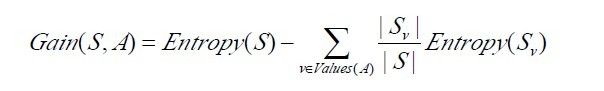决策树基础篇
1.1、什么是决策树
咱们直接切入正题。所谓决策树,顾名思义,是一种树,一种依托于策略抉择而建立起来的树。
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。
从数据产生决策树的机器学习技术叫做决策树学习, 通俗点说就是决策树,说白了,这是一种依托于分类、训练上的预测树,根据已知预测、归类未来。
来理论的太过抽象,下面举两个浅显易懂的例子:
第一个例子
套用俗语,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑:

也就是说,决策树的简单策略就是,好比公司招聘面试过程中筛选一个人的简历,如果你的条件相当好比如说某985/211重点大学博士毕业,那么二话不说,直接叫过来面试,如果非重点大学毕业,但实际项目经验丰富,那么也要考虑叫过来面试一下,即所谓具体情况具体分析、决策。但每一个未知的选项都是可以归类到已有的分类类别中的。
第二个例子
此例子来自Tom M.Mitchell著的机器学习一书:
小王的目的是通过下周天气预报寻找什么时候人们会打高尔夫,他了解到人们决定是否打球的原因最主要取决于天气情况。而天气状况有晴,云和雨;气温用华氏温度表示;相对湿度用百分比;还有有无风。如此,我们便可以构造一棵决策树,如下(根据天气这个分类决策这天是否合适打网球):
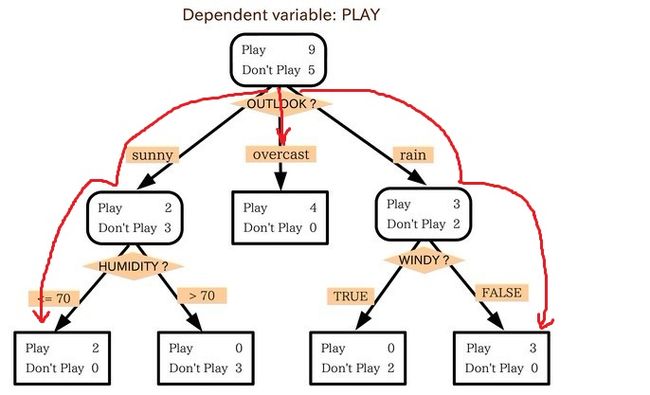
上述决策树对应于以下表达式:
(Outlook=Sunny ^Humidity<=70)V (Outlook = Overcast)V (Outlook=Rain ^ Wind=Weak)
1.2、ID3算法
1.2.1、决策树学习之ID3算法
ID3算法是决策树算法的一种。想了解什么是ID3算法之前,我们得先明白一个概念:奥卡姆剃刀。
- 奥卡姆剃刀(Occam's Razor, Ockham's Razor),又称“奥坎的剃刀”,是由14世纪逻辑学家、圣方济各会修士奥卡姆的威廉(William of Occam,约1285年至1349年)提出,他在《箴言书注》2卷15题说“切勿浪费较多东西,去做‘用较少的东西,同样可以做好的事情’。简单点说,便是:be simple。
ID3算法(Iterative Dichotomiser 3 迭代二叉树3代)是一个由Ross Quinlan发明的用于决策树的算法。这个算法便是建立在上述所介绍的奥卡姆剃刀的基础上:越是小型的决策树越优于大的决策树(be simple简单理论)。尽管如此,该算法也不是总是生成最小的树形结构,而是一个启发式算法。OK,从信息论知识中我们知道,期望信息越小,信息增益越大,从而纯度越高。ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益(很快,由下文你就会知道信息增益又是怎么一回事)最大的属性进行分裂。该算法采用自顶向下的贪婪搜索遍历可能的决策树空间。
所以,ID3的思想便是:
- 自顶向下的贪婪搜索遍历可能的决策树空间构造决策树(此方法是ID3算法和C4.5算法的基础);
- 从“哪一个属性将在树的根节点被测试”开始;
- 使用统计测试来确定每一个实例属性单独分类训练样例的能力,分类能力最好的属性作为树的根结点测试(如何定义或者评判一个属性是分类能力最好的呢?这便是下文将要介绍的信息增益,or 信息增益率)。
- 然后为根结点属性的每个可能值产生一个分支,并把训练样例排列到适当的分支(也就是说,样例的该属性值对应的分支)之下。
- 重复这个过程,用每个分支结点关联的训练样例来选取在该点被测试的最佳属性。
这形成了对合格决策树的贪婪搜索,也就是算法从不回溯重新考虑以前的选择。
下图所示即是用于学习布尔函数的ID3算法概要:
1.2.2、哪个属性是最佳的分类属性
1、信息增益的度量标准:熵
上文中,我们提到:“ ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益( 很快,由下文你就会知道信息增益又是怎么一回事 )最大的属性进行分裂。”接下来,咱们就来看看这个信息增益是个什么概念(当然,在了解信息增益之前,你必须先理解:信息增益的度量标准:熵)。上述的ID3算法的核心问题是选取在树的每个结点要测试的属性。我们希望选择的是最有利于分类实例的属性,信息增益(Information Gain)是用来 衡量给定的属性区分训练样例的能力,而ID3算法在增长树的每一步使用信息增益从候选属性中选择属性。为了精确地定义信息增益,我们先定义信息论中广泛使用的一个度量标准,称为熵(entropy),它刻画了任意样例集的纯度(purity)。给定包含关于某个目标概念的正反样例的样例集S,那么S相对这个布尔型分类的熵为:
