Python源码分析2 - 一个简单的Python程序的执行
本文主要通过跟踪一个非常简单的Python程序的执行,简单讨论Python实现的基本框架和结构。
要执行Python程序如下,功能非常简单:从1加到10再打印出来
| # test program sum = 0 for i in range(1, 11): sum = sum + i print sum |
如果想要在Windows下面用VS 2005调试Python,可以通过下面步骤设置:
- 把Startup Project设置成Python,这样就可以直接通过F5来启动Python
- 右键单击Python这个Project,选择Properties。在对话框中的Configuration Properties->Debugging下面,把Command Arguments设置为-d test.py。其中test.py就是我们所要调试程序的名字。-d表示打开调试开关,可以看到额外的调试信息。
好了,设置完毕之后可以直接按下F10来单步追踪该程序的执行了。
首先,F10,启动程序,可以看到Python的main函数中没有什么内容,只是简单的调用Py_Main。Py_Main顾名思义自然是主函数了,分几大部分:
- 分析命令行和环境变量
- 调用Py_Initialize初始化
- 根据命令行的内容执行进入不同的执行模式
| if (command) { sts = PyRun_SimpleStringFlags(command, &cf) != 0; free(command); } else if (module) { sts = RunModule(module); free(module); } else { if (filename == NULL && stdin_is_interactive) { RunStartupFile(&cf); } /* XXX */ sts = PyRun_AnyFileExFlags( fp, filename == NULL ? " filename != NULL, &cf) != 0; } |
从上面的代码可以很容易看出,一共有3种执行方式:
-
- Command模式,执行单条Python语句。通过-c指定。语句内容存放在command变量中。调用PyRun_SimpleStringFlags来执行。
- Module模式,执行整个Module。通过-m指定。调用RunModule来执行。
- File模式,执行Python源程序和交互都归在此类。可以看到,如果未指定文件名并且stdin是交互的话,会执行一个PYTHONSTARTUP所指定的源程序。
4. 最后调用Py_Finalize结束
这里我们关注的主要对象自然是PyRun_AnyFileExFlags,其内容如下:
| /* Parse input from a file and execute it */
int PyRun_AnyFileExFlags(FILE *fp, const char *filename, int closeit, PyCompilerFlags *flags) { if (filename == NULL) filename = "???"; if (Py_FdIsInteractive(fp, filename)) { int err = PyRun_InteractiveLoopFlags(fp, filename, flags); if (closeit) fclose(fp); return err; } else return PyRun_SimpleFileExFlags(fp, filename, closeit, flags); } |
首先判断文件是否是交互的,如果是,则调用PyRun_InteractiveLoopFlags(fp, filename, flags),否则调用PyRun_SimpleFlagExFlags。PyRun_InteractiveLoopFlags和PyRun_SimpleFileExFlags基本上区别不大,本质上作的事情都是一样,只不过一个是以语句为单位执行,一个是以程序为单位来执行。所以这里还是以分析PyRun_SimpleFileExFlags为主。
| int PyRun_SimpleFileExFlags(FILE *fp, const char *filename, int closeit, PyCompilerFlags *flags) { PyObject *m, *d, *v; const char *ext;
m = PyImport_AddModule("__main__"); if (m == NULL) return -1; d = PyModule_GetDict(m); if (PyDict_GetItemString(d, "__file__") == NULL) { PyObject *f = PyString_FromString(filename); if (f == NULL) return -1; if (PyDict_SetItemString(d, "__file__", f) < 0) { Py_DECREF(f); return -1; } Py_DECREF(f); } ext = filename + strlen(filename) - 4; if (maybe_pyc_file(fp, filename, ext, closeit)) { /* Try to run a pyc file. First, re-open in binary */ if (closeit) fclose(fp); if ((fp = fopen(filename, "rb")) == NULL) { fprintf(stderr, "python: Can't reopen .pyc file/n"); return -1; } /* Turn on optimization if a .pyo file is given */ if (strcmp(ext, ".pyo") == 0) Py_OptimizeFlag = 1; v = run_pyc_file(fp, filename, d, d, flags); } else { v = PyRun_FileExFlags(fp, filename, Py_file_input, d, d, closeit, flags); } if (v == NULL) { PyErr_Print(); return -1; } Py_DECREF(v); if (Py_FlushLine()) PyErr_Clear(); return 0; } |
