2019-ICCV最佳论文解读-SinGAN: Learning a Generative Model from a Single Natural Image
2019-ICCV最佳论文-SinGAN: Learning a Generative Model from a Single Natural Image
作者: Tamar Rott Shaham Tali Dekel Tomer Michaeli
一句话概括论文:作者用了一个称之为金字塔的网络模型来对单张图片操作,可以实现随机生成类似图片、提高分辨率、画图转换为图片等功能。
(为了方便你们看,我直接把原文用有道翻译的,很多地方不准确,我只改了我看到的地方。感觉不对的你们可以去看原文。另外有一些复杂公式我就直接截图了)
先上一个图吧,也就是作者放在abstract上面的图,猛一看感觉很神奇:
最左边那张是训练图片,然后右边的都是生成的不同宽高的图片,如果你说不都一样吗?那说明你已经被骗了,哈哈。。你再仔细看下,其实虽然都看着合理,但是都是不一样的。
接下来就开始正式说论文吧。
Abstract
我们介绍了SinGAN,一个可以从单一自然图像中学习的无条件生成模型。我们的模型经过训练,能够捕捉图像内部patch的分布,然后能够生成与图像具有相同视觉内容的高质量、多样化的样本。SinGAN包含一个完全卷积的GANs金字塔,每个GANs负责学习图像中不同尺度上的patch分布。这允许生成具有显著可变性的任意大小和高宽比的新样本,同时保持训练图像的整体结构和精细纹理。与以往的单一图像GAN方案相比,我们的方法不仅限于纹理图像,而且没有条件(即从噪声中生成样本)。用户研究证实,生成的样本通常被混淆为真实的即时消息。我们说明了SinGAN在图像处理任务中的广泛应用。
解释:
patch:就是图片中的一小部分的意思。之前的Gan都是把整张图片作为训练对象,但是SinGan是把生成图像的一小块来和输入的训练图像比较,这就是作者的创新之处。
其他就是比较容易理解的了。
如果你不知道Gan网络是啥的的话,那我这就通俗的解释下吧。
Generative Adversarial Nets (GANs),生成对抗网络,是目前最厉害的吧。有很多的对最初的模型的更改,去github一搜一大堆。之前VAE还可以,但是Gan出来之后就都是Gan的天下了
我用个例子解释Gan网络吧:
以前有一对兄弟,但是他们差别却很大。
弟弟从小就喜欢模仿别人作画,而哥哥呢不喜欢画画,但是对画的鉴别却很有造诣。
这里弟弟就是生成器,哥哥就是鉴别器。
弟弟刚开始看到真画之后就开始模仿着画,而哥哥呢,他是先观察真画是什么样子。然后弟弟画完画之后就把画拿给哥哥看,于是哥哥就试试能不能看出来弟弟画的画是假画。
LOSS函数就是:

