Spark经典面试题
1.什么是spark?
spark是基于内存计算的通用大数据并行计算框架,是一个快速、通用可扩展的大数据分析引擎。它给出了大一统的软件开发栈,适用于不同场合的分布式场景,如批处理、迭代算法、交互式查询、流处理、机器学习和图计算。
2.spark生态有哪些?
SparkCore:spark的核心计算 主要Rdd
SparkSQL:提供了类sql方式操作结构化半结构化数据。对历史数据进行交互式查询。(即席查询:用户根据自己的需求,自定义查询)
SparkStreaming:提供了近乎实时的流式数据处理,与storm相比有更高的吞吐量。(实时计算 目前实时计算框架有哪些? storm、sparkstreaming、flink)
SparkMl:提供了常见的机器学习算法库,包括分类、回归、聚类、协同工过滤(个性推荐:用户画像)等,还提供模型评估、数据处理等额外功能,使得机器学习能够更加方便的在分布式大数据环境下,快速的对数据进行处理形成模型后提供在线服务。
Graphx:用来操作图的程序库,可以进行并行的图计算。支持各种常见的图算法,包括page rank、Triangle Counting等。
3.spark的提交流程?
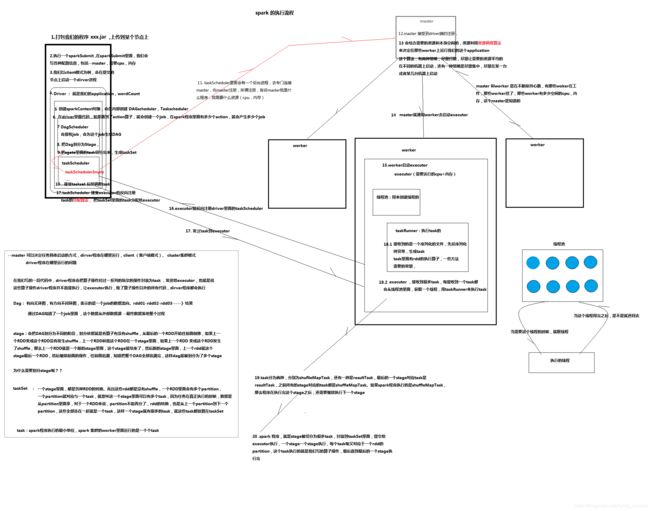
4.spark的提交方式?有什么区别?
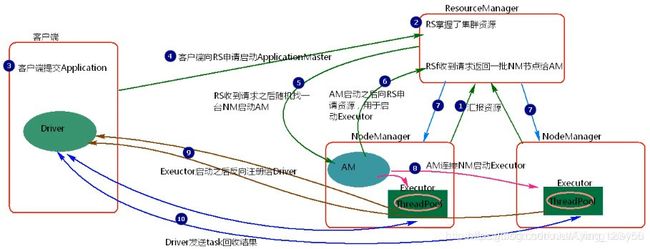
- client模式:
- cluster模式:
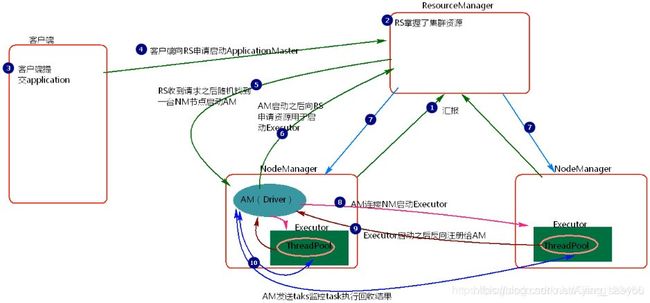
client模式与cluster模式的区别:
-
启动集群nodeManager向ResourceManager汇报资源。
-
RS掌握了集群资源。
-
客户端提交application。
-
客户端向ResourceManager申请启动ApplicationMaster。
-
ResourceManager收到请求之后随即找到一台NodeManager结点启动ApplicationMaster。
-
ApplicationMaster启动之后向ResourceManager申请资源用于启动Executor。
-
ResourceManager将申请到的Executor的节点NodeManager返回给ApplicationMaster。
-
ApplicationMaster连接NodeManager启动Executor。
-
Executor启动字后反向注册给ApplicationMaster
-
ApplicationMaster发送task到Executor执行并监控task执行回收结果。
注意:
client模式提交任务,会在客户端看到task的执行情况和结果,当在客户端提交多个application时,每个application都会启动自己的Driver,Driver与集群Worker有大量的通信,会造成客户端网卡流量激增问题。这种模式适用于程序测试。不适用于生产环境。模式提交任务,Driver会在急群众随机一台Worker上启动,如果提交多个application时,那么每个application的Driver会分散到集群的Worker节点,相当于将client模式的客户端网卡流量激增问题分散到集群中。这种模式适用于生产环境。
因为cluster模式,随机分散在Worker节点上创建Driver,由Driver来发送任务到Worker。所以打包的程序任务必须在分散的Worker节点对应的目录下都存在。
5.spark算子?(随口20个)
见本博客两章Transformation算子&Action算子、控制算子
点击查看->《Treansformation算子&Action算子》
点击查看->《控制算子》
6.什么是宽依赖 窄依赖?
