Scrapy进阶开发
selenium介绍
1.chromedriver不加载图片
使用chromedrive时,我们可以设置不加载图片:
chrome_opt = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images":2}
chrom_opt.add_experimental_option("prefs",prefs)
browser = webdriver.Chrome(executable_path="...",chrome_options=chrom_opt)
2.phantomjs
phantomjs无界面浏览器,但是多进程情况下,性能会下降很多。
3. selenium集成到Scrapy中
首先能想到将selenium集成到Scrapy中的方式,就是利用中间件,因为中间件中有process_request,可以对request做处理。
设置一个JSPageMiddleware:
from selenium import webdriver
from scrapy.http import HtmlResponse
class JSPageMiddleware(object):
#通过chrome请求动态网页
def process_request(self,request,spider):
if spider.name == "jobbole": #以伯乐在线为例
browser = webdriver.Chrome(executable_path="......")
browser.get(request.url)
import time
time.sleep(3)
print("访问:{0}".format(request.url))
#已经通过browser请求完成,没必要再发送到下载器了去下载了,就直接return HtmlResponse
return HtmlResponse(url=browser.current_url,body=browser.page_source,encoding="utf-8",request=request)
然后在settings配置就可以生效了:
DOWNLOADER_MIDDLEWARES = {
'ArticleSpider.middlewares.JSPageMiddleware': 1,
}
但是,这种方式并不是最优的,因为每请求一次,就会开启一个新的browser。而且browser也没有关闭。
因此,我们可以将browser放入spider中:
from selenium import webdriver
from scrapy.xlib.pydispatch import dispatcher
from scrapy import signals
class JobboleSpider(scrapy.Spider):
#省略部分代码。。。。
def __init__(self):
self.browser = webdriver.Chrome(executable_path="......")
super(JobboleSpider,self).__init__()
dispatcher.connect(self.spider_closed,signals.spider_closed) #这里用到了信号量,spider关闭的时候,将browser也关闭
def spider_closed(self,spider):
print("spider closed")
self.browser.quit()
#省略部分代码。。。。
再改写JSPageMiddleware:
from scrapy.http import HtmlResponse
class JSPageMiddleware(object):
#通过chrome请求动态网页
def process_request(self,request,spider):
if spider.name == "jobbole": #以伯乐在线为例
spider.browser.get(request.url)
import time
time.sleep(3)
print("访问:{0}".format(request.url))
#已经通过browser请求完成,没必要再发送到下载器了去下载了,就直接return HtmlResponse
return HtmlResponse(url=spider.browser.current_url,body=spider.browser.page_source,encoding="utf-8",request=request)
这样就将selenium集成到Scrapy中了,但是我们知道Scrapy是一个异步的框架,用了selenium后,就变成了同步的请求了,性能自然会有所下降。
不过我们可以通过重写downloader来提高性能。github上也有相关开源项目,可以参考。
Scrapy其他功能
1.scrapy的暂停与重启
在命令行中输入:
scrapy crawl spider_name -s JOBDIR=.../...
#以爬取拉勾网为例
scrapy crawl lagou -s JOBDIR=job_info/001
运行命令后,只需要按下“Ctrl+c”,就可以暂停爬虫。
暂停后,我们可以发现新增了文件夹job_info:
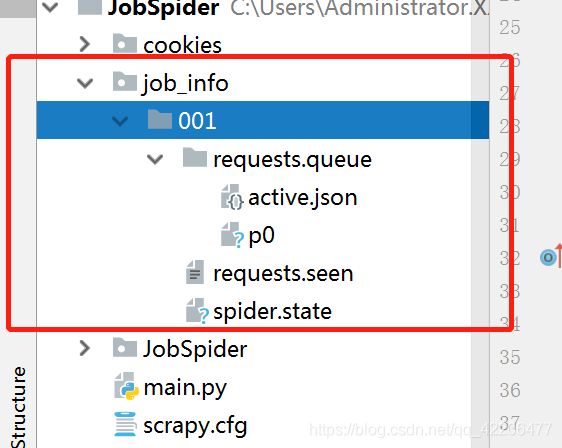
如果需要继续爬虫,则只需输入相同的命令,运行命令后可以发现,是接着上一次爬虫进度的。
如果需要重启爬虫,则只需要输入新的文件名,(接上面的例子)如:
scrapy crawl lagou -s JOBDIR=job_info/002
2.scrapy的url去重原理
分析源码,我们可以发现在Scheduler中,通过判断dont_filter的值与request_seen来去重,而request_seen中则是采用了request_fingerprint指纹的方式。
进一步深入request_fingerprint,发现是用hashlib来实现的。

class Scheduler(object):
#此处省略大部分代码。。。。
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
dqok = self._dqpush(request)
if dqok:
self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)