可以看到此函数主要的作的事情是:
- 创建Module __main__,任何Python脚本都会自动属于__main__
- 设置__file__为当前文件名字
- 检查是否为.pyc / .pyo文件。Maybe_pyc_file会根据文件的扩展名和文件内容的头两个字节是否为0xf2b3来判断是否是pyc/pyo文件。如果是pyc或者pyo,调用run_pyc_file来直接执行Python的Bytecode。
- 否则,调用PyRun_FileExFlags来执行Python的源程序
Run_pyc_file不是本文分析的重点,我们还是先来看一下PyRun_FileExFlags这个函数:
| PyObject * PyRun_FileExFlags(FILE *fp, const char *filename, int start, PyObject *globals, PyObject *locals, int closeit, PyCompilerFlags *flags) { PyObject *ret; mod_ty mod; PyArena *arena = PyArena_New(); if (arena == NULL) return NULL;
mod = PyParser_ASTFromFile(fp, filename, start, 0, 0, flags, NULL, arena); if (mod == NULL) { PyArena_Free(arena); return NULL; } if (closeit) fclose(fp); ret = run_mod(mod, filename, globals, locals, flags, arena); PyArena_Free(arena); return ret; } |
这个函数非常简单,但是却涵盖了整个Python源程序的运行的过程:
- 创建一个Arena对象。此对象是用于内存分配用的,维护分配的原始内存和PyObject对象。
- 调用PyParser_ASTFromFile。 此函数会通过词法分析和语法分析得到源程序所对应的AST(Abstract Syntax Tree)。
- 调用Run_mod
- 释放Arena
PyParser_ASTFromFile的代码如下:
| mod_ty PyParser_ASTFromFile(FILE *fp, const char *filename, int start, char *ps1, char *ps2, PyCompilerFlags *flags, int *errcode, PyArena *arena) { mod_ty mod; perrdetail err; node *n = PyParser_ParseFileFlags(fp, filename, &_PyParser_Grammar, start, ps1, ps2, &err, PARSER_FLAGS(flags)); if (n) { mod = PyAST_FromNode(n, flags, filename, arena); PyNode_Free(n); return mod; } else { err_input(&err); if (errcode) *errcode = err.error; return NULL; } } |
首先,PyParser_ParseFileFlags分析文件,生成CST(Concrete Syntax Tree)并将其根结点放到node*之中。Node的结构如下:
| typedef struct _node { short n_type; char *n_str; int n_lineno; int n_col_offset; int n_nchildren; struct _node *n_child; } node; |
n_type代表着语法树的结点的类型,对应着Python-2.5/Grammar/Grammar文件中的文法中的终结符/非终结符,主要在graminit.h和token.h中定义。在后面的文章中会详述。N_str则是对应的字符串的内容。N_lineno / n_col_offset分别代表对应行号和列号。最后的两个n_nchildren和n_child表示此节点共有n_nchildren个子结点。
下面的函数可以用来访问node。大部分的函数都无需解释,除了RCHILD,RCHILD表示从右往左第几个,i给负值。比如RCHILD(n, -1)就是从右往左第一个结点。
| /* Node access functions */ #define NCH(n) ((n)->n_nchildren)
#define CHILD(n, i) (&(n)->n_child[i]) #define RCHILD(n, i) (CHILD(n, NCH(n) + i)) #define TYPE(n) ((n)->n_type) #define STR(n) ((n)->n_str) |
文中的Python程序的CST看起来大致是这样的:
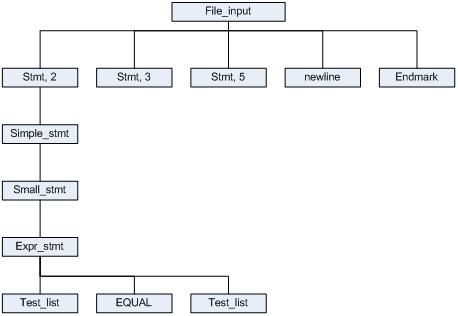
图中省略了很多细节,因为是CST的关系,分析过程中有大量冗余信息,主要是每一步通过DFA分析的结点都列在这棵树里面了。由于篇幅的关系就不把整棵树画出来了。
那么CST是怎么生成的呢?在PyParser_ParseFileFlags中:
| node * PyParser_ParseFileFlags(FILE *fp, const char *filename, grammar *g, int start, char *ps1, char *ps2, perrdetail *err_ret, int flags) { struct tok_state *tok;
initerr(err_ret, filename);
if ((tok = PyTokenizer_FromFile(fp, ps1, ps2)) == NULL) { err_ret->error = E_NOMEM; return NULL; } tok->filename = filename; if (Py_TabcheckFlag || Py_VerboseFlag) { tok->altwarning = (filename != NULL); if (Py_TabcheckFlag >= 2) tok->alterror++; }
return parsetok(tok, g, start, err_ret, flags); } |
