paddlepaddle梦幻联动青春有你2看着小姐姐学AI---百度Python-AI7日打卡活动
本次活动由百度aistudio等相关团队提供技术支持,从当前火热的青春有你2入手,七天打卡学习活动,每日不同的课时教学和学习任务,循序渐进带大家利用Python进行数据抓取、数据分析、CV及NLP相关的AI实践,让大家短时间内学习到AI的整个流程。也顺便能够利用技术手段分析一下到底哪家爱豆最火!
Day1 Python基础及人工智能概述和入门基础
首先由中科院老师给大家从人工智能起源到发展以及当前各行业的应用进行了概述讲解,让初入此坑的同学对AI有了简单的认识,并且介绍了入门AI所需要的知识体系。然后讲解了当前最火热的也是人工智能必备编程语言的入门基础,演示了基本语法和流程,并且对python的6中基本数据类型:Number、String、Tuple、List、Dict、Set进行讲解,并且在最后留了操作作业:
Day homework01 99乘法表的输出及查找特定名称文件

def table():
#在这里写下您的乘法口诀表代码吧!
# 每一行可以看到j*i的格式 j从左向右递增, i则是当前行号码,所以利用双循环,每一行循环结束换行即可
# 为了保证格式对齐,结尾用‘\t’ 分割。
for i in range(1,10):
for j in range(1,i+1):
# print(j , "*" , i,"=" ,i*j,end="\t")
print('{}*{}={}'.format(j,i,i*j),end='\t')
print()
if __name__ == '__main__':
table()
#导入OS模块
import os
#待搜索的目录路径
path = "Day1-homework"
#待搜索的名称
filename = "2020"
#定义保存结果的数组
result = []
def findfiles(path, filename):
#在这里写下您的查找文件代码吧!
for inner_path in os.listdir(path):
fulldir = os.path.join(path, inner_path)
if os.path.isfile(fulldir):
if filename in os.path.split(fulldir)[-1]:
result.append(fulldir)
if os.path.isdir(fulldir):
findfiles(fulldir, filename)
if __name__ == '__main__':
findfiles(path, filename)
for idx,targetfile in enumerate(result):
print([idx+1,targetfile])
Day02 Python进阶
-
Python数据结构、面向对象、JSON、异常处理
-
在掌握简单的python语法之后,进行高阶操作,python有着高级语言的几乎一切优点。人美声甜的文姐姐带领大家学习了针对不同数据结构的常用操作。
-
常见Linux命令
-
AI任务大多会在linux系统上运行,包括本次课程的支持平台aistudio也是基于linux的,可以使用终端进行几乎一切常用的linux操作,非常方便。同时notebook与jupyter notebook几乎一样所以。掌握Linux常用操作非常有意义。
-