Spark中RDD的高效与DAG(有向无环图)有很大的关系,在DAG调度中需要对计算的过程划分Stage,划分的依据就是RDD之间的依赖关系。RDD之间的依赖关系分为两种,宽依赖(wide dependency/shuffle dependency)和窄依赖(narrow dependency)。
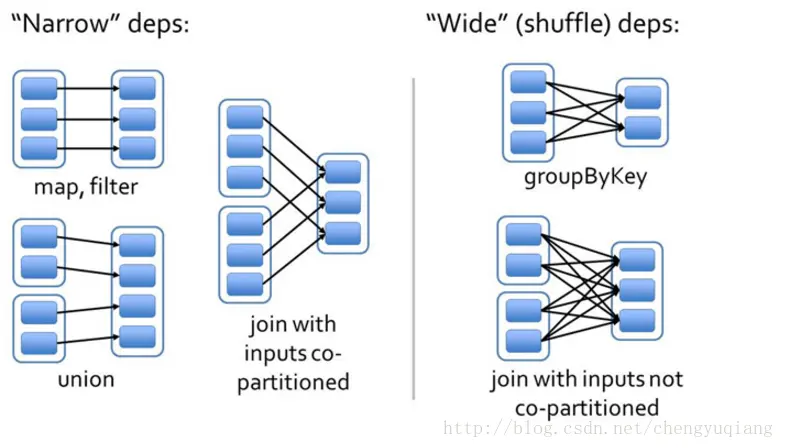
(左边为窄依赖,右边为宽依赖)
-
窄依赖:
窄依赖就是指父RDD的每个分区只被一个子RDD分区使用,子RDD分区通常只对应常数个父RDD分区,如下图所示【其中每个小方块代表一个RDD Partition】窄依赖有分为两种:
一种是一对一的依赖,即OneToOneDependency
还有一个是范围的依赖,即RangeDependency,它仅仅被org.apache.spark.rdd.UnionRDD使用。UnionRDD是把多个RDD合成一个RDD,这些RDD是被拼接而成,即每个parent RDD的Partition的相对顺序不会变,只不过每个parent RDD在UnionRDD中的Partition的起始位置不同 -
宽依赖:
宽依赖就是指父RDD的每个分区都有可能被多个子RDD分区使用,子RDD分区通常对应父RDD所有分区,如下图所示【其中每个小方块代表一个RDD Partition】
窄依赖的函数有:
map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
宽依赖的函数有:
groupByKey, join(父RDD不是hash-partitioned ), partitionBy
7.spark shuffle?
点击查看->《SparkShuffle 及性能调优》
和mr shuffle:从map端的输出到reduce 的输入,慢的主要原因是有数据落地,磁盘IO
spark三种,优化前(HashShuffle),优化1(优化后的HashShuffle),优化2(SortShuffle) 主要是中间临时小文件的优化
8.spark优化?(随口说出10条以上)
点击查看->《Spark优化要点(开发)》
9.shuffle类算子有哪些?
