深入理解Python里的字典和集合
想要理解Python里字典和集合类型的长处和弱点,他们背后的散列表是绕不开的一环
理解以下几个问题
- Python里的dict和set的效率有多高?
- 为什么他们是无序的?
- 为什么并不是所有的python对象都可以当做dict和键或者set的元素?
- 为什么dict的键和set的元素是根据他们被添加元素的次序而定的,以及为什么在映射的生命周期中,这个顺序并不是一成不变的?
- 为什么不应该在迭代循环dict或者set的同时添加元素?
一丶字典中的散列表
散列表其实是一个稀疏数组(总是空白元素的数组成为稀疏数组)。在一般的数据结构教材中,散列表的单元通常叫做表元(bucket)。在dict的散列表当中,每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,一个是对值得引用,因为所有表元的大小一致,所以可以通过偏移量来读取表元。
因为Python会设法保证三分之一的表元是空的,所以在快要达到阈值的时候,原有的散列表会被复制到一个更大的空间。如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值,python用hash方法做这件事情。
1.散列值和相等性
内置的hash()方法可以用于所有的内置对象。如果自定义对象调用hash()方法,实际上运行的是自定义的__hash__方法,如果两个对象在比较的时候是相等的,那么散列值必然相等,否则散列表就不能正常运行了。
In [1]: a = 1
In [2]: b = 1.000
In [3]: a == b
Out[3]: True
In [4]: hash(a) == hash(b)
Out[4]: True
为了让散列值能够胜任散列表这一角色,他们必须在散列空间尽量分散开。这意味最理想的情况下,越是相近的值但是不相等的值,他们的散列值差别就越大。
In [5]: c = 1.00000000001
In [6]: d = 1.00000000002
In [7]: hash(c)
Out[7]: 23058433
In [8]: hash(d)
Out[8]: 46116865
从python3.3开始,str、bytes和datetime对象的散列值计算过程多了一步加"salt"的步骤。所谓的加盐值就是python进程的一个常量,但是每次启动python解释器都会生成一个随机的salt,随机salt的加入是为了防止DOS攻击而采取的一种安全措施。
2.散列表算法
为了获取dict[search_key]后面的值,python首先会调用hash()函数来计算key的散列值,把这个值的最低位当做偏移量,在散列表里面查找表元(具体取几位,取决于当前散列表的大小)。若找到的表元是空的,则抛出KeyError。若不是空的,则表元里会有一对found_key:found_value。这时候会检验key == found_key是否为真,如果为真,则返回found_Value。
如果search_key和found_key不匹配的话,这种情况成为散列冲突。发生这种情况是因为散列值表所做的其实就是把随机的元素映射到只有几位的数字上,而散列表本身的索引又只依赖于这个数字的一部分。为了解决散列冲突,算法会在散列值上另外再取几位数,然后用特殊的方法处理一下,把新得到的数字再当做索引来选好表元,若这次找到的表元是空的,则同样抛出KeyError,若非空,或者键匹配,则返回这个值,但如果又发现了散列冲突,则重复以上步骤。
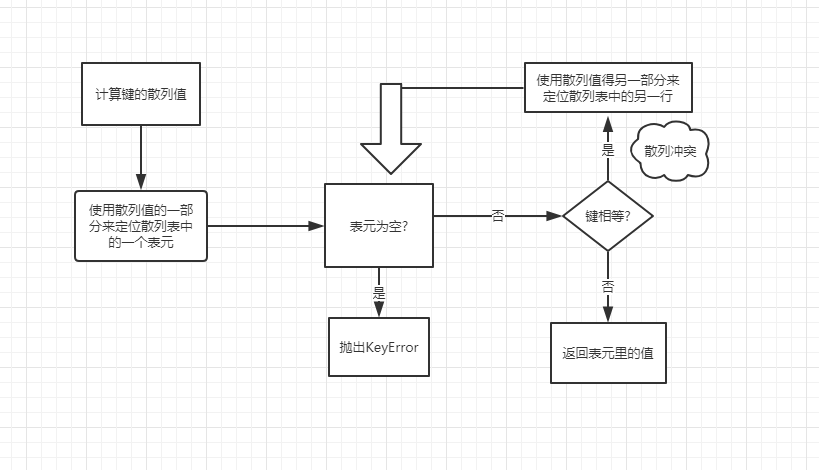
