
while ((content = bufferedReader.readLine()) != null) {
builder.append(content + "\n");
}
// 关闭文件
fileReader.close();
bufferedReader.close();
}
catch (IOException e) {
System.err.println("Open " + filePath + "failed.\n" + e.getMessage());
System.exit(0);
}
transfer(builder.toString());
}
/**
* 把文本文件转换成html内容。
* @param content 需要转换的内容
*/
private static void transfer(String content) {
// 匹配主机号正则表达式
String hostName = "[-a-z0-9]+(\\.[-a-z0-9]+)*\\.(com|edu|info)";
/**
* 下标为[3]的正则表达式与书中不同;书中为"^\s*$",用此表达式,一直未能匹配成功,所以参考了书中81页内容,在每行开头插入
*/
String[] regex = {
"&", // 处理&字符
"<", // 处理<
">", // 处理>
"^([^\\n]+)",
"\\b(\\w[-.\\w]*@" + hostName + ")\\b",
"\\b(http://" + hostName + "\\b(/[-a-z0-9_:@&?=+,.!/~*'%$]*(?",
};
for(int i = 0; i < 3; i++) {
content = content.replaceAll(regex[i], replaceText[i]);
}
// 划分段落
Pattern pattern = Pattern.compile(regex[3], Pattern.MULTILINE);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
content = matcher.replaceAll(replaceText[3] + "$1");
}
// 把E-mail地址转换为连接形式
pattern = Pattern.compile(regex[4], Pattern.CASE_INSENSITIVE);
matcher = pattern.matcher(content);
while (matcher.find()) {
content = matcher.replaceAll("$1");
}
// 把HTTP URL地址转换为连接形式
pattern = Pattern.compile(regex[5], Pattern.CASE_INSENSITIVE);
matcher = pattern.matcher(content);
while (matcher.find()) {
content = matcher.replaceAll("$1");
}
System.out.println(content);
createHtml(content);
}
/**
* 创建html文件
* @param content
*/
private static void createHtml(String content) {
try {
// 创建文件
String filePath = "lib_regex\\test.html";
File file = new File(filePath);
if(!file.exists()) {
file.createNewFile();
}
FileWriter fileWriter = new FileWriter(file);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
String[] html = {
"\n",
"\n",
"
\n",
"\n",
"正则表达式测试 \n",
"\n",
"\n",
content,
"\n",
"\n",
};
// 把内容写入html文件
for(String string : html) {
bufferedWriter.write(string);
}
bufferedWriter.flush();
fileWriter.close();
bufferedWriter.close();
}
catch (IOException e) {
System.err.println("Create html file failed.\n" + e.getMessage());
return ;
}
}
}
text.txt文本内容如下:
This is a
sample file.
It has three lines.
That’s all
This is & test.
[email protected]
http://www.baidu.com
Copy It has three lines.
Copy That’sall
Copy [email protected]
Copy http://www.baidu.com
代码运行结果如图所示: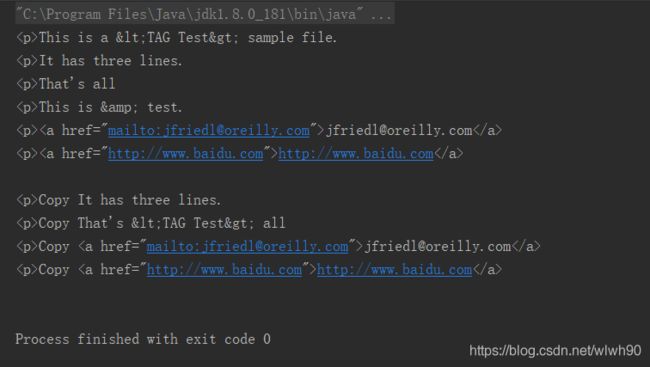
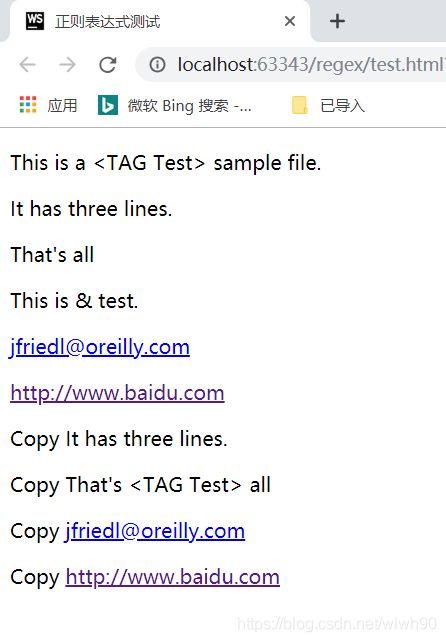
代码运行成功之后,会生成一个可直接在浏览器中打开的test.html页面,页面效果如图所示:
重复单词例子(77页)
package zcw.com.lib_regex.master;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.regex.Pattern;
/**
* Created by zcw on 2019/4/29.