- 去重类算子
def distinct()
def distinct(numPartitions: Int)
- 聚合类算子
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
def groupBy[K](f: T => K, p: Partitioner):RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner):RDD[(K, Iterable[V])]
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner): RDD[(K, U)]
def aggregateByKey[U: ClassTag](zeroValue: U, numPartitions: Int): RDD[(K, U)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitions: Int): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean =true, serializer: Serializer =null): RDD[(K, C)]
- 排序类算子
def sortByKey(ascending: Boolean =true, numPartitions: Int = self.partitions.length): RDD[(K, V)]
def sortBy[K](f: (T) => K, ascending: Boolean =true, numPartitions: Int =this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
- 重分区类算子
def coalesce(numPartitions: Int, shuffle: Boolean =false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
def repartition(numPartitions: Int)(implicit ord: Ordering[T] =null)
- 集合或者表操作类算子
def intersection(other: RDD[T]): RDD[T]
def intersection(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] =null): RDD[T]
def intersection(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], p: Partitioner)(implicit ord: Ordering[T] =null): RDD[T]
def subtractByKey[W: ClassTag](other: RDD[(K, W)]): RDD[(K, V)]
def subtractByKey[W: ClassTag](other: RDD[(K, W)], numPartitions: Int): RDD[(K, V)]
def subtractByKey[W: ClassTag](other: RDD[(K, W)], p: Partitioner): RDD[(K, V)]
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
10.reducebykey和groupbykey 的区别?
先看下源码:
/**
* Merge the values for each key using an associative reduce function. This will also perform
* the merging locally on each mapper before sending results to a reducer, similarly to a
* "combiner" in MapReduce. Output will be hash-partitioned with the existing partitioner/
* parallelism level.
*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = {
reduceByKey(defaultPartitioner(self), func)
}
/**
* Group the values for each key in the RDD into a single sequence. Allows controlling the
* partitioning of the resulting key-value pair RDD by passing a Partitioner.
* The ordering of elements within each group is not guaranteed, and may even differ
* each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*
* Note: As currently implemented, groupByKey must be able to hold all the key-value pairs for any
* key in memory. If a key has too many values, it can result in an [[OutOfMemoryError]].
*/
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKey[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine=false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
通过源码可以看出
reduceByKey:reduceByKey会在结果发送至reducer之前会对每个mapper在本地进行merge,有点类似于在MapReduce中的combiner。这样做的好处在于,在map端进行一次reduce之后,数据量会大幅度减小,从而减小传输,保证reduce端能够更快的进行结果计算。
groupByKey:groupByKey会对每一个RDD中的value值进行聚合形成一个序列(Iterator),此操作发生在reduce端,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。同时如果数据量十分大,可能还会造成OutOfMemoryError。
通过以上对比可以发现在进行大量数据的reduce操作时候建议使用reduceByKey。不仅可以提高速度,还是可以防止使用groupByKey造成的内存溢出问题。
11.spark的序列化
主要从以下三个方面解释Spark 应用中序列化问题 。
1、Java序列化含义?
2、Spark代码为什么需要序列化?
3、如何解决Spark序列化问题?
1、Java序列化含义?
Spark是基于JVM运行的进行,其序列化必然遵守Java的序列化规则。
序列化就是指将一个对象转化为二进制的byte流(注意,不是bit流),然后以文件的方式进行保存或通过网络传输,等待被反序列化读取出来。序列化常被用于数据存取和通信过程中。
对于java应用实现序列化一般方法:
class实现序列化操作是让class 实现Serializable接口,但实现该接口不保证该class一定可以序列化,因为序列化必须保证该class引用的所有属性可以序列化。
这里需要明白,static和transient修饰的变量不会被序列化,这也是解决序列化问题的方法之一,让不能序列化的引用用static和transient来修饰。(static修饰的是类的状态,而不是对象状态,所以不存在序列化问题。transient修饰的变量,是不会被序列化到文件中,在被反序列化后,transient变量的值被设为初始值,如int是0,对象是null)
此外还可以实现readObject()方法和writeObject()方法来自定义实现序列化。
2、Spark的transformation操作为什么需要序列化?
