百度飞桨顶会论文复现(5):视频分类论文之《Representation Flow for Action Recognition》篇
这次老师在课上总共领读了4篇分类论文,我这里分享其中的一篇论文,是关于使用神经网络对
光流进行学习。
课程地址是:https://aistudio.baidu.com/aistudio/education/group/info/1340。
论文地址是:https://arxiv.org/abs/1810.01455。
Github地址是:https://github.com/piergiaj/representation-flow-cvpr19。
论文中文翻译地址:https://blog.csdn.net/qq_42037746/article/details/107411080。
文章目录
- 1.相关介绍
- 2.本文方法
- 2.1 光流法介绍
- 2.2 光流层细节
- 3.结果展示
1.相关介绍
这里我将按照老师上课领读的顺序来进行介绍。
过去在对视频进行分类时,一般需要设计两个网络,一个网路输入静态图像得到图像特征;另一个网络输入两张图像之间的光流,学习运动特征;然后对两个特征进行融合,进行最终的视频分类。这里最主要的问题是光流的计算成本比较高,通常需要上百次的迭代优化;另一个是需要训练两个网络,这使得模型在推理时资源消耗较大,限制了其应用。因此本文作者设计了一种CNN层:表示光流层,对光流进行学习,并且表示光流层可以对任意一层特征图进行学习。
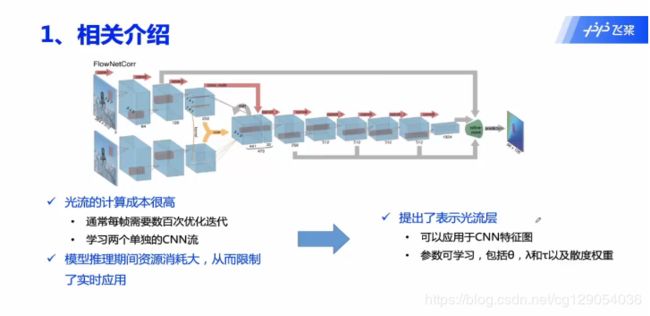
2.本文方法
2.1 光流法介绍
在介绍本文方法之前首先回顾下什么是光流?光流是用来描述像素随时间在图像之间运动的方法。
在光流法中一个基本假设是:同一个空间点的像素灰度值,在各个图像中是固定不变的,可以用 I ( x , y , t ) I(x,y,t) I(x,y,t)来表示像素灰度。
下图中, t t t时刻图像中像素位置为 ( x , y ) (x,y) (x,y),在 t + d t t+dt t+dt时刻运动到 ( x + d x , y + d y ) (x+dx,y+dy) (x+dx,y+dy),由于灰度不变可得:
I ( x , y , t ) = I ( x + d x , y + d y , t + d t ) I(x,y,t)=I(x+dx,y+dy,t+dt) I(x,y,t)=I(x+dx,y+dy,t+dt)
泰勒一阶展开,像素运动 ( u 1 , u 2 ) (u_1,u_2) (u1,u2)即为光流矢量。

2.2 光流层细节
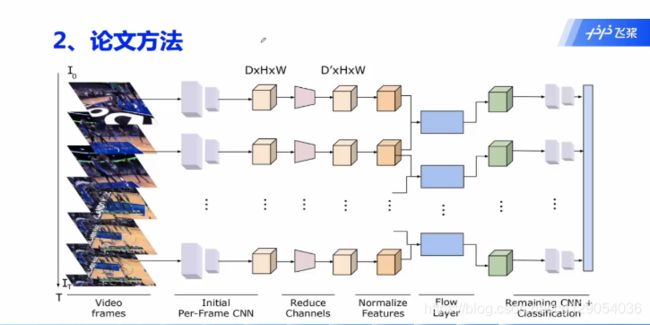
论文的整体网络结构如下,可以看到输入只有图片,与以往的分类网络不同的是多了一个Flow Layer,这也是整个网络的核心部分。
下图为光流层迭代计算过程,这里 F 1 , F 2 F_1,F_2 F1,F2为两张图片的特征图。

初始时 u = 0 , p = 0 , p c = F 2 − F 1 u=0,p=0,p_c=F_2-F_1 u=0,p=0,pc=F2−F1;然后进行 n n n次迭代计算;
计算特征图 F 2 F_2 F2的梯度,这里的梯度是通过卷积操作计算的,下面的矩阵表示为卷积核 。 ∇ F 2 x = [ 1 0 − 1 2 0 − 2 1 0 − 1 ] ∗ F 2 , ∇ F 2 y = [ 1 2 1 0 0 0 − 1 − 2 − 1 ] ∗ F 2 \nabla{F_{2x}}=\begin{bmatrix}1&0&-1\\2&0&-2\\1&0&-1\end{bmatrix}*F_2,\nabla{F_{2y}}=\begin{bmatrix}1&2&1\\0&0&0\\-1&-2&-1\end{bmatrix}*F_2 ∇F2x=⎣⎡121000−1−2−1⎦⎤∗F2,∇F2y=⎣⎡10−120−210−1⎦⎤∗F2
然后是更新 v v v的值;
计算 p p p的散度: d i v e r g e n c e ( p ) = p x ∗ w x + p y ∗ w y divergence(p)=p_x*w_x+p_y*w_y divergence(p)=px∗wx+py∗wy
然后是计算速度梯度,操作和求 F 2 F_2 F2梯度类似: ∇ u x = [ 1 0 − 1 2 0 − 2 1 0 − 1 ] ∗ u x , ∇ u y = [ 1 2 1 0 0 0 − 1 − 2 − 1 ] ∗ u y \nabla{u_{x}}=\begin{bmatrix}1&0&-1\\2&0&-2\\1&0&-1\end{bmatrix}*u_x,\nabla{u_{y}}=\begin{bmatrix}1&2&1\\0&0&0\\-1&-2&-1\end{bmatrix}*u_y ∇ux=⎣⎡121000−1−2−1⎦⎤∗ux,∇uy=⎣⎡10−120−210−1⎦⎤∗uy
跟新p的值;
最终,经过 n n n次迭代即可得到最终的像素运动速度 u u u。
下面是原作者光流层实现代码,首先网络的定义:
class FlowLayer(nn.Module):
def __init__(self, channels=1, bottleneck=32, params=[1,1,1,1,1], n_iter=10):
super(FlowLayer, self).__init__()
self.bottleneck = nn.Conv3d(channels, bottleneck, stride=1, padding=0, bias=False, kernel_size=1)
self.unbottleneck = nn.Conv3d(bottleneck*2, channels, stride=1, padding=0, bias=False, kernel_size=1)
self.bn = nn.BatchNorm3d(channels)
channels = bottleneck
self.n_iter = n_iter
if params[0]:
self.img_grad = nn.Parameter(torch.FloatTensor([[[[-0.5,0,0.5]]]]).repeat(channels,channels,1,1))
self.img_grad2 = nn.Parameter(torch.FloatTensor([[[[-0.5,0,0.5]]]]).transpose(3,2).repeat(channels,channels,1,1))
else:
self.img_grad = nn.Parameter(torch.FloatTensor([[[[-0.5,0,0.5]]]]).repeat(channels,channels,1,1), requires_grad=False)
self.img_grad2 = nn.Parameter(torch.FloatTensor([[[[-0.5,0,0.5]]]]).transpose(3,2).repeat(channels,channels,1,1), requires_grad=False)
if params[1]:
self.f_grad = nn.Parameter(torch.FloatTensor([[[[-1],[1]]]]).repeat(channels,channels,1,1))
self.f_grad2 = nn.Parameter(torch.FloatTensor([[[[-1],[1]]]]).repeat(channels,channels,1,1))
self.div = nn.Parameter(torch.FloatTensor([[[[-1],[1]]]]).repeat(channels,channels,1,1))
self.div2 = nn.Parameter(torch.FloatTensor([[[[-1],[1]]]]).repeat(channels,channels,1,1))
else:
self.f_grad = nn.Parameter(torch.FloatTensor([[[[-1],[1]]]]).repeat(channels,channels,1,1), requires_grad=False)
self.f_grad2 = nn.Parameter(torch.FloatTensor([[[[-1],[1]]]]).repeat(channels,channels,1,1), requires_grad=False)
self.div = nn.Parameter(torch.FloatTensor([[[[-1],[1]]]]).repeat(channels,channels,1,1), requires_grad=False)
self.div2 = nn.Parameter(torch.FloatTensor([[[[-1],[1]]]]).repeat(channels,channels,1,1), requires_grad=False)
self.channels = channels
self.t = 0.3
self.l = 0.15
self.a = 0.25
if params[2]:
self.t = nn.Parameter(torch.FloatTensor([self.t]))
if params[3]:
self.l = nn.Parameter(torch.FloatTensor([self.l]))
if params[4]:
self.a = nn.Parameter(torch.FloatTensor([self.a]))
前向传播:
def forward(self, x):
residual = x[:,:,:-1]
x = self.bottleneck(x)
inp = self.norm_img(x)
x = inp[:,:,:-1]
y = inp[:,:,1:]
b,c,t,h,w = x.size()
x = x.permute(0,2,1,3,4).contiguous().view(b*t,c,h,w)
y = y.permute(0,2,1,3,4).contiguous().view(b*t,c,h,w)
