PyTorch内部机制深入了解
已经学习PyTorch一段时间了,不得不说对于其中很多知识都存在不解,最近淘到一篇讨论PyTorch内部机制的文章,觉得很是不错,留下来好好看:
万字综述,核心开发者全面解读PyTorch内部机制
【本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载
作者:Edward Z. Yang
机器之心编译
参与:panda】
已看一遍,仍有不解
对该文章的大致理解:
张量库的各种概念
张量
张量是一种包含某种标量类型(比如浮点数和整型数等)的 n 维数据结构。可以将张量看作是由一些数据构成的,还有一些元数据描述了张量的大小、所包含的元素的类型(dtype)、张量所在的设备(CPU 内存?CUDA 内存?)
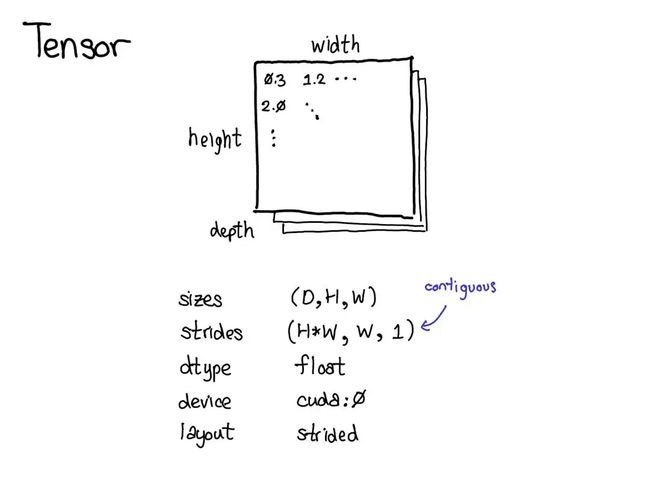
文章着重介绍了步幅(stride)
步幅 stride
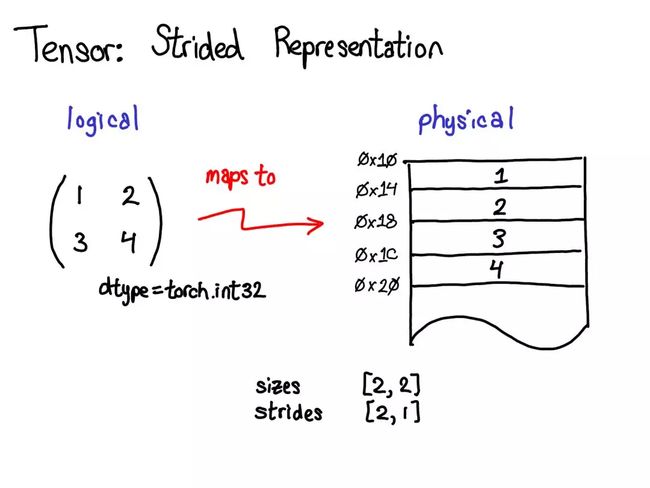
张量一个数学概念。但要在计算机中表示它,必须定义某种物理表示方法。最常用的表示方法是在内存中相邻地放置张量的每个元素(这也是术语「contiguous(邻接)」的来源),即将每一行写出到内存。为了记住张量的实际维度,必须将规模大小记为额外的元数据。
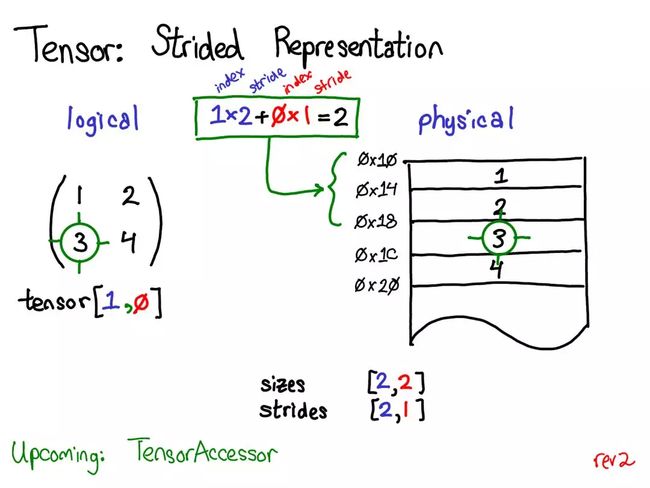
步幅能将张量的逻辑位置转译为物理内存中的位置:要找到一个张量中任意元素的位置,将每个索引与该维度下各自的步幅相乘,然后将它们全部加到一起。在上图中,我用蓝色表示第一个维度,用红色表示第二个维度,以便你了解该步幅计算中的索引和步幅。进行这个求和后,我得到了 2(零索引的);实际上,数字 3 正是位于这个邻接数组的起点以下 2 个位置。