homework02 青你2选手数据爬取


数据分析和AI都需要有大量的数据支撑,并且AI还需要足够的标注数据来保证训练。所以为了了解青春有你2的小姐姐的信息,利用python提供的requests和BeautifulSoup库进行数据收集是非常有用的。
# **利用requests获得网页数据**
import json
import re
import requests
import datetime
from bs4 import BeautifulSoup
import os
#获取当天的日期,并进行格式化,用于后面文件命名,格式:20200420
today = datetime.date.today().strftime('%Y%m%d')
def crawl_wiki_data():
"""
爬取百度百科中《青春有你2》中参赛选手信息,返回html
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
url='https://baike.baidu.com/item/青春有你第二季'
try:
response = requests.get(url,headers=headers)
print(response.status_code)
#将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象, 可以传入一段字符串
soup = BeautifulSoup(response.text,'lxml')
#返回的是class为table-view log-set-param的所有标签
tables = soup.find_all('table',{'class':'table-view log-set-param'})
crawl_table_title = "参赛学员"
for table in tables:
#对当前节点前面的标签和字符串进行查找
table_titles = table.find_previous('div').find_all('h3')
for title in table_titles:
if(crawl_table_title in title):
return table
except Exception as e:
print(e)
## 对爬取的页面数据进行解析,并保存为JSON文件
def parse_wiki_data(table_html):
'''
从百度百科返回的html中解析得到选手信息,以当前日期作为文件名,存JSON文件,保存到work目录下
'''
bs = BeautifulSoup(str(table_html),'lxml')
all_trs = bs.find_all('tr')
error_list = ['\'','\"']
stars = []
for tr in all_trs[1:]:
all_tds = tr.find_all('td')
star = {}
#姓名
star["name"]=all_tds[0].text
#个人百度百科链接
star["link"]= 'https://baike.baidu.com' + all_tds[0].find('a').get('href')
#籍贯
star["zone"]=all_tds[1].text
#星座
star["constellation"]=all_tds[2].text
#身高
star["height"]=all_tds[3].text
#体重
star["weight"]= all_tds[4].text
#花语,去除掉花语中的单引号或双引号
flower_word = all_tds[5].text
for c in flower_word:
if c in error_list:
flower_word=flower_word.replace(c,'')
star["flower_word"]=flower_word
#公司
if not all_tds[6].find('a') is None:
star["company"]= all_tds[6].find('a').text
else:
star["company"]= all_tds[6].text
stars.append(star)
json_data = json.loads(str(stars).replace("\'","\""))
with open('work/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
Json数据如下格式
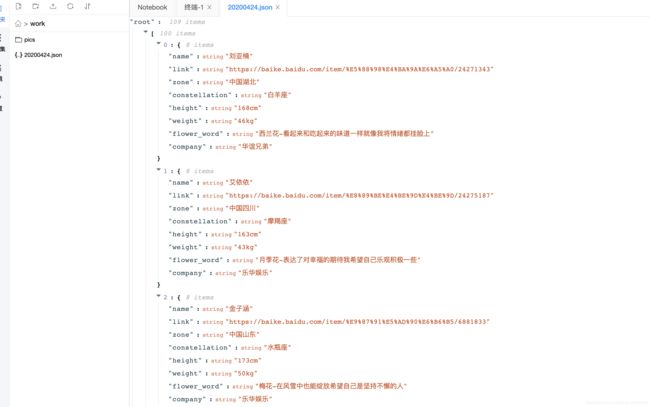
def crawl_pic_urls():
'''
爬取每个选手的百度百科图片,并保存
'''
with open('work/'+ today + '.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
count = 0
statistic_data = []
for star in json_array:
name = star['name']
link = star['link']
#!!!请在以下完成对每个选手图片的爬取,将所有图片url存储在一个列表pic_urls中!!!
# 分析最后结果的连接,每个选手的图片数量不太一致,查看选手网页 图是class="summary-pic" 中的图片列表的图,所以不同选手数量不同
# 首先根据 link 拿到网页数据
response = requests.get(link,headers=headers)
# 解析网页 在网页中找到 class="summary-pic"
soup = BeautifulSoup(response.text,'lxml')
#返回的是class为 summary-pic 所有标签
summary_pic_link = soup.find_all('div',{'class':'summary-pic'})
# print(summary_pic_link)
# break
for pic_link in summary_pic_link:
# print(pic_link)
# break
aHref = pic_link.a['href']
final_url = 'https://baike.baidu.com' + aHref
# 再解析链接
response = requests.get(final_url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
pic_list_url = soup.select('.pic-list img')
# print(pic_list_url)
# break
for star_pic in pic_list_url:
star_pic_url = star_pic['src']
# print(star_pic_url)
# break
statistic_data.append(star_pic_url)
# print(statistic_data)
# break
# count += 1
# print(count)
# break
#!!!根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中!!!
down_pic(name,statistic_data)
statistic_data.clear()
def down_pic(name,pic_urls):
'''
根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中,
'''
path = 'work/'+'pics/'+name+'/'
if not os.path.exists(path):
os.makedirs(path)
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(path+string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
# 打印爬取到的图片路径
def show_pic_path(path):
'''
遍历所爬取的每张图片,并打印所有图片的绝对路径
'''
pic_num = 0
for (dirpath,dirnames,filenames) in os.walk(path):
for filename in filenames:
pic_num += 1
print("第%d张照片:%s" % (pic_num,os.path.join(dirpath,filename)))
print("共爬取《青春有你2》选手的%d照片" % pic_num)
if __name__ == '__main__':
#爬取百度百科中《青春有你2》中参赛选手信息,返回html
html = crawl_wiki_data()
#解析html,得到选手信息,保存为json文件
parse_wiki_data(html)
#从每个选手的百度百科页面上爬取图片,并保存
crawl_pic_urls()
#打印所爬取的选手图片路径
show_pic_path('/home/aistudio/work/pics/')
print("所有信息爬取完成!")
最后运行结果如下:
