用户画像概念、项目概述及环境搭建(一)
项目安排:
企业级360°全方位用户画像
一、用户画像概念、设计构建用户画像及项目演示说明 -2天
用户画像概念发展
如何构建用户画像
标签Tag
项目核心功能:
深入剖析(最关键)
项目工程初步搭建
二、基础知识:数据导入ETL和应用调度 -2天
a)、数据采集与ETL
如何将业务数据采集导入到大数据平台上(HDFS、Hive、HBase)
b)、标签 -> 模型 -> SparkApplication
Oozie
===============================================================================
三、标签开发(基础标签) - 12天
a)、规则匹配标签 + GitHup 5天
b)、统计标签 2天
---------------------------------------------------------------------------
c)、挖掘标签 5天
涉及机器学习算法:聚类KMeans、决策树DecisionTree
===============================================================================
四、商品推荐体验及多数据源 - 3天
a)、当用户点击浏览商品时,给用户推荐商品(Top10)
涉及机器学习算法:ALS(交替最小二乘法)
b)、标签系统支持多种数据源
可以从任意数据源加载业务数据,构建标签,比如从HBase、Hive、MySQL和HDFS等等
第一部分
什么是用户画像???
对用户的描述 使用标签来进行标注(标识注明)!
学生的属性:
学生,帅,漂亮,性别,年龄,身高,成绩,体重,婚姻状况,月收入,兴趣爱好,籍贯,学号,政治面貌,发型,国籍。
学生的标签:
标签=> 标签值【特征=>特征值】
学校角色=>学生,
外貌=>帅/漂亮
性别=>男/女,
年龄=>20/21,
身高=>176/180,
成绩=>及格/优秀,
。。。 。。。
体重,婚姻状况,月收入,兴趣爱好,籍贯,学号,政治面貌,发型,国籍。
什么是标签??
对某一类特定群体或对象的某项特征进行的抽象分类和概括!!
标签的来源
1、基于用户基本信息

2、基于用户的业务数据信息
商业标签
消费能力、消费性别
行为标签
兴趣爱好、活跃度。
用户价值
高价值?低价值?
用户画像的方向
1、用户属性
a)使用注册时填写的基本信息
2、用户偏好
a)业务数据(订单数据,浏览数据、购物车数据)
b)喜欢买什么,看什么,玩什么。
3、用户行为
a)浏览数据
用户属性的研究侧重于显式地搜集用户特征信息
用户偏好研究侧重于制定兴趣度度量方法
用户行为的研究侧重于用户行为趋势的预测
消费能力,消费倾向。
退换货的数量
退换货数量: 10 5 0
品质要求: 高 中 极低
发货: 正品 高仿 低仿制品
赚钱: 200 1500 1900
用户画像分类
1)、匹配类
根据用户基本信息进行匹配,完善标签体系。例如:性别,籍贯,学历
2)、统计类
根据用户基本信息或行为数据进行统计完善标签系统。例如:年龄段,客单价,单价最高,退货率
3)、挖掘类
根据用户行为数据挖掘完善标签系统。例如:商品偏好,消费能力,品牌偏好
涉及机器学习算法:聚类KMeans、决策树DecisionTree
项目的价值
用户画像的应用场景
精准营销(广告投放)
只给会员发信息(精准营销)

数据化运营(产品布局)
帮助企业了解用户(所有用户的统称)分布(性别。学历,年龄)

推荐系统
根据历史记录,为用户(某一个具体的用户)推荐他可能感兴趣的商品【物以类聚-人以群分】
提取物品的特征,并分类。
用户(人)提取特征,划分人群。
推荐就是找到物和人的关系。
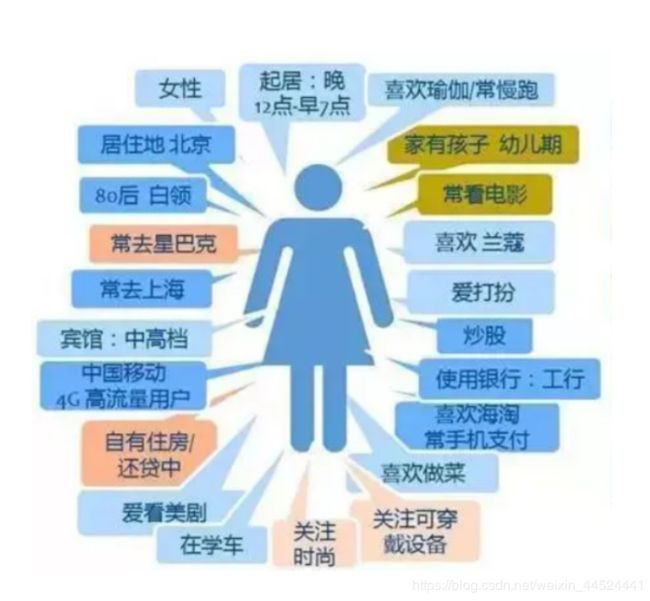
最终用户画像目标结果
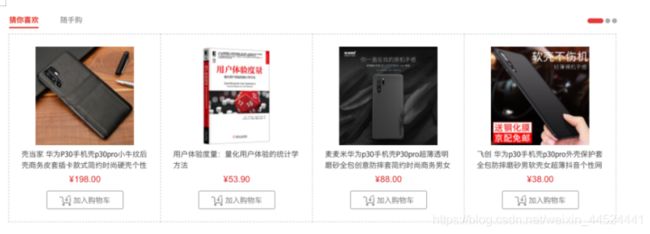
最终目标
一个标签算一次,每计算一次就追加到标签字段内。不断完善用户的标签,完善用户画像。
标签越多描述的越详细。