PyParser_ParserFileFlags首先创建tok_state,也就是词法分析器的对象,之后调用parsetok。Parsetok的代码量稍多,这里就不全部列出来了。主干代码如下:
| static node * parsetok(struct tok_state *tok, grammar *g, int start, perrdetail *err_ret, int flags) { parser_state *ps; node *n; int started = 0, handling_import = 0, handling_with = 0;
ps = PyParser_New(g, start);
for (;;) { type = PyTokenizer_Get(tok, &a, &b); if ((err_ret->error = PyParser_AddToken(ps, (int)type, str, tok->lineno, col_offset, &(err_ret->expected))) != E_OK) { if (err_ret->error != E_DONE) { PyObject_FREE(str); err_ret->token = type; } break; } }
if (err_ret->error == E_DONE) { n = ps->p_tree; ps->p_tree = NULL; } else n = NULL;
PyParser_Delete(ps);
if (n == NULL) { // error processing } else if (tok->encoding != NULL) { node* r = PyNode_New(encoding_decl); if (!r) { err_ret->error = E_NOMEM; n = NULL; goto done; } r->n_str = tok->encoding; r->n_nchildren = 1; r->n_child = n; tok->encoding = NULL; n = r; }
done: PyTokenizer_Free(tok);
return n; } |
里面最重要的是两个函数调用:
- PyTokenizer_Get,是用来进行词法分析的,把源程序分解为Token的序列(比如变量名,运算符,关键字等都属于Token)
- PyParser_AddToken,把Token加入到DFA状态机中进行语法分析,根据当前的状态和输入的Token,根据跳转表跳转到不同的状态,并依照这个过程生成CST
由于篇幅有限,这个两个函数的实现细节会在以后的文章详细分析。
在PyParser_ParserFileFlags得到了语法树之后,PyAST_FromNode会将CST转换为AST,存入mod_ty中。
| typedef _mod *mod_ty;
struct _mod { enum _mod_kind kind; union { struct { asdl_seq *body; } Module;
struct { asdl_seq *body; } Interactive;
struct { expr_ty body; } Expression;
struct { asdl_seq *body; } Suite;
} v; }; |
_mod是AST的根结点,代表整个Module。在Python-ast.h中定义着所有AST结点的结构,mod_ty和expr_ty也在其中,后者显然代表着一个表达式。
adsl_seq代表一个变长的指针数组,结构定义如下:
| typedef struct { int size; void *elements[1]; } asdl_seq; |
这个结构稍微有些特殊的是elements在struct中只有一个元素。其实这个struct可以支持任意多个元素,正因为如此,普通的定义方法是不行的。因此这里只定义一个元素,然后在分配计算实际的大小(会比adsl_seq这个结构要大),然后访问元素的时候直接用elements,因为C/C++是不会检查越界的。这种做法在C/C++系统编程中还是比较常见的。
Adsl_seq粗看上去只保存了void *,也就是说具体类型信息丢失了,那么当要遍历整个树的时候是如何做的呢?其实当遍历到某个结点(比如Module/Expression)的时候,便可以确定该结点所支持的子结点是什么类型,然后直接转强制转换就可以了。还有一种情况是在结点中直接记录的是具体的有类型的AST结点,比如expr_ty,就更加容易了。
文中Python代码对应的AST大致如下:

同样的,也省略了一些细节。可以看到,最终的结果要比CST要少很多,比较接近源代码本来的样子。
当PyParser_ASTFromFile执行完毕之后,回到PyRun_FileExFlags,执行下一步,调用run_mod,也就是执行这颗AST所代表的程序。
| static PyObject * run_mod(mod_ty mod, const char *filename, PyObject *globals, PyObject *locals, PyCompilerFlags *flags, PyArena *arena) { PyCodeObject *co; PyObject *v; co = PyAST_Compile(mod, filename, flags, arena); if (co == NULL) return NULL; v = PyEval_EvalCode(co, globals, locals); Py_DECREF(co); return v; } |
Run_mod非常直接,分两步走:
- 编译AST,生成PyCodeObject对象,也就是ByteCode。
- 调用PyEval_EvalCode执行PyCodeObject,也就是通过VM直接执行bytecode。如果是执行.pyc/.pyo代码的话,直接从文件中读出信息创建好PyCodeObject对象就可以直接执行了,也是调用这个函数。
执行完PyEval_EvalCode之后可以看到55被打印出来了。
总结一下,Python执行程序的过程总共有以下几步:
- Tokenizer进行词法分析,把源程序分解为Token
- Parser根据Token创建CST
- CST被转换为AST
- AST被编译为字节码
- 执行字节码
后面的文章中我会对1~5这5步分别进行详细分析,今天就先写到这里。
作者: ATField
E-Mail: [email protected]
Blog: http://blog.csdn.net/atfield