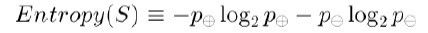
上述公式中,p+代表正样例,比如在本文开头第二个例子中p+则意味着去打羽毛球,而p-则代表反样例,不去打球(在有关熵的所有计算中我们定义0log0为0)。
如果写代码实现熵的计算,则如下所示:
//根据具体属性和值来计算熵 double ComputeEntropy(vector> remain_state, string attribute, string value,bool ifparent){ vector count (2,0); unsigned int i,j; bool done_flag = false;//哨兵值 for(j = 1; j < MAXLEN; j++){ if(done_flag) break; if(!attribute_row[j].compare(attribute)){ for(i = 1; i < remain_state.size(); i++){ if((!ifparent&&!remain_state[i][j].compare(value)) || ifparent){//ifparent记录是否算父节点 if(!remain_state[i][MAXLEN - 1].compare(yes)){ count[0]++; } else count[1]++; } } done_flag = true; } } if(count[0] == 0 || count[1] == 0 ) return 0;//全部是正实例或者负实例 //具体计算熵 根据[+count[0],-count[1]],log2为底通过换底公式换成自然数底数 double sum = count[0] + count[1]; double entropy = -count[0]/sum*log(count[0]/sum)/log(2.0) - count[1]/sum*log(count[1]/sum)/log(2.0); return entropy; } 举例来说,假设S是一个关于布尔概念的有14个样例的集合,它包括9个正例和5个反例(我们采用记号[9+,5-]来概括这样的数据样例),那么S相对于这个布尔样例的熵为:
Entropy([9+,5-])=-(9/14)log2(9/14)-(5/14)log2(5/14)=0.940。
So ,根据上述这个公式,我们可以得到:S的所有成员属于同一类,Entropy(S)=0; S的正反样例数量相等,Entropy(S)=1;S的正反样例数量不等,熵介于0,1之间,如下图所示:
信息论中对熵的一种解释,熵确定了要编码集合S中任意成员的分类所需要的最少二进制位数。更一般地,如果 目标属性具有c个不同的值,那么S相对于c个状态的分类的熵定义为:
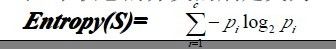
Pi为子集合中不同性(而二元分类即正样例和负样例)的样例的比例。
2、信息增益度量期望的熵降低
信息增益Gain(S,A)定义
已经有了熵作为衡量训练样例集合纯度的标准,现在可以定义属性分类训练数据的效力的度量标准。这个标准被称为“信息增益(information gain)”。简单的说,一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵降低(或者说,样本按照某属性划分时造成熵减少的期望)。更精确地讲,一个属性A相对样例集合S的信息增益Gain(S,A)被定义为:
其中 Values(A)是属性A所有可能值的集合,是S中属性A的值为v的子集。换句话来讲,Gain(S,A)是由于给定属性A的值而得到的关于目标函数值的信息。当对S的一个任意成员的目标值编码时,Gain(S,A)的值是在知道属性A的值后可以节省的二进制位数。
接下来,有必要提醒读者一下:关于下面这两个概念 or 公式,
下面,举个例子,假定S是一套有关天气的训练样例,描述它的属性包括可能是具有Weak和Strong两个值的Wind。像前面一样,假定S包含14个样例,[9+,5-]。在这14个样例中,假定正例中的6个和反例中的2个有Wind =Weak,其他的有Wind=Strong。由于按照属性Wind分类14个样例得到的信息增益可以计算如下。
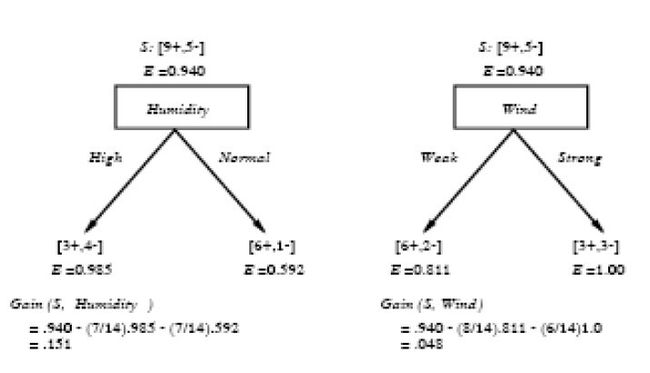
运用在本文开头举得第二个根据天气情况是否决定打羽毛球的例子上,得到的最佳分类属性如下图所示:
在上图中,计算了两个不同属性:湿度(humidity)和风力(wind)的信息增益,最终humidity这种分类的信息增益0.151>wind增益的0.048。说白了,就是在星期六上午是否适合打网球的问题诀策中,采取humidity较wind作为分类属性更佳,决策树由此而来。