else:
self._mqpush(request)
self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)
self.stats.inc_value('scheduler/enqueued', spider=self.spider)
return True
#此处省略大部分代码。。。。
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
#此处省略大部分代码。。。。
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
#此处省略大部分代码。。。。
3.spider middleware 详解
spider middleware位于spider与engine之间,使用时也需要在settings中设置SPIDER_MIDDLEWARES,如:
SPIDER_MIDDLEWARES = {
'JobSpider.middlewares.JobspiderSpiderMiddleware': 543,
}
spider middleware中有几个重要的处理函数:
- 这个方法在将response发往spider的过程中被调用
这个方法应该返回None或者raise一个异常
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
- 这个方法将在requset或者item发往engine的过程中被调用
这个方法必须返回一个reponse,dict,item
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
- 这个方法将在一个spider或者一个process_spider_input方法抛出异常的时候被调用
这个方法应该返回None或者一个reponse,dict,item
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
- 这个方法用来处理首次发往engine的请求,和process_spider_output唯一不同的地方是,不接受response,并且只能返回一个request
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
内置的SpiderMiddleware:
scrapy中的内置spidermiddleware都可以在这个文件夹下查看:
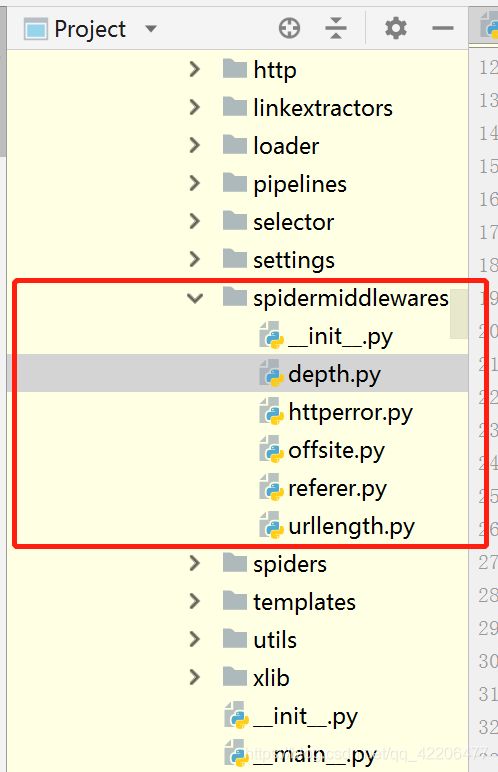
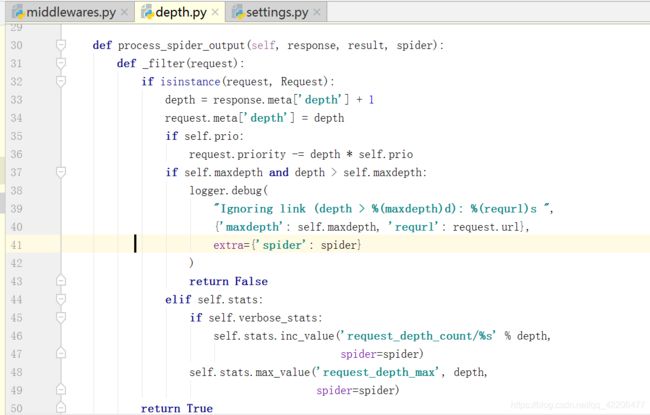
DepthMiddleware是一个用于追踪每个 Request 在被爬取的网站的深度的中间件。 其可以用来限制爬取深度的最大值。
从源码中可以看出,主要是在process_spider_output中处理逻辑
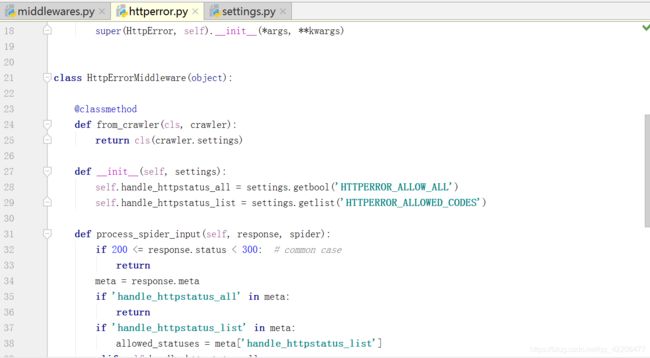
HttpErrorMiddleware过滤出所有失败(错误)的 HTTP response,使得spider 不需要处理这些 request。
从源码中可以看出,主要是在process_spider_input中处理逻辑
3.scrapy的数据收集
scrapy提供了方便的收集数据的机制,数据以key/value方式存储,值大多数是计数值。
数据收集器对每个spider保持一个状态表。当spider启动时,该表自动打开,当spider关闭时,该表自动关闭。
下面就具体举一个例子来说明如何使用数据收集器:
比如我们需要收集伯乐在线所有404的url以及404页面数,就需要在spider中添加代码:
class JobboleSpider(scrapy.Spider):
#省略部分代码。。。。
handle_httpstatus_list = [404]
#省略部分代码。。。。
def __init__(self):
self.fail_urls = []
def parse(self,response):
if response.status == 404:
self.fail_urls.append(response.url)
self.crawler.stats.inc_value("failed_url")
Debug一下,就发现在stats中有一个用来记录404页面数的failed_url:
4.scrapy的信号详解
scrapy使用信号来通知事情发生,我们可以在scrapy项目中捕捉一些信号来完成额外的工作或功能。
有关信号API可以参考官方文档 https://doc.scrapy.org/en/latest/topics/signals.html
下面就具体举一个例子来说明如何使用信号
还是接着上一个爬取伯乐在线的例子,改写spider中的代码:
class JobboleSpider(scrapy.Spider):
#省略部分代码。。。。
handle_httpstatus_list = [404]
#省略部分代码。。。。
def __init__(self):
self.fail_urls = []
dispatcher.connect(self.handle_spider_closed,signals.spider_closed)#当spider关闭时,执行handle_spider_closed
def handle_spider_closed(self,spider,reason):
self.crawler.stats.set_value("failed_urls",",".join(self.fail_urls))#将fail_urls中的元素用“,”连接放入failed_urls中
def parse(self,response):
if response.status == 404:
self.fail_urls.append(response.url)
self.crawler.stats.inc_value("failed_url")
5.scrapy扩展开发
每个扩展是一个单一的python class,Scrapy扩展的主要入口是from_crawler类方法,它接收一个Crawler的类实例,通过这个对象访问settings,signals,stats控制爬虫行为。扩展开发的思路:通过信号链绑定处理函数,在处理函数中加需要的逻辑。
实际上,中间件都是扩展。