举个例子,取出一个表示以上张量的第二行的张量:
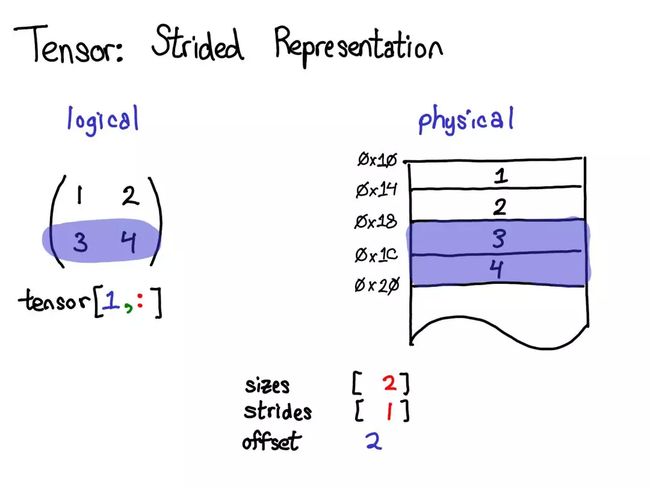
使用高级的索引支持,只需写出张量 [1, :] 就能得到这一行。重要的是:这样做,不会创建一个新张量;而是会返回一个基于底层数据的不同域段(view)的张量。这意味着,如果编辑该视角下的这些数据,它就会反映在原始的张量中。
在这种情况下,的内部机制:3 和 4 位于邻接的内存中,只需要记录一个说明该(逻辑)张量的数据位于顶部以下 2 个位置的偏移量(offset)。(每个张量都记录一个偏移量,但大多数时候它为零,出现这种情况时会在图表中省略它。
演讲时的提问:如果我取张量的一个域段,我该如何释放底层张量的内存?
答案:你必须制作该域段的一个副本,由此断开其与原始物理内存的连接。你能做的其它事情实际上并不多。另外,如果你很久之前写过 Java,取一个字符串的子字符串也有类似的问题,因为默认不会制作副本,所以子字符串会保留(可能非常大的字符串)。很显然,Java 7u6 将其固定了下来。
再举个例子,取出一个表示以上张量的第一列的张量:
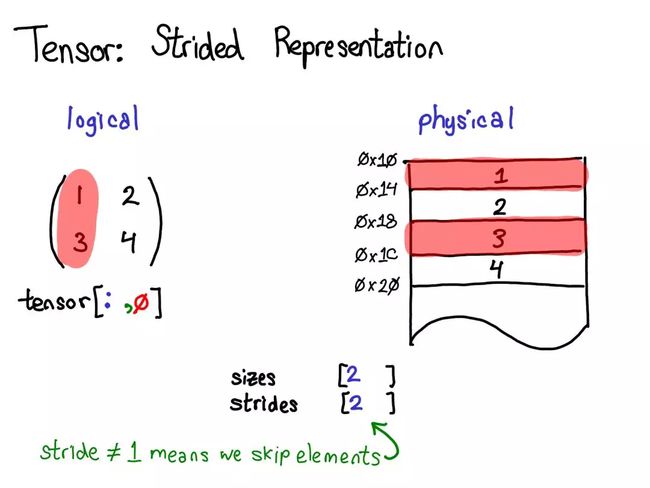
不再将一个元素与下一个元素之间的步幅指定为 1,而是将其设定为 2,即跳两步。(这就是其被称为「步幅(stride)」的原因:如果将索引看作是在布局上行走,步幅就指定了每次迈步时向前多少位置。)步幅表示实际上可以表示所有类型的张量域段.
