acm-根号分治在各个领域的应用
引言
对于acm常有一些题目让人十分棘手,并且没有专门的
算法来解决这些问题。这时候一般都最好从暴力着手来
思考解决方案,而根号分治可以说是一种优雅的暴力。
本文将通过例题的方式从各个领域来剖析根号分治的核心思想。
图论
例题一
题目来源:2020上海高校程序设计竞赛暨第18届上海大学程序设计联赛夏季赛(同步赛)D题:旅行

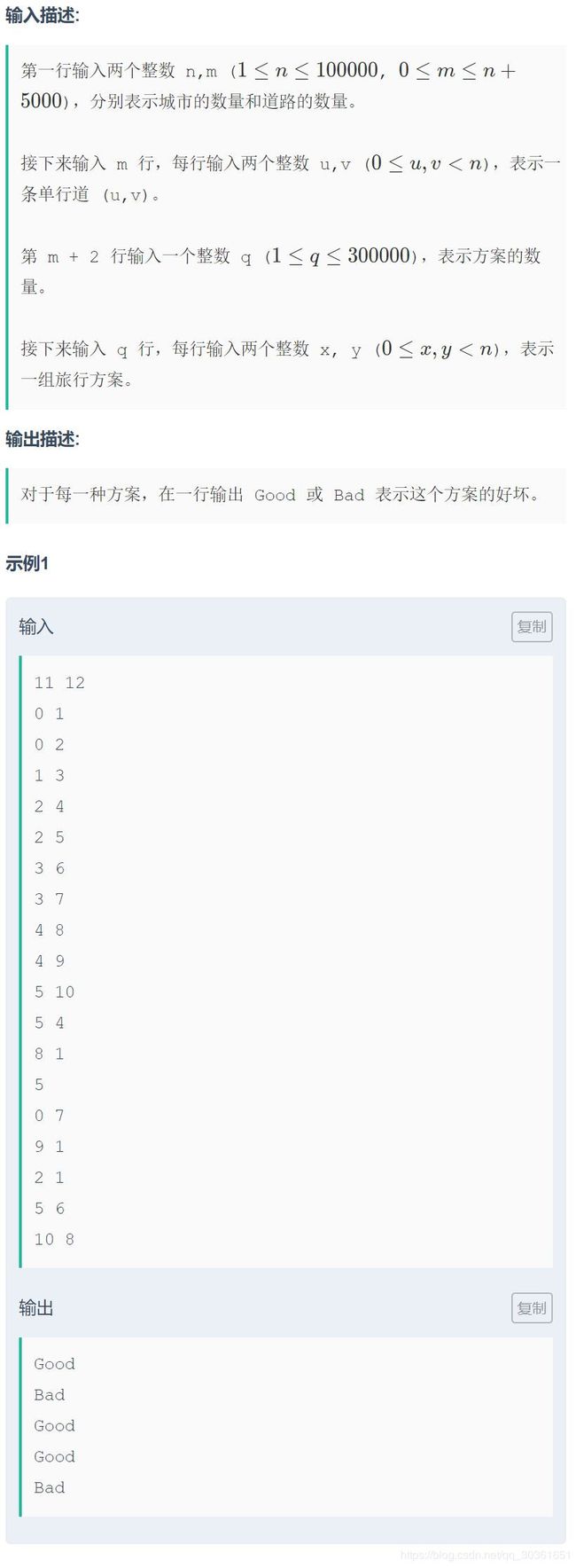
简化题意:给定一张n<=100000个点,m<=n+5000条边的有向图(随机生成)和q<=300000个询问,每次询问u点是否能够到达v点,能输出Good,否则Bad
题解:最直接的想法就是先对整个有向图进行缩点处理,如果查询的两个点都位于同一个强联通分量内就输出Good,否则再缩点后的图的基础上从u点dfs深搜,看是否能够到达v点。分析一下纯暴力的时间复杂度:连通块的数量最多可达n个,每次查询最坏情况要遍历所有的连通块,因此复杂度是 O ( q n ) \mathbf{O(qn)} O(qn),数量级达到了 3 e 10 \mathbf{3e10} 3e10,显然不可取。
这时候我们考虑根号分治的思想。从所有点中选定 t o t \mathbf{\sqrt{tot}} tot(tot代表连通块个数)个度数最大的点,然后对这些点暴力预处理出它们可以到达的图中的所有点。可以为这些预处理点都开一个集合,然后将它们能够到达的点存入相应地集合中。然后对于每次询问(u,v),直接从u点暴力dfs深搜,遇到v点就返回true,遇到已经预处理过的点就查询该点对应集合中是否存在点v,有的话返回true,否则返回false。
分析一下这种做法的复杂度:由于数据随机的特性,最坏情况假设连通块个数等于点个数,平均深搜 n \mathbf{\sqrt n} n个点就能遇到一个预处理过的点,每个点的度数的期望应该是 2 m n ≈ 2 \mathbf{\frac{2m}{n}\approx 2} n2m≈2,相当于是一根直线,也就是说期望每次询问最跑 2 n \mathbf{2\sqrt n} 2n个点能够确定答案,所以期望复杂度应该是 O ( 2 q n ) \mathbf{O(2q\sqrt n)} O(2qn),数量级约为 1.8 ∗ 1 0 8 \mathbf{1.8*10^8} 1.8∗108,能过本题,由于这是按照最坏的情况进行分析得出的期望,实际运行效率会远远高于此,具体看代码中的注释。
代码实现:
\\加入vis优化后(避免点的重复访问)运行速度实测为734ms
#include 例题二
待续。。。