我直接用这个题的来说了,G是生成模型,D是鉴别模型。作者要做的就是让生成模型不断接近真的,让鉴别模型不断训练能够识别真的是真的,并且识别G网络生成的是假的。中间的差值就是LOSS。
在口语化点就是让生成器生成的图片越来越像真的,让鉴别器能鉴别真的图片是真的图片的同时鉴别生成器的图片是假的。就是生成器做了一份工作,鉴别器做了两份工作。既要学习什么是真的又要学习什么是假的。就这样,,,pass
Introduction
在这里,我们将GANs的使用带入了一个新的领域——从单个自然图像中学习的无条件生成。具体地说,我们证明了单个自然图像中patch的内部统计信息通常能够提供足够的信息来学习一个强大的生成模型。我们新的单一图像生成模型SinGAN允许我们处理包含复杂结构和纹理的一般自然图像,而不需要依赖于来自同一类图像的数据库。这是通过一个完全卷积的轻量级GANs金字塔来实现的,每个GANs负责捕获不同规模的补丁分布。一旦经过训练,SinGAN可以生成不同的高质量图像样本(任意维度),这些样本在语义上与训练图像相似,但包含新的对象配置和结构(图1)。
在许多计算机视觉任务中,对单个自然图像中patch的内部分布进行建模一直被认为是一个重要的先验问题[64]。经典的例子包括去噪[65],去模糊[39],超分辨率[18],去雾[2,15],图像编辑[37,21,9,11,50]。在这种情况下,最接近的相关工作是[48],其中定义并优化了一个双向patch相似度度量,以保证处理后的图像的patch与原始图像的patch是相同的。
在这些工作的激励下,我们在这里展示了如何在一个简单的统一学习框架中使用SinGAN来解决各种图像处理任务,包括从一张图像到另一张图像、编辑、协调、超分辨率和动画。在这些情况下,我们的模型产生了高质量的结果,保持了训练图像的内部patch统计(见图2和我们的项目网页)。所有的任务都是在相同的生成网络中完成的,没有任何额外的信息或原始训练图像之外的进一步训练。处理后的图像与原始图像相同。
这主要就是提了下作者是利用一张图片的内部patch训练来实现的,并提出了SinGan的功能包括图像、编辑、协调、超分辨率和动画。详细的在下面介绍。
1.Related Work
最近的一些工作提出了“过度拟合”一个深模型到一个单一的训练例子[51,60,46,7,1]。然而,这些方法是为特定的任务设计的(例如,超分辨率[46],纹理扩展[60])。Shocher等人[44,45]首先提出了针对单个自然图像的内部GAN模型,并在重定向的背景下进行了说明。然而,它们的产生是基于一个输入图像的。,将图像映射到图像),而不是用来绘制随机样本。相比之下,我们的框架是纯生成的(即将噪声映射到图像样本),因此适合许多不同的图像处理任务。无条件的单图像甘斯仅在纹理生成的环境中被探索过[3,27,31]。在对非纹理图像进行训练时,这些模型不会生成均值样本(图3)。而我们的方法不局限于纹理,可以处理一般的自然图像(如图1)。
在许多不同的图像处理任务中,最近基于gan的方法已经证明了对抗性学习的力量[61、10、62、8、53、56、42、53]。例如交互式图像编辑[61,10]、sketch2image[8,43],以及其他图像到图像的翻译任务[62,52,54]。然而,所有这些方法都是在类特定的数据集上训练的,而且在这里,也经常在另一个输入信号上条件生成。我们不感兴趣的是捕获同一类图像之间的共同特征,而是考虑不同的训练数据来源——单个自然图像的多个尺度上的所有重叠补丁。我们证明了一个强大的生成模型可以从这些数据中学习,并可用于许多图像处理任务。
介绍了一下前人工作的不足。又强调了自己是从单一图像生成的。
2. Method
我们的目标是学习一个无条件生成模型,它可以捕获单个训练图像x的内部统计信息。这个任务在概念上与传统的GAN设置类似,只是这里的训练样本是单个图像的patch,而不是来自数据库的整个图像样本。
我们选择超越纹理生成,处理更一般的自然图像。这需要捕获许多不同尺度的复杂图像结构的统计信息。例如,我们希望捕获全局属性,例如图像中大型对象的排列和形状(例如顶部的天空,底部的地面),以及精细的细节和纹理信息。实现这个目标,我们生成框架,说明了在图4中,由一个层次patch-GANs(马尔可夫链的鉴别器)(31,26),其中每个负责捕获块分布在不同scale的x,网络有着小的对比检测域,阻止他们记忆单一的形象。虽然类似的多尺度古构造已经在传统的GAN环境中被探索过(例如[28,52,29,52,13,24]),我们是第一个探索单一图像内部学习的。
作者介绍了模型是无条件的,
2.1.Multi-scale architecture(重点)