那么如何实现这一功能呢?
张量的数据布局
如果可以得到张量的域段,这就意味着必须解耦张量的概念(所知道且喜爱的面向用户的概念)以及存储张量的数据的实际物理数据的概念(称为「存储(storage)」):
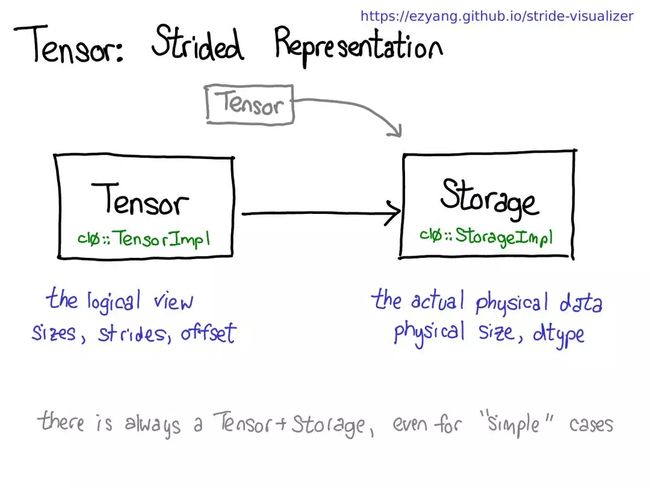
也许会有多个张量共享同一存储。存储会定义张量的 dtype 和物理大小,同时每个张量还会记录大小、步幅和偏移量,这定义的是物理内存的逻辑解释。
有一点需要注意:总是会存在一个张量-存储对,即使并不真正需要存储的「简单」情况也是如此(比如,只是用 torch.zeros(2, 2) 划配一个邻接张量时)。
顺便一提,我们感兴趣的不是这种情况,而是有一个分立的存储概念的情况,只是将一个域段定义为有一个基张量支持的张量。这会更加复杂一些,但也有好处:邻接张量可以实现远远更加直接的表示,而没有存储造成的间接麻烦。这样的变化能让 PyTorch 的内部表示方式更接近 Numpy。
对张量的操作
在最抽象的层面上,调用 torch.mm 时,会发生两次调度:
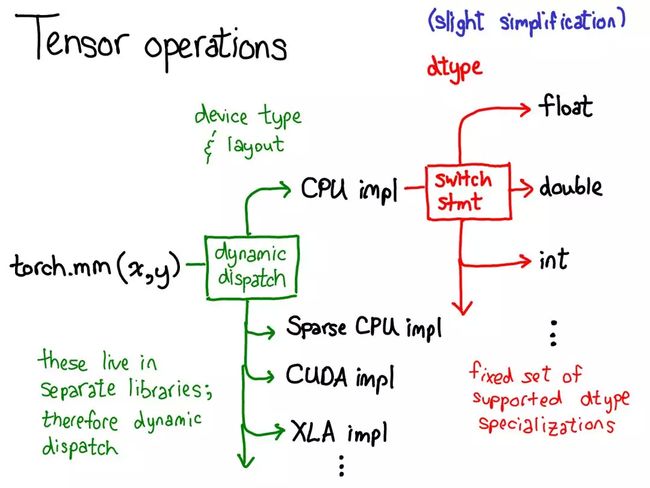
第一次调度基于设备类型和张量布局:比如是 CPU 张量还是 CUDA张量,是有步幅的张量还是稀疏的张量。这个调度是动态的:这是一个虚函数(virtual function)调用.
