深度学习PyTorch | 文本预处理,语言模型,循环神经网络
文本预处理
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
- 读入文本
- 分词
- 建立字典,将每个词映射到一个唯一的索引(index)
- 将文本从词的序列转换为索引的序列,方便输入模型
spaCy分词:
import spacy
nlp = spacy.load('en_core_web_sm')
text = "Mr. Chen doesn't agree with my suggestion."
doc = nlp(text)
print([token.text for token in doc])
# ['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']NLTK分词:
from nltk.tokenize import word_tokenize
from nltk import data
data.path.append('/home/kesci/input/nltk_data3784/nltk_data')
print(word_tokenize(text))
#['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']语言模型
一段自然语言文本可以看作是一个离散时间序列,给定一个长度为TT的词的序列w1,w2,…,wTw1,w2,…,wT,语言模型的目标就是评估该序列是否合理,即计算该序列的概率:
![]()
n元语法
序列长度增加,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。n元语法通过马尔可夫假设简化模型,马尔科夫假设是指一个词的出现只与前面n个词相关,即n阶马尔可夫链(Markov chain of order nn),如果n=1,那么有P(w3∣w1,w2)=P(w3∣w2)P(w3∣w1,w2)=P(w3∣w2)。
基于n−1n−1阶马尔可夫链,我们可以将语言模型改写为
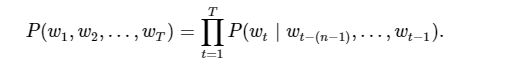
以上也叫nn元语法(nn-grams),它是基于n−1n−1阶马尔可夫链的概率语言模型。例如,当n=2n=2时,含有4个词的文本序列的概率就可以改写为:

当nn分别为1、2和3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。例如,长度为4的序列w1,w2,w3,w4w1,w2,w3,w4在一元语法、二元语法和三元语法中的概率分别为:
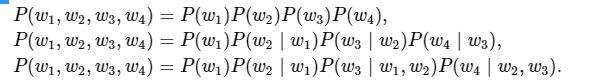
随机采样
每次从数据里随机采样一个小批量。其中批量大小batch_size是每个小批量的样本数,num_steps是每个样本所包含的时间步数。 在随机采样中,每个样本是原始序列上任意截取的一段序列,相邻的两个随机小批量在原始序列上的位置不一定相毗邻。
相邻采样
在相邻采样中,相邻的两个随机小批量在原始序列上的位置相毗邻。
循环神经网络
循环神经网络引入一个隐藏变量HH,用HtHt表示HH在时间步tt的值。Ht的计算基于Xt和Ht−1,可以认为Ht记录了到当前字符为止的序列信息,利用Ht对序列的下一个字符进行预测。
循环神经网络的构造