然后因为有很多公式,我就不用有道翻译了,你们自己看吧。接下来我就直接讲讲作者这个网络的主要意思了。话不多说,上图!
左边的生成器一开始通过一个高斯噪声来生成,刚开始的patch为高度的二分之一左右,并且保持横纵比。然后把生成的模糊图像upsample,刚开始的图像时很小的,比如是25px,然后每一次upsample都会变为4/3,最后一般变为250px。然后向上传递了然后怎么办呢,接下来再看一个图
这个就是讲了Gn的具体内部架构,先把上采样的和Zn噪声想加,然后传入5层的全卷机网络,然后再和Xn+1相加,最后输出的Xn传到上一层,也就是下面的公式所表达的
然后网络是3233的全卷积,然后上4个scale,就要变成二倍的,6433.然后用了batchnorm和leaklyrelu。由于生成器是全卷积的,所以可以在测试时生成任意大小和宽高比的图片(通过改变噪声图的尺寸)。然后patch刚开始是1/2左右,越想后就会越小。
2.2. Training
我们按顺序训练我们的多尺度体系结构,从最粗的尺度到最细的尺度。一旦每个GAN被训练,它就会被固定下来。我们对nth GAN的训练损失包括一个对抗部分和一个重建部分,
对抗损失每个生成器Gn都与一个Markovian鉴别器Dn相结合,该Dn将其输入的每个重叠的补丁分类为真或假[31,26]。我们使用WGAN-GP的损失[20],我们发现增加训练的稳定性,其中最终的识别分数是patch识别图的平均值。相对于纹理的单图像GANs(例如,[31,27,3]),这里我们定义了整个图像的损失,而不是随机的(批量大小为1)。这允许网络学习边界条件(参见SM),这是我们设置的一个重要特性。Dn的架构和ψn一样 ,所以它的patch大小(净的接受域)是11×11。



然后就是重建损失,所有的Zn只有第一个是随机生成的高斯噪声,其他的是红色标的
所以整个训练网络就介绍完了。
接下来的很多应用就是对这个网络的应用

这个是手写画转图片,效果如下

其实就是网络训练出来后,把输入图片找一个scale当做上采样一样插入,也就是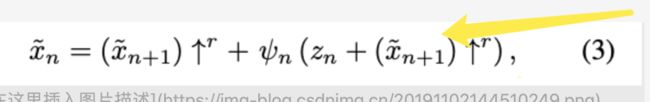
这个,当然,你越晚插入,变化就越明显明显,如下图,n就是插入的层数也就是scale是几,0是最后一层。
还有一个例子解释接下来这个,斑马是训练图片,然后输入了
一个马的照片,最后输出斑马一样的马。。。。。其实就是新输入的干扰了原本网络,强行把进行上采样的Xn+1改了,但是原来网络的权值都是给斑马图片量身定制,所以也就实现了结合。

还有就是
效果图:

但是和上面原理是一样的。
接下来介绍下提高分辨率:
超分辨率增加一个输入图像的分辨率的因素。我们训练我们的模型在低分辨率(LR)图像,重建减肥的α= 100和金字塔尺度因子r =√k
s以来一些k∈n小结构往往会发生跨尺度的自然场景[18],在测试时间我们upsample
LR图像和噪音一起注入过去的生成器,G0。我们重复k次以获得最终的高分辨率输出。示例结果如图10所示。可以看出,我们重建的视觉质量超过了目前最先进的内部方法[51,46],也超过了以最大信噪比[32]为目标的外部方法。
有趣的是,它可以与外部训练的SR-GAN方法[30]相媲美,尽管它只暴露在一张图像中。在[4]之后,我们在BSD100数据集[35]上比较了表3中5种方法在失真(RMSE)和感知质量(NIQE[40])方面的不同,这是两个从根本上相互冲突的需求[5]。可以看出,SinGAN在感性品质上非常优秀;其NIQE分数仅略低于SRGAN,其RMSE稍好一些。
然后最后介绍一个开始展示的那个图片。

Samples at arbitrary dimensions
使用SinGAN,我们可以生成任意大小和长宽比的样本。虽然这在表面上类似于重定向,但这两个任务是截然不同的。下面我们通过与seam carving[1]的比较来说明这一点。在我们的例子中,样本是随机的,没有优化以保持突出的对象或强边缘。这通常会导致在输入图像中不显示的合理配置。另一方面,在图像重定向中,结构通常局限于图像中出现的结构,并可能在极端的纵横比下发生不真实的变形。
就是因为是全卷积,所以可以随意改变大小(通过改变开始的噪声图的尺寸),因为是patch比较,所以比较的时候局部差不多一样就可以了,不要求全局。于是就生成了随机的合理图像。如下
\