u1 = torch.zeros_like(x)
u2 = torch.zeros_like(x)
l_t = self.l * self.t
taut = self.a/self.t
grad2_x = F.conv2d(F.pad(y,(1,1,0,0)), self.img_grad, padding=0, stride=1)#, groups=self.channels)
grad2_x[:,:,:,0] = 0.5 * (x[:,:,:,1] - x[:,:,:,0])
grad2_x[:,:,:,-1] = 0.5 * (x[:,:,:,-1] - x[:,:,:,-2])
grad2_y = F.conv2d(F.pad(y, (0,0,1,1)), self.img_grad2, padding=0, stride=1)#, groups=self.channels)
grad2_y[:,:,0,:] = 0.5 * (x[:,:,1,:] - x[:,:,0,:])
grad2_y[:,:,-1,:] = 0.5 * (x[:,:,-1,:] - x[:,:,-2,:])
p11 = torch.zeros_like(x.data)
p12 = torch.zeros_like(x.data)
p21 = torch.zeros_like(x.data)
p22 = torch.zeros_like(x.data)
gsqx = grad2_x**2
gsqy = grad2_y**2
grad = gsqx + gsqy + 1e-12
rho_c = y - grad2_x * u1 - grad2_y * u2 - x
for i in range(self.n_iter):
rho = rho_c + grad2_x * u1 + grad2_y * u2 + 1e-12
v1 = torch.zeros_like(x.data)
v2 = torch.zeros_like(x.data)
mask1 = (rho < -l_t*grad).detach()
v1[mask1] = (l_t * grad2_x)[mask1]
v2[mask1] = (l_t * grad2_y)[mask1]
mask2 = (rho > l_t*grad).detach()
v1[mask2] = (-l_t * grad2_x)[mask2]
v2[mask2] = (-l_t * grad2_y)[mask2]
mask3 = ((mask1^1) & (mask2^1) & (grad > 1e-12)).detach()
v1[mask3] = ((-rho/grad) * grad2_x)[mask3]
v2[mask3] = ((-rho/grad) * grad2_y)[mask3]
del rho
del mask1
del mask2
del mask3
v1 += u1
v2 += u2
u1 = v1 + self.t * self.divergence(p11, p12)
u2 = v2 + self.t * self.divergence(p21, p22)
del v1
del v2
u1 = u1
u2 = u2
u1x, u1y = self.forward_grad(u1)
u2x, u2y = self.forward_grad(u2)
p11 = (p11 + taut * u1x) / (1. + taut * torch.sqrt(u1x**2 + u1y**2 + 1e-12))
p12 = (p12 + taut * u1y) / (1. + taut * torch.sqrt(u1x**2 + u1y**2 + 1e-12))
p21 = (p21 + taut * u2x) / (1. + taut * torch.sqrt(u2x**2 + u2y**2 + 1e-12))
p22 = (p22 + taut * u2y) / (1. + taut * torch.sqrt(u2x**2 + u2y**2 + 1e-12))
del u1x
del u1y
del u2x
del u2y
flow = torch.cat([u1,u2], dim=1)
flow = flow.view(b,t,c*2,h,w).contiguous().permute(0,2,1,3,4)
flow = self.unbottleneck(flow)
flow = self.bn(flow)
return F.relu(residual+flow)
3.结果展示
首先作者分析了对不同特征层使用光流层的分类结果:可以看出在第三个残差块后面使用光流层效果最好。 
然后作者讨论了不同结构光流层的分类结果,可看到Flow-Conv-Flow的分类效果是最好的。

最后作者与现有的SOTA模型进行了对比,可以看到,FCF+(2+1)D的效果是最好的。
这里简单对《Representation Flow for Action Recognition》论文进行了介绍,更多理解还需要反复阅读论文和阅读源码。