添加新元素和更新现有键值的操作和上面的几乎一样。只不过对于前者在发现空表元的时候会放入一个新元素;对于后者,在找到对应的表元后,原表里的值会被替换成新的值。另外再插入新值时,python会按照散列表的拥挤程度来决定是否重新分配内存为他扩容。如果增加了散列表的大小,那散列表所占的位数和用做索引的位数都会随之增加,这样的目的是为了减少发生散列冲突的概率。
二丶dict的实现及其导致的结果
1.键必须是可散列的
一个可散列的对象必须满足一下条件:
- 支持hash()函数,并且通过__hash__()方法得到的散列值是不变的
- 支持通过__eq__()方法来检测相等性
- 若a == b为真,则hash(a) == hash(b)也为真
2.字典在内存上的开销巨大
由于字典使用了散列表,而散列表又必须是稀疏的,这导致在空间上的效率低下。举例而言,如果你要存放数量巨大的记录,那么放在由元组或者具名元组的列表中回事比较好的选择;最好不要用json的风格,用字典组成的列表来存放。用元组代理字典存放的原因有两个:第一避免了有散列表所耗费的空间,第二是无需把记录中字段的名字在每个元素里都存一遍。
3.键查询很快
dict的实现是典型的空间换时间,字典内存有着巨大的内存开销,但他们提供了无视数据量大小的快速访问———只要把字典能装在内存里。
4.键的次序取决于添加次序
当往dict里添加新键的时,新键可能被安排存放在另一个位置。于是下面这种情况会发生:由dict([key1,value1],[key2,value2])和dict([key2,value2],[key1,value1])得到的两个字典在进行比较的时候,他们是相等的。但是如果在key1和key2被添加到字典的过程中有冲突发生的话,这两个件出现在字典中的顺序是不一样的。
5.往字典里添加新键可能会改变已有键的顺序
无论何时往字典里添加新的键,python解释器都可能做出为字典扩容的决定。扩容导致的结果就是新键一个更大的散列表,并把字典里的元素添加到新列表。这个过程可能会发生新的散列冲突,导致新的散列表中键的次序变化。
由此可知,不要对字典同时进行迭代和修改。如果想扫描并修改一个字典,最好分成两步来进行:首先对字典进行迭代,以得出需要添加的内容,把这些内容放在一个新字典里,迭代结束之后再对原字典进行更新。
三丶set的实现及导致的结果
set和frozenset的实现也依赖散列表,但他们在散列表中存放的只有元素的引用。在set加入python之前,都是把字典加上无意义的值当做集合来用的。
集合的特点总结:
- 集合里的元素必须是可散列的
- 集合和字典一样很消耗内存
- in的时间复杂度为O(1),很高效
- 元素的次序取决于被添加到集合里的次序
- 往集合添加元素,可能会改变集合里已有元素的次序
四丶总结
字典算得上是python的基石。除了基本的dict之外,标准库Collections还提供了很多特别有用的映射类型,比如defaultdict、OrderedDict、ChainMap和Counter,还提供了了便于扩展的UserDict类。
大多数映射类型还提供了很强大的两个方法,setdefault和update。setdefault方法可以用来更新字典里存放的可变值,比如列表,从而避免了重复的键搜索。update则让批量更新字典成为可能,他可以用来插入新值或更新已有的键值对,他的参数是包括(key,value)这种键值对的可迭代对象,或者关键字参数。映射类型的构造方法也会利用update方法来让用户可以使用别的映射对象、可迭代对象或者关键字参数来创建新对象。
dict和set背后的散列效率很高,对他的了解越深入,就越能理解为什么被保存的元素会呈现不同的顺序,以及已有的元素顺序会发生变化的原因。
同时,速度是以牺牲空间换来的。