这里需要做一次调度应该是合理的:CPU 矩阵乘法的实现非常不同于 CUDA 的实现。这里是动态调度的原因是这些核(kernel)可能位于不同的库(比如 libcaffe2.so 或 libcaffe2_gpu.so),这样如果想进入一个没有直接依赖的库,必须通过动态调度抵达那里。
第二次调度是在所涉 dtype 上的调度。这个调度只是一个简单的 switch 语句,针对的是核选择支持的任意 dtype。这里需要调度的原因也很合理:CPU 代码(或 CUDA 代码)是基于 float 实现乘法,这不同于用于 int 的代码。这说明需要为每种 dtype 都使用不同的核。
张量扩展
除了密集的 CPU 浮点数张量,还有其它很多类型的张量,比如 XLA 张量、量化张量、MKL-DNN 张量;而对于一个张量库,还有一件需要思考的事情:如何兼顾这些扩展?
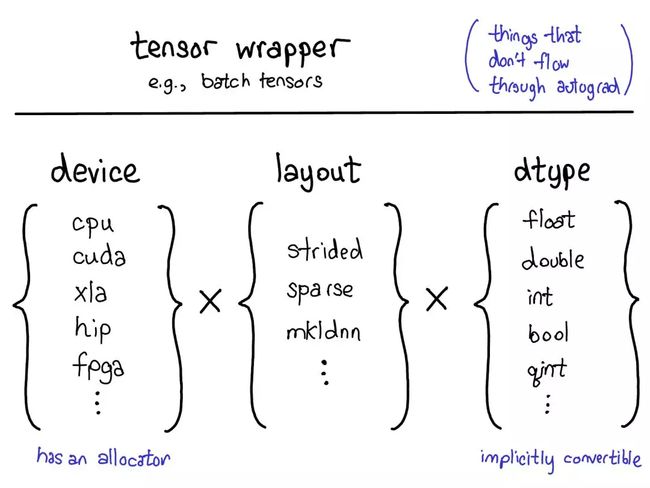
当前的用于扩展的模型提供了张量的四个扩展点。首先,有三个独立地确定张量类型的配套参数:
- device(设备):描述了实际存储张量的物理内存,比如在 CPU、英伟达 GPU(cuda)、AMD GPU(hip)或 TPU(xla)上。设备之间各不相同的特性是有各自自己的分配器(allocator),这没法用于其它设备。
- layout(布局):描述了对物理内存进行逻辑解读的方式。最常用的布局是有步幅的张量(strided tensor),但稀疏张量的布局不同,其涉及到一对张量,一个用于索引,一个用于数据;MKL-DNN 张量的布局更加奇特,比如 blocked layout,仅用步幅不能表示它。
- dtype(数据类型):描述了张量中每个元素实际存储的数据的类型,比如可以是浮点数、整型数或量化的整型数。
如果想为 PyTorch 张量添加一种扩展,应该思考想要扩展这些参数中的哪几种。这些参数的笛卡尔积定义了可以得到的所有可能的张量。现在,并非所有这些组合都有核(谁为 FPGA 上的稀疏量化张量用核?),但原则上这种组合可能有意义,因此至少应该支持表达它。
要为张量的功能添加「扩展」,还有最后一种方法,即围绕能实现的目标类型的 PyTorch 张量编写一个 wrapper(包装)类(这可能听起来理所当然,但有时候人们在只需要制作一个 wrapper 类时却跑去扩展那三个参数),wrapper 类的一个突出优点是开发结果可以完全不影响原来的类型(out of tree)。
何时应该编写张量 wrapper,而不是扩展 PyTorch 本身?
关键的指标是:是否需要将这个张量传递通过 autograd(自动梯度)反向通过过程。
举个例子,这个指标表示稀疏张量应该是一种真正的张量扩展,而不只是一种包含一个索引和值张量的 Python 对象:当在涉及嵌入的网络上执行优化时,想要嵌入生成稀疏的梯度。
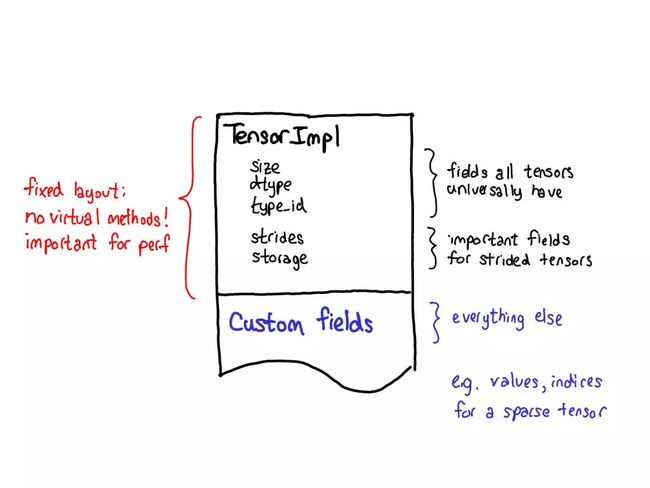
对扩展的理念也会影响张量本身的数据布局。对于张量结构,真正想要的一件事物是固定的布局:不想要基本操作(这个说法很常见),比如「一个张量的大小是多少?」来请求虚调度。
所以查看一个张量的实际布局时(定义为 TensorImpl 结构),会看到所有字段的一个公共前缀——认为所有类似「张量」的东西都会有;还有一些字段仅真正适用于有步幅的张量,但它们也很重要,所以将其保留在主结构中;然后可以在每个张量的基础上完成有自定义字段的后缀。比如稀疏张量可将其索引和值存储在这个后缀中。
自动梯度(autograd)
PyTorch 的显著特性是其在最初发布时就已提供对张量的自动微分(现在还有 TorchScript 等炫酷功能!)
这是负责运行神经网络的机制:

以及填充实际计算网络的梯度时所缺少的代码:

- 首先将你的目光投向红色和蓝色的变量。PyTorch 实现了反向模式自动微分,这意味着可以「反向」走过前向计算来有效地计算梯度。查看变量名就能看到这一点:在红色部分的底部,计算的是损失(loss);然后在这个程序的蓝色部分,第一件事是计算 grad_loss。loss 根据 next_h2 计算,这样可以计算出 grad_next_h2。从技术上讲,加了 grad_ 的变量其实并不是梯度,它们实际上左乘了一个向量的雅可比矩阵,但在 PyTorch 中,就称之为 grad。
- 如果代码的结构保持一样,而行为没有保持一样:来自前向的每一行都被替换为一个不同的计算,其代表了前向运算的导数。举个例子,tanh 运算被转译成了 tanh_backward 运算(这两行用图左边一条灰线连接)。前向和反向运算的输入和输出交换:如果前向运算得到 next_h2,反向运算就以 grad_next_h2 为输入。
autograd 的意义就在于执行这幅图所描述的计算,但却不用真正生成这个源。PyTorch autograd 并不执行源到源的变换(尽管 PyTorch JIT 确实知道如何执行符号微分(symbolic differentiation))。
文章中还提到了Variable,但是现在的版本以及将变量和张量融合,不再必需。
用PyTorch写代码所涉及的基本细节
如何在 autograd 代码中披荆斩棘、什么代码是真正重要的以及怎样造福他人,我还会介绍 PyTorch 为你写核(kernel)所提供的所有炫酷工具。
找到路径
PyTorch 有大量文件夹,在 CONTRIBUTING.md 文档中有对它们的非常详细的描述,实际上只需知晓 4 个目录:
- torch/ 包含:导入和使用的实际的 Python 模块。这些东西是 Python 代码而且易于操作(只需要进行修改然后查看结果即可)。但是,不可太过深入。【Python;the frontend】
- torch/csrc/:实现了在 Python 和 C++ 间转换的绑定代码(binding code);另外还有一些相当重要的 PyTorch 部分,比如 autograd 引擎和 JIT 编译器。它也包含 C++ 前端代码。【Python binding,this functionality(api/ ;autograd/;jit/)】
