python爬虫:爬取拉勾网北京数据挖掘职位并分析
前言
拉勾网爬取北京数据挖掘职位的职位信息,并以CSV格式保存至电脑,之后进行数据清洗,生成词云,进行描述统计,最终得出结论。
1. 用到的软件包
Python版本: Python3.5
requests:下载网页
math:向上取整
time:暂停进程
pandas:数据分析并保存为csv文件
matplotlib:画图
statsmodels:统计建模
wordcloud、scipy、jieba:生成中文词云
pylab:设置画图能显示中文
2. 解析网页
打开Chrome,在拉勾网搜索北京市的“数据挖掘”职位,使用检查功能查看网页源代码,发现拉勾网有反爬虫机制,职位信息并不在源代码里,而是保存在JSON的文件里,因此我们直接下载JSON,并使用字典方法直接读取数据
抓取网页时,需要加上头部信息,才能获取所需的数据。
import requests
import math
import time
import pandas as pd
'''从网页获取JSON,使用POST请求,加上头部信息'''
def get_json(url,num): #
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host': 'www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput=',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
my_data = {
'first': 'true',
'pn': num,
'kd': '数据挖掘'
}
res = requests.post(url=url,headers = headers,data = my_data)
res.encoding = "utf-8"
page = res.json()
return page
在搜索结果的第一页,我们可以从JSON里读取总职位数,按照每页15个职位,获得要爬取的页数。再使用循环按页爬取,将职位信息汇总,输出为CSV格式
抓取结果如图:
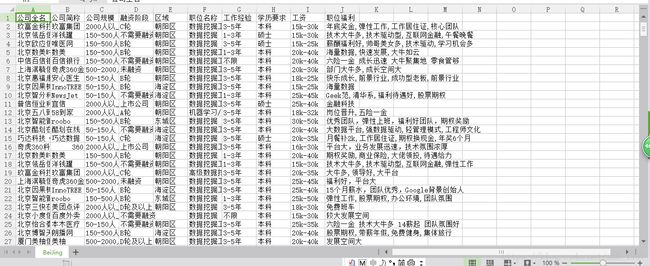
3. 数据清洗
数据清洗占数据分析工作量的大头。在拉勾网搜索北京市的“数据挖掘”职位,结果得到426个职位。查看职位名称时,发现有24个实习岗位。由于我们研究的是全职岗位,所以先将实习岗位剔除。由于工作经验和工资都是字符串形式的区间,我们先用正则表达式提取数值,输出列表形式。工作经验取均值,工资取区间的四分位数值,比较接近现实。
print('数据分析师工资描述:\n{}'.format(df['月工资'].describe()))

4. 词云
我们将职位福利这一列的数据汇总,生成一个字符串,按照词频生成词云实现python可视化。以下是原图和词云的对比图,可见团队在职位福利里出现的频率最高,平台、福利、发展空间、弹性、六险次之。

背景图用的兔子的图片
5. 描述统计
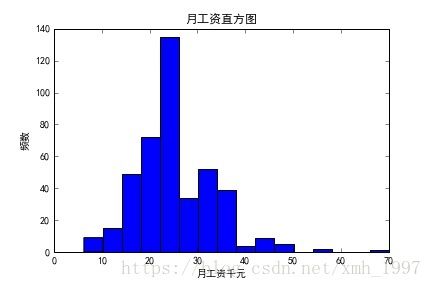
我们来看工资的分布,这对于求职来讲是重要的参考:
工资在15-25K的职位最多,在25-35K的职位其次。
我们再来看职位在各区的分布:
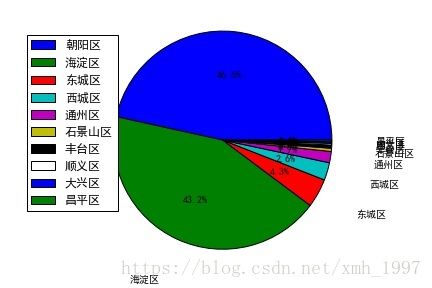
数据分析职位有43.2%在东城区,有45.6%在海淀区,剩下少数分布在东西城区等。我们以小窥大,可知东城区和海淀区是北京市科技业的中心。
6. 完整代码
由于每次运行爬虫耗时约20分钟,而运行数据分析耗时几秒钟,我们将两部分的工作单独运行,以节省数据分析的时间。
import requests
import math
import time
import pandas as pd
'''从网页获取JSON,使用POST请求,加上头部信息'''
def get_json(url,num):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host': 'www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput=',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
my_data = {
'first': 'true',
'pn': num,
'kd': '数据挖掘'
}
res = requests.post(url=url,headers = headers,data = my_data)
res.encoding = "utf-8"
page = res.json()
return page
'''计算要抓取的页数'''
def get_page(total_cout):
# 每页15个职位,向上取整
# 拉勾网最多显示30页结果
page_num = math.ceil(total_cout/15)
if page_num>30:
page_num = 30
return page_num
'''''对一个网页的职位信息进行解析,返回列表'''
def page_lists(job_list):
page_info_list = []
for i in job_list:
job_info = []
job_info.append(i['companyFullName'])
job_info.append(i['companyShortName'])
job_info.append(i['companySize'])
job_info.append(i['financeStage'])
job_info.append(i['district'])
job_info.append(i['positionName'])
job_info.append(i['workYear'])
job_info.append(i['education'])
job_info.append(i['salary'])
job_info.append(i['positionAdvantage'])
page_info_list.append(job_info)
return page_info_list
def main():
page_1=[]
url = "https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false"
total_info = []
page_1 = get_json(url,1)
total_count = page_1['content']['positionResult']['totalCount']
page = get_page(total_count)
time.sleep(30)
for n in range(1,page+1):