* main方法传入参数:lib_regex\\text2.txt
*/
public class TwoWord {
public static void main(String[] args) {
Pattern regex1 = Pattern.compile(
"\\b" + // 单词边界
"([a-z]+)" + // 匹配单词
"((?:\\s|<[^>]+>)+)" + // 匹配空格或者
"(\\1\\b)", // \\1为反向引用,\\b为单词边界符
Pattern.CASE_INSENSITIVE);
/** \033[7m为控制台输出高亮起始符,\033[m为控制台高亮结束符
* $1用于引用捕获组
*/
String replace1 = "\033[7m$1\033[m$2\033[7m$3\033[m";
/** 去掉所有未标记的行,如果没有\e转义符,既为未标记的行。
* {@link Pattern#MULTILINE}处理多行,对于书中所讲m模式。
*/
Pattern regex2 = Pattern.compile("^(?:[^\\e]*\\n)+", Pattern.MULTILINE);
/** 匹配每一行的开头 */
Pattern regex3 = Pattern.compile("^([^\\n]+)", Pattern.MULTILINE);
// 对于命令行的每个参数进行如下处理
for(int i = 0; i < args.length; i++) {
try {
BufferedReader in = new BufferedReader(new FileReader(args[i]));
String text;
while ((text = Util.getPara(in)) != null) {
// 应用3条规则替换
text = regex1.matcher(text).replaceAll(replace1);
text = regex2.matcher(text).replaceAll("");
text = regex3.matcher(text).replaceAll(args[i] + ": $1");
// 显示结果
System.out.println(text);
}
in.close();
}
catch (IOException e) {
System.err.println("can't read [" + args[i] + "]: " + e.getMessage());
}
}
System.out.println("\033[7m一句用于测试高亮的话\033[m");
}
}
package zcw.com.lib_regex.master;
import java.io.BufferedReader;
import java.io.IOException;
/**
* Created by zcw on 2019/4/29.
*/
public class Util {
/**
* 用于读入“一段”文本
* @param in 字符流
* @return 返回一段文字,直到遇到空行
* @throws IOException
*/
public static String getPara(BufferedReader in) throws IOException {
StringBuffer buffer = new StringBuffer();
String line;
// 如果遇到空行,则结束
while ((line = in.readLine()) != null && (buffer.length() == 0 || line.length() != 0)) {
buffer.append(line + "\n");
}
return buffer.length() == 0 ? null : buffer.toString();
}
}
例子测试文本内容如下:
This is a sample file
File three lines pattern.
It has three three lines.
That’s all all
check for doubled words (such as thisthis thisthis), a common problem with
of this chapter. If you knew thethethethe specific doubled word to find (such
[email protected]
http://www.baidu.com
check for doubled words (such as thisthis thisthis), a common problem with
of this chapter. If you knew thethethethe specific doubled word to find (such
[email protected]
http://www.baidu.com
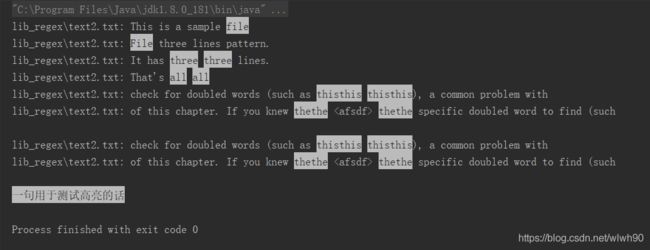
运行结果如图所示:
相关资料
控制台输出高亮相关资料:
- 命令行特殊显示效果\033和发声音\007
- “\033”(ESC)的用法-ANSI的Esc屏幕控制