- aten/:这是「A Tensor Library」的缩写(由 Zachary DeVito 命名),是一个实现张量运算的 C++ 库。检查某些核代码所处的位置,很可能就在 ATen。ATen 本身就分为两个算子区域:「原生」算子(算子的现代的 C++ 实现)和「传统」算子(TH、THC、THNN、THCUNN),这些是遗留的 C 实现。传统的算子是其中糟糕的部分;如果可以,请勿在上面耗费太多时间。
- c10/:这是「Caffe2」和「A"Ten"」的双关语,包含 PyTorch 的核心抽象,包括张量和存储数据结构的实际实现。
找代码需要看很多地方;应该简化目录结构,就是这样。如果想研究算子,应该在 aten 上花时间。
实践中如何分离这些代码的:

当调度一个函数,比如torch.add:
- 必须从 Python 国度转换到 C++ 国度(Python 参数解析)。
- 处理变量调度(VariableType—Type,顺便一提,和编程语言类型并无特别关联,只是一个用于执行调度的小工具)。
- 处理设备类型/布局调度(Type)。
- 有实际的核,这要么是一个现代的原生函数,要么是传统的 TH 函数。
其中每一步都具体对应于一些代码:

在 C++ 代码中的起始着陆点是一个 Python 函数的 C 实现,已经在 Python 那边见过它,像是 torch._C.VariableFunctions.add。THPVariable_add 就是这样一个实现。
对于这些代码,有一点很重要:这些代码是自动生成的。如在 GitHub 库中搜索,没法找到它们,因为必须实际 build PyTorch 才能看到它们。
另外一点也很重要:不需要真正深入理解这些代码是在做什么,应该快速浏览它,知道它的功能。
在上面用蓝色标注了最重要的部分:可以看到这里使用了一个 PythonArgParser 类来从 Python args 和 kwargs 取出 C++ 对象;然后调用一个 dispatch_add 函数(红色内联);这会释放全局解释器锁,然后调用在 C++ 张量自身上的一个普通的旧方法。在其回来的路上,将返回的 Tensor 重新包装进 PyObject。

在 Tensor 类上调用 add 方法时,还没有虚调度发生。相反,有一个内联方法,其调用了一个内联方法,其会在「Type」对象上调用一个虚方法。这个方法是真正的虚方法(这就是说 Type 只是一个实现动态调度的「小工具」的原因)。
在这个特定案例中,这个虚调用会调度到在一个名为 TypeDefault 的类上的 add 的实现。这刚好是因为有一个对所有设备类型(CPU 和 CUDA)都一样的 add 的实现;如果刚好有不同的实现,可能最终会得到 CPUFloatType::add 这样的结果。正是这种虚方法的实现能让最终得到实际的核代码。
也希望这张幻灯片很快过时;Roy Li 正在研究使用另一种机制替代 Type 调度,这能让更好地在移动端上支持 PyTorch。
编写kernel
PyTorch 为有望编写核的人提供了大量有用工具。
编写核需要?

一般将 PyTorch 中的核看作由以下部分组成:
- 首先有一些有关核的元数据,这能助力代码生成并获取所有与 Python 的捆绑包,同时无需写任何一行代码。
- 一旦到达了核,就经过了设备类型/布局调度。首先需要写的是错误检查,以确保输入的张量有正确的维度。(错误检查真正很重要!不要吝惜!)
