设计好的数据结构对程序至关重要
这阵子在做一个比较大型的服务器,在设计中碰到了很多问题,而其中有一个问题很有趣,大致是这样的:服务器接受客户端的服务请求,由于客户的服务请求数量庞大,处理服务需要一定的时间且允许一定的时延,很自然的用到了任务队列和工作线程池,如下图

其中Gate接受客户端的链接,当收到客户端的服务请求时,将会根据收到的服务类型生成Task对象,这些诸如TaskA、TaskB、TaskC之类的具体任务类都继承自基类TaskBase,之后将该任务对象添加到工作线程管理类的任务队列TaskList中,当任务对象不为空,且检测到某个工作线程空闲时,就会将该任务交给该工作线程处理,并将结果发送给客户端,理论很简单。
最初的设计,是让TaskA这些任务类保存这些任务的数据,而工作线程有各个任务类型对应的处理函数,如
在工作线程分配到任务时,会自动根据任务类型调用相应的处理函数。但是,我的工作队列保存的统一的TaskBase指针,如何让工作线程调用正确的处理函数成了一个问题。说到底,这是一个动态类型识别的过程,为此我想了各种办法,甚至想用Traits类型识别。不过很不幸,至今我还没想到一个好的方法,因为C++从基类指针到派生类指针的转换是可以的,但是不会自动转换,而且,又不想加一个类型枚举,用一个switch去识别转换,因为这是很次的方法。
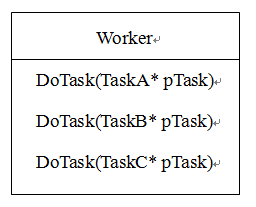
经过一番思考之后,决定对我的数据进行调整,让TaskBase定义一个虚函数DoTask,各个具体的任务类根据自己的数据定义个自己的DoTask版本,也就是让Task自己去处理自己的数据,如下图

当工作线程收到TaskBase类的指针,只需调用pTask->DoTask()就可以了,用简单的多态机制解决了类型识别的大难题。
这样一个经历,让我想起了《编程珠玑》中的一个例子,一个值得思考的例子:
磁盘中的一个文件存放了一些7位数的电话号码,最多1000万个(后来发现大概实际有800万个),且顺序不定,每个号码最多出现一次。程序的要求是在大约1MB的内存中完成这些电话号码的排序,并输出到一个文件中。
对于这中排序问题,我们很自然就想到了库函数的进行排序,但是,如果用32位整数表示一个号码,则1MB的内存大约可以存放250 000个号码,那么我们就需要做大约40趟的单独排序输出到不同的文件中,再将这40个有序的序列进行归并排序。那么,这样数量庞大的排序和频繁的读写文件,性能可想而知,执行时间将是一个大问题。
那么,我们不禁要想能不能在1MB的内存中表示这800万个电话号码,然后用某种神奇的排序方法,迅速排好序输出到目标文件?我们算一下,1MB的内存有8 388 608个位,问题就转化为能否用着大约830万个位表示这800万个电话号码。到了这一步,很自然就会想用一个位表示一个电话号码。
我们可以用一个大于一个集合中最大的数的位数来表示一个集合,例如集合{1,2,3,5,8,13},那么我们可以用一个20位的字符串来表示这个集合:
0 1 1 1 0 1 0 0 1 0 0 0 1 0 0 0 0 0 0
集合中有的元素,我们置对应的位为1,没有的元素则对应位为0(这里字符数组下标从0开始)。
通过以上分析,上面的问题就迎刃而解了,我们用一个830万个位的位序列,先将全部位置为0,读取输入文件,将读到的号码对应的位置为1,读取完毕后开始扫描这个位序列,如果对应位为1,则将这个位序号输出到文件,否则跳过。这里巧妙的将排序问题简化。
13 1 5 10 14 9 读入后的位序列为 0 1 0 0 0 1 0 0 0 1 1 0 0 1 1 ... 输出为 1 5 9 10 13 14
而这个程序的编码也是一个非常简单的事了:
for i = [0 , n)
bit[i] = 0
for each i in the in put file
bit[i] = 1
for 1 = [0 , n)
if bit[i] == 1
write i on the output file
从上面的两个问题,可以知道,设计好的数据结构可以让我们的工作事半功倍,分析客户需求,设计数据结构和程序结构将是项目中非常重要的部分。