项目标签提交的流程
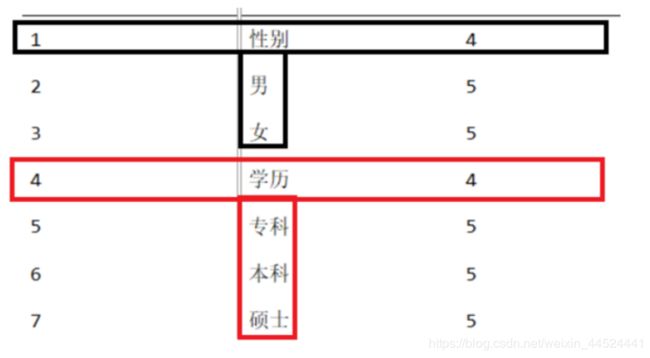
1、创建1,2,3级标签
一级:某一行业,
二级:行业内的某个公司,
三级:标签类别
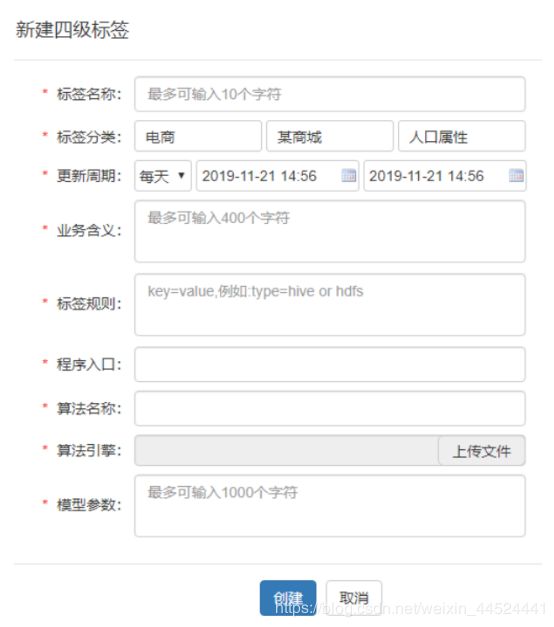
2、创建4级标签
具体的某一个标签
3、提交任务jar文件
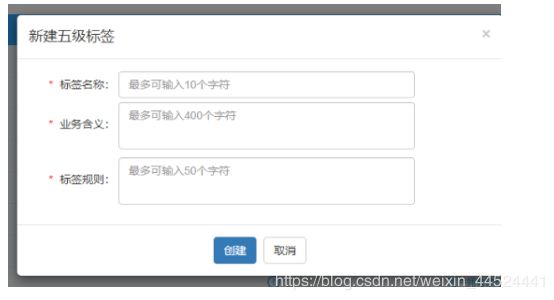
4、创建5级标签
具体的标签值:男/女 ,汉族/回族/维吾尔族
5、运行

工程说明
企业版本启动
界面
精简版
启动项目
访问地址:http://localhost:8081/#/tags

虚拟机说明:
用户名:root
密码:123456
主机名:bd001
Ip:192.168.10.20
Mysql链接: 用户:root 密码:123456
虚拟机配置10网段(根据实际情况启动虚拟网卡)

集群安装路径:/export/servers
apache-flume-1.6.0-cdh5.14.0-bin
flume
hadoop
hadoop-2.6.0-cdh5.14.0
hbase
hbase-1.2.0-cdh5.14.0
hive
hive-1.1.0-cdh5.14.0
jdk1.8.0_221
oozie
oozie-4.1.0-cdh5.14.0
scala-2.11.12
solr
solr-4.10.3-cdh5.14.0
spark
spark-2.2.0-bin-2.6.0-cdh5.14.0
sqoop
sqoop-1.4.6-cdh5.14.0
zookeeper
zookeeper-3.4.5-cdh5.14.0
软件启动:bash /root/bd.sh start/stop (启动/关闭)
2144 ResourceManager
1985 SecondaryNameNode
2933 HRegionServer
2806 HMaster
1591 QuorumPeerMain
3015 Bootstrap
3240 Jps
3049 Bootstrap
1802 DataNode
2299 JobHistoryServer
1708 NameNode
2239 NodeManager
项目标签管理界面(精简版)介绍
项目工程: serprofile29
访问地址:http://localhost:8081/#/tags

标签数据:标签数据存在mysql(bd001)中的tags_new数据库,tbl_basic_tag表中。
