《Image-to-Image Translation with Conditional Adversarial Networks》论文总结
《Image-to-Image Translation with Conditional Adversarial Networks》论文总结

图1 图像到图像的转换
目前对于图像到图像间的转换问题(如图1所示)有多种实现方法,例如CNN、其他GAN框架等方法均可实现。但是这些传统实现方法均存在一个问题:对于每一种类型的图像到图像间的转换,都需要一个特定的实现框架,需要设定专门的损失函数。针对这个问题,本论文提出了一个“图像到图像转换”的通用框架。
论文的主要贡献包括以下两点:
(1)证明了在很多问题上, conditional GANs能产生合理的结果。
(2)提出了一个“图像到图像转换”的通用框架,并分析几个重要架构选择的效果。
本论文的主要内容可以归纳以下三点:
(1)pix2pix的目标函数。
(2)pix2pix的网络架构。
(3)通过实验分析证明pix2pix的目标函数和网络框架的性能。
一、pix2pix的目标函数
pix2pix的目标函数有两部分组成,如下所示:
(1)条件生成对抗网络目标函数,如下:

(2)L1损失函数,如下:

“(1)和(2)”两部分组合后得到最终函数,如下:
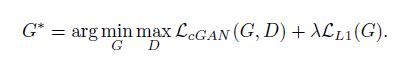
“G”代表生成器,“D”代表判别器,“G”使目标函数最小化,“D”使目标函数最大化。站在“G”的角度分析,“G”作为生成器,G(x,z)生成的图像尽可能逼真,那么“D”判别器会认为G(x,z)为真的图像,则D(x,G(x,z))的值尽可能大,接近1,则1-D(x,G(x,z))的值变小,目标函数变小。站在“D”的角度分析,“D”作为判别器,“D”会识别出G(x,z)为假的图像,则D(x,G(x,z))的值尽可能小,则1-D(x,G(x,z))的值变大,由于“y”表示真实图像,则D(x,y)值也变大,最终目标函数变大。
二、实验分析pix2pix的目标函数性能
图2:不同损失函数的实验结果
图2显示,只有L1损失函数,输出的图像比较模糊。只有cGAN,图像相对清晰,但是出现了视觉伪像。L1和cGAN结合后,生成的图像清晰,伪像减少。
表1:在Cityscapes上不同损失函数的FCN-scores结果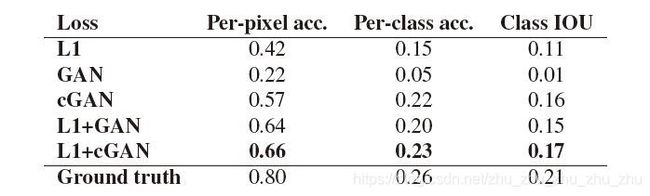
图2和表1的实验均证明L1和cGAN结合,目标函数的性能最好。
三、pix2pix的网络架构
pix2pix的网络架构包括生成器和判别器。生成器使用了“U-Net”结构,判别器使用了卷积“PatchGAN”分类器。
(1)生成器-U-net。
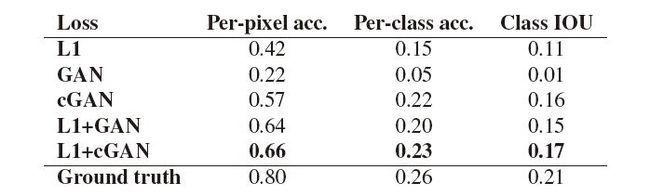
图3:编码器-解码器、U-Net架构
U-Net中的Skip Connections将其与标准的编码器-解码器架构区分开来。U-Net在第i层和第n−i层之间添加Skip Connections,其中n是网络的总层数。每条Skip Connections将第i层和第n−i层的特征通道连接在一起。使用skip connection结构将下采样层与上采样层相连,使得下采样层提取到的特征可以直接传递到上采样层,这使得U-net网络的像素定位更加准确,分割精度更高。

图4:U-Net的详细架构
U-net网络的结构如图4所示,蓝色箭头代表卷积和激活函数,灰色箭头代表复制剪切操作,红色箭头代表下采样,绿色箭头代表反卷积,conv1X1代表卷积核为1X1的卷积操作。U-net网络没有全连接层,只有卷积和下采样。U-net可以对像素进行端到端的分割,即输入是一幅图像,输出也是一幅图像。U-net网络由两部分组成:一个收缩路径(contracting path)来获取上下文信息以及一个对称的扩张路径(expanding path)用以精确定位。收缩网络主要负责下采样的工作,提取高维特征信息,每一次下采样包含两个的3x3的卷积操作,一个 2x2 的池化操作,通过修正线性单元(rectified linear unit, ReLU)作为激活函数,每一次下采样,图片大小变为原来的 1/2,特征数量变为原来的 2倍。 扩张网络主要负责上采样的工作,每一次上采样包含两个3x3 的卷积操作,通过修正线性单元作为激活函数。每一次上采样,图片大小变为原来的 2 倍,特征数量变为原来的 1/2。 在上采样操作中,将每一次的输出特征与相映射的收缩网络的特征合并在一起,补全中间丢失的边界信息。最后,加入 1x1 的卷积操作将之前所获的的特征映射到所属分类上面。
(2)判别器—PatchGAN
PatchGAN 将图像分成多个(N×N)patch,然后判断每个patch的“真与假”,将一张图片所有patch的结果取平均值作为最终的判别器输出,而不是判断整个图像 的“真与假”。作者认为这会强制实施更多约束,从而突出原图的高频细节。此外,PatchGAN具有更少的参数,并且比分类整个图像运行得更快。
四、实验分析pix2pix网络框架的性能
(1)生成器-U-net的性能。

图5:添加Skip Connections后U-Net获得更高质量的结果
表2:不同生成器架构在Cityscapes上的FCN-scores实验结果
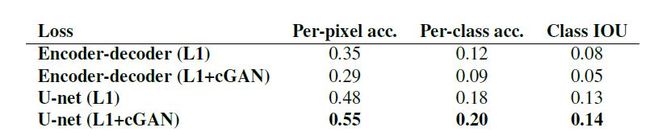
图5和表2的实验均证明U-net的性能最好。
(2)判别器—PatchGAN的性能。

图6:patch大小变化对实验的影响结果
图6显示,巴士在被L1损失函数的网络训练为灰色,而在1X1的PixelGAN训练时巴士为红色。使用16x16的PatchGANs训练的图片更清晰,但也导致图片缺乏立体感。70 x 70 PatchGANs减轻了伪影,取得更好的效果。如果采用286 x 286的ImageGAN,比70 x 70 PatchGANs具有更多的参数和更大的深度,并且可能更难训练。
表3:判别器不同感受野大小的FCN-scores实验结果
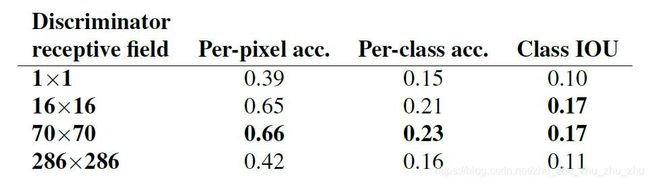
图6和表3的实验均表明70 x 70的patch产生最佳效果。
五、pix2pix的优点和缺点
pix2pix的优点:
1、对于实现图像到图像的转换问题,提供了通用框架。相比于传统方法实现图像到图像间的转换,对于不同类型的图像转换,pix2pix不需要一个特定的算法,也不需要设定专门的损失函数。
2、利用U-Net框架提升了图像的细节特征,并且利用PatchGAN分类器来处理图像的高频部分,使生成图像的轮廓和条纹更清晰,色彩度更加鲜艳。
pix2pix的缺点:
1、在训练模型阶段需要大量的1对1配对图像,但是这些图像收集起来很困难。
2、生成图像的真实度有待提高,如果输入的图像轮廓清晰度不高,那么生成的图像会比较模糊,图像不够真实。