- 接下来,一般必须分配将要写入输出的结果张量。
- 该到写核的时候了。现在应该做第二次 dtype 调度,以跳至其所操作的每个 dtype 特定的核。(不应该过早调度,这样就会毫无用处地复制在任何情况下看起来都一样的代码。)
- 大多数高性能核都需要某种形式的并行化,这样就能利用多 CPU 系统了。(CUDA 核是「隐式」并行化的,因为它们的编程模型构建于大规模并行化之上。)
- 最后,需要读取数据并执行计算!

要充分利用 PyTorch 的代码生成能力,需要为算子写一个模式(schema)。这个模式能提供函数的 mypy 风格类型,并控制是否为 Tensor 上的方法或函数生成捆绑包。还可以告诉模式针对给定的设备-布局组合,应该调用算子的哪种实现。
有关这种格式的更多信息,请参阅:https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/README.md
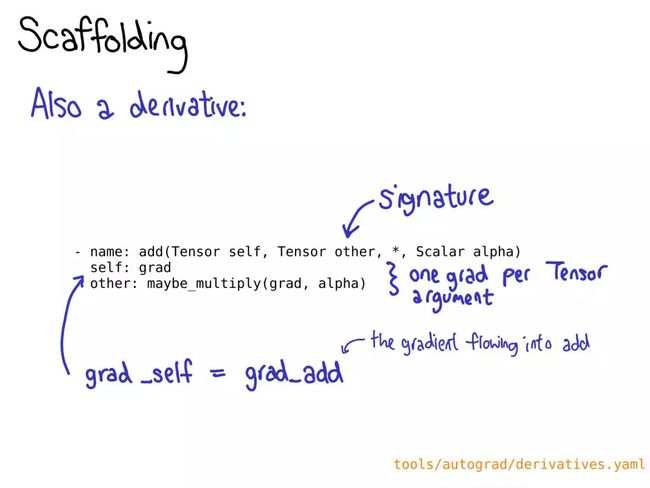
可能也需要为在 derivatives.yaml 中的操作定义一个导数。

错误检查可以在低层 API 完成,也能通过高层 API 实现。低层 API 只是一个宏 TORCH_CHECK,其接收的是一个布尔值,然后还有任意数量的参数构成错误字符串(error string)以便得出结论看该布尔值是否为真。
这个宏有个很好的地方:可以将字符串与非字符串数据混合起来;每一项都使用它们的 operator<< 实现进行格式化,PyTorch 中大多数重要的数据类型都有 operator<< 实现。
高层 API 能免于反复编写重复的错误消息。其工作方法是:首先将每个张量包装为 TensorArg,这包含有关张量来处的信息(比如其参数名称)。然后它提供了一些预先装好的用于检查多种属性的函数;比如 checkDim() 测试的是张量的维度是否是一个固定数值。如果不是,该函数就基于 TensorArg 元数据提供一个用户友好的错误消息。

在用 PyTorch 写算子时,有一点很重要:往往要注册三个算子:abs_out(其操作的是一个预分配的输出,其实现了 out= keyword 参数)、abs_(其操作的是 inplace)、abs(这只是一个算子的普通的旧功能版本)。
大部分时间,abs_out 是真正的主力,abs 和 abs_ 只是围绕 abs_out 的薄弱 wrapper;但有时候也可为每个案例编写专门的实现。

要执行 dtype 调度,应该使用 AT_DISPATCH_ALL_TYPES 宏。这会获取进行调度操作的张量的 dtype,并还会为可从该宏调度的每个 dtype 指定一个 lambda。通常而言,这个 lambda 只是调用一个模板辅助函数。
这个宏不只是「执行调度」,它也会决定核将支持的 dtype。这样,这个宏实际上就有相当多一些版本,这能选取不同的 dtype 子集以生成特定结果。大多数时候只需要 AT_DISPATCH_ALL_TYPES,但也要关注可能需要调度其它更多类型的情况。

在 CPU 上,通常需要并行化代码。过去,这通常是通过直接在代码中添加 OpenMP pragma 来实现。

某些时候,必须真正访问数据。PyTorch 为此提供了相当多一些选择。
- 如果只想获取某个特定位置的值,使用 TensorAccessor。张量存取器就像是一个张量,但它将张量的维度和 dtype 硬编码为了模板参数。当检索一个存取器时,比如 x.accessor
- ();,做一次运行时间测试以确保张量确实是这种格式;但那之后,每次存取都不会被检查。张量存取器能正确地处理步幅,因此最好使用它们,而不是原始的指针访问(不幸的是,很多传统的核是这样做的)。另外还有 PackedTensorAccessor,这特别适用于通过 CUDA launch 发送存取器,这样就能从CUDA 核内部获取存取器。(一个值得一提的问题:TensorAccessor 默认是 64 位索引,这比 CUDA 中的 32 位索引要慢得多!)