Spark是分布式执行引擎,其核心抽象是弹性分布式数据集RDD,其代表了分布在不同节点的数据。Spark的计算是在executor上分布式执行的,故用户开发的关于RDD的map,flatMap,reduceByKey等transformation 操作(闭包)有如下执行过程:
1. 代码中对象在driver本地序列化
2. 对象序列化后传输到远程executor节点
3. 远程executor节点反序列化对象
4. 最终远程节点执行
故对象在执行中需要序列化通过网络传输,则必须经过序列化过程。
3、如何解决Spark序列化问题?
如果出现NotSerializableException报错,可以在spark-default.xml文件中加入如下参数来开启SerializationDebugger功能类,从而可以在日志中打印出序列化出问题的类和属性信息。
spark.executor.extraJavaOptions -Dsun.io.serialization.extendedDebugInfo=true
spark.driver.extraJavaOption -Dsun.io.serialization.extendedDebugInfo=true
对于scala语言开发,解决序列化问题主要如下几点:
1、在Object中声明对象 (每个class对应有一个Object)
2、如果在闭包中使用SparkContext或者SqlContext,建议使用SparkContext.get() and SQLContext.getActiveOrCreate()
3、使用static或transient修饰不可序列化的属性从而避免序列化。
注:scala语言中,class的Object
对于java语言开发,对于不可序列化对象,如果本身不需要存储或传输,则可使用static或trarnsient修饰;如果需要存储传输,则实现writeObject()/readObject()使用自定义序列化方法。
此外注意
对于Spark Streaming作业,注意哪些操作在driver,哪些操作在executor。因为在driver端(foreachRDD)实例化的对象,很可能不能在foreach中运行,因为对象不能从driver序列化传递到executor端(有些对象有TCP链接,一定不可以序列化)。
所以这里一般在foreachPartitions或foreach算子中来实例化对象,这样对象在executor端实例化,没有从driver传输到executor的过程。
dstream.foreachRDD { rdd =>
val where1 = "on the driver"
rdd.foreach { record =>
val where2 = "on different executors"
}
}
}
12.spark submit 有哪些参数
在spark命令行输入
./bin/spark-submit --help
可以看到spark-submit的所用参数如下:
Usage: spark-submit [options] <app jar | python file | R file> [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Usage: spark-submit run-example [options] example-class [example args]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local[*]).
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor. File paths of these files
in executors can be accessed via SparkFiles.get(fileName).
--conf PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Cluster deploy mode only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
--principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to
the node running the Application Master via the Secure
Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.
相关意义如下:
| 参数名 | 参数说明 |
|---|---|
| –master | master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local |
| –deploy-mode | 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client |
| –class | 应用程序的主类,仅针对 java 或 scala 应用 |
| –name | 应用程序的名称 |
| –jars | 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下 |
| –packages | 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标 |
| –exclude-packages | 为了避免冲突 而指定不包含的 package |
| –repositories | 远程 repository |
| –conf PROP=VALUE | 指定 spark 配置属性的值,例如 -conf spark.executor.extraJavaOptions="-XX:MaxPermSize=256m" |
| –properties-file | 加载的配置文件,默认为 conf/spark-defaults.conf |
| –driver-memory | Driver内存,默认 1G |
| –driver-java-options | 传给 driver 的额外的 Java 选项 |
| –driver-library-path | 传给 driver 的额外的库路径 |
| –driver-class-path | 传给 driver 的额外的类路径 |
| –driver-cores | Driver 的核数,默认是1。在 yarn 或者 standalone 下使用 |
| –executor-memory | 每个 executor 的内存,默认是1G |
| –total-executor-cores | 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用 |
| –num-executors | 启动的 executor 数量。默认为2。在 yarn 下使用 |
| –executor-core | 每个 executor 的核数。在yarn或者standalone下使用 |
示例:
Run on a Spark standalone cluster in client deploy mode(standalone client模式)
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
Run on a YARN cluster(YARN cluster模式)
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \ # can be client for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000