page_info = []
page_num = get_json(url,n)
page_nums = page_num['content']['positionResult']['result']
page_info = page_lists(page_nums)
total_info += page_info
print('已经抓取第{}页, 职位总数:{}'.format(n, len(total_info)))
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(30)
df = pd.DataFrame(data = total_info ,columns = ['公司全名','公司简称','公司规模','融资阶段','区域','职位名称','工作经验','学历要求','工资','职位福利'])
df.to_csv("D:/BeiJing.csv",index = False)
print("所有信息保存在D:/BeiJing.csv")
if __name__== "__main__":
main()
#================================================================
#================================================================
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from wordcloud import WordCloud
from scipy.misc import imread
import jieba
from pylab import mpl
""" 使matplotlib模块能显示中文 不会哈哈"""
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 读取数据
df = pd.read_csv("D:/BeiJing.csv",encoding = "gbk")
# 数据清洗,剔除实习岗位
df.drop(df[df['职位名称'].str.contains('实习')].index, inplace=True)
# 由于CSV文件内的数据是字符串形式,先用正则表达式将字符串转化为列表,再取区间的均值
pattern = '\d+'
df['工作年限'] = df['工作经验'].str.findall(pattern)
avg_work_year = []
for i in df['工作年限']:
if len(i)==2:
avg_work_year.append(sum([int(j) for j in i])/2)
elif len(i)==1:
avg_work_year.append(int(''.join(i)))
else:
avg_work_year.append(0)
df['经验'] = avg_work_year
""" 将字符串转化为列表,再取区间的前25%,比较贴近现实 """
df['salary'] = df['工资'].str.findall(pattern)
avg_salary = []
for k in df['salary']:
int_list = [int(n) for n in k]
avg_wage = int_list[0]+(int_list[1]-int_list[0])/4
avg_salary.append(avg_wage)
df['月工资'] = avg_salary
""" 描述统计 """
print('数据分析师工资描述:\n{}'.format(df['月工资'].describe()))
plt.hist(df["月工资"],bins = 16)
plt.xlabel("月工资千元")
plt.ylabel("频数")
plt.title("月工资直方图")
plt.savefig("D:/BeiJing/salary.jpg")
plt.show()
"""" 区域汇总 """
count = df["区域"].value_counts()
"""绘图 """
plt.pie(count, labels = count.keys(),labeldistance=1.4,autopct='%2.1f%%')
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.savefig("D:/BeiJing/local.jpg")
plt.show()
"""绘制词云,将职位福利中的字符串汇总 """
text = ''
for line in df['职位福利']:
text += line
"""使用jieba模块将字符串分割为单词列表 """
cut_text = ' '.join(jieba.cut(text))
color_mask = imread('D:/BeiJing/aaa.jpg') #设置背景图
cloud = WordCloud(
font_path = 'C:\Windows\Fonts\STSONG.ttf',
background_color = 'white',
mask = color_mask,
max_words = 1000,
max_font_size = 100
)
word_cloud = cloud.generate(cut_text)
# 保存词云图片
word_cloud.to_file('D:/BeiJing/cloud.jpg')
plt.imshow(word_cloud)
plt.axis('off')
plt.show()
df['学历要求'] = df['学历要求'].replace('不限','大专') #实证统计,将学历不限的职位要求认定为最低学历:大专
dummy_edu = pd.get_dummies(df['学历要求'],prefix = '学历') #学历分为大专\本科\硕士,将它们设定为虚拟变量
df_with_dummy = pd.concat([df['月工资'],df['经验'],dummy_edu],axis = 1) # 构建回归数组
""" 建立多元回归模型 """""
y = df_with_dummy['月工资']
X = df_with_dummy[['经验','学历_大专','学历_本科','学历_硕士']]
X=sm.add_constant(X)
model = sm.OLS(y,X)
results = model.fit()
print('回归方程的参数:\n{}\n'.format(results.params))
print('回归结果:\n{}'.format(results.summary()))
参考:https://blog.csdn.net/danspace1/article/details/80197106