//计算信息增益,DFS构建决策树 //current_node为当前的节点 //remain_state为剩余待分类的样例 //remian_attribute为剩余还没有考虑的属性 //返回根结点指针 Node * BulidDecisionTreeDFS(Node * p, vector> remain_state, vector remain_attribute){ //if(remain_state.size() > 0){ //printv(remain_state); //} if (p == NULL) p = new Node(); //先看搜索到树叶的情况 if (AllTheSameLabel(remain_state, yes)){ p->attribute = yes; return p; } if (AllTheSameLabel(remain_state, no)){ p->attribute = no; return p; } if(remain_attribute.size() == 0){//所有的属性均已经考虑完了,还没有分尽 string label = MostCommonLabel(remain_state); p->attribute = label; return p; } double max_gain = 0, temp_gain; vector ::iterator max_it; vector ::iterator it1; for(it1 = remain_attribute.begin(); it1 < remain_attribute.end(); it1++){ temp_gain = ComputeGain(remain_state, (*it1)); if(temp_gain > max_gain) { max_gain = temp_gain; max_it = it1; } } //下面根据max_it指向的属性来划分当前样例,更新样例集和属性集 vector new_attribute; vector > new_state; for(vector ::iterator it2 = remain_attribute.begin(); it2 < remain_attribute.end(); it2++){ if((*it2).compare(*max_it)) new_attribute.push_back(*it2); } //确定了最佳划分属性,注意保存 p->attribute = *max_it; vector values = map_attribute_values[*max_it]; int attribue_num = FindAttriNumByName(*max_it); new_state.push_back(attribute_row); for(vector ::iterator it3 = values.begin(); it3 < values.end(); it3++){ for(unsigned int i = 1; i < remain_state.size(); i++){ if(!remain_state[i][attribue_num].compare(*it3)){ new_state.push_back(remain_state[i]); } } Node * new_node = new Node(); new_node->arrived_value = *it3; if(new_state.size() == 0){//表示当前没有这个分支的样例,当前的new_node为叶子节点 new_node->attribute = MostCommonLabel(remain_state); } else BulidDecisionTreeDFS(new_node, new_state, new_attribute); //递归函数返回时即回溯时需要1 将新结点加入父节点孩子容器 2清除new_state容器 p->childs.push_back(new_node); new_state.erase(new_state.begin()+1,new_state.end());//注意先清空new_state中的前一个取值的样例,准备遍历下一个取值样例 } return p; } 1.2.3、ID3算法决策树的形成
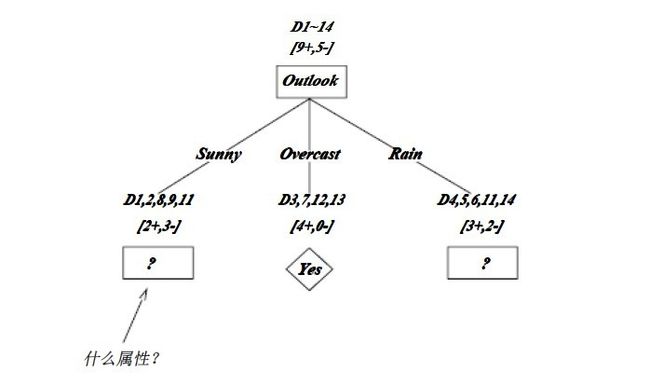
OK,下图为ID3算法第一步后形成的部分决策树。这样综合起来看,就容易理解多了。1、overcast样例必为正,所以为叶子结点,总为yes;2、ID3无回溯,局部最优,而非全局最优,还有另一种树后修剪决策树。下图是ID3算法第一步后形成的部分决策树:
如上图,训练样例被排列到对应的分支结点。分支Overcast的所有样例都是正例,所以成为目标分类为Yes的叶结点。另两个结点将被进一步展开,方法是按照新的样例子集选取信息增益最高的属性。