- 如果用很常规的元素存取编写某种算子,比如逐点运算,那么使用远远更高级的抽象要好得多,比如 TensorIterator。这个辅助类能自动处理广播和类型提升(type promotion),相当好用。
- 要在 CPU 上获得真正的速度,需要使用向量化的 CPU 指令编写核。也有用于这方面的辅助函数!Vec256 类表示一种标量向量,并提供了一些能在它们上一次性执行向量化运算的方法。然后 binary_kernel_vec 等辅助函数能轻松地运行向量化运算,然后结束那些没法用普通的旧指令很好地转换成向量指令的东西。这里的基础设施还能在不同指令集下多次编译你的核,然后在运行时间测试CPU 支持什么指令,再在这些情况中使用最佳的核。

PyTorch 中大量核都仍然是用传统的 TH 风格编写的。(顺便一提,TH 代表 TorcH。这是个很好的缩写词,但很不幸被污染了;如果你看到名称中有 TH,可认为它是传统的。)传统 TH 风格是什么意思呢? - 它是以 C 风格书写的,没有(或很少)使用 C++。
- 其 refcounted 是人工的(使用了对 THTensor_free 的人工调用以降低你使用张量结束时的 refcounts)。
- 其位于 generic/ 目录,这意味着我们实际上要编译这个文件很多次,但要使用不同的 #define scalar_t
这种代码相当疯狂,请不要添加它。如果你想写代码但对核编写了解不多,能做的一件有用的事情:将某些 TH 函数移植到 ATen。
工作流程效率
如果 PyTorch 那庞大的 C++ 代码库是阻拦人们为 PyTorch 做贡献的第一只拦路虎,那么工作流程的效率就是第二只。如果想用 Python 习惯开发 C++,那可能会很艰辛:重新编译 PyTorch 需要大量时间,也需要大量时间才能知道修改是否有效。
- 如果编辑一个 header,尤其是被许多源文件包含的 header(尤其当被 CUDA 文件包含时),可以预见会有很长的重新 build 时间。尽量只编辑 cpp 文件,编辑 header 要审慎!
- CI 是一种非常好的零设置的测试修改是否有效的方法。但在获得返回信号之前可能需要等上一两个小时。如果在进行一种将需要大量实验的改变,那就花点时间设置一个本地开发环境。类似地,如果在特定的 CI 配置上遇到了困难的 debug 问题,就在本地设置它。可以将 Docker 镜像下载到本地并运行:https://github.com/pytorch/ossci-job-dsl
- 贡献指南解释了如何设置 ccache:https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md#use-ccache ;强烈建议这个,因为这可以在编辑 header 时幸运地避免大量重新编译。当不应该重新编译文件时重新编译时,这也能帮助覆盖 build 系统的漏洞。
- 最后,会有大量 C++ 代码。如果是在一台有 CPU 和 RAM 的强大服务器上 build,那么会有很愉快的体验。特别要说明,不建议在笔记本电脑上执行 CUDA build。build CUDA 非常非常慢,而笔记本电脑往往性能不足,不足以快速完成。
原文地址:http://blog.ezyang.com/2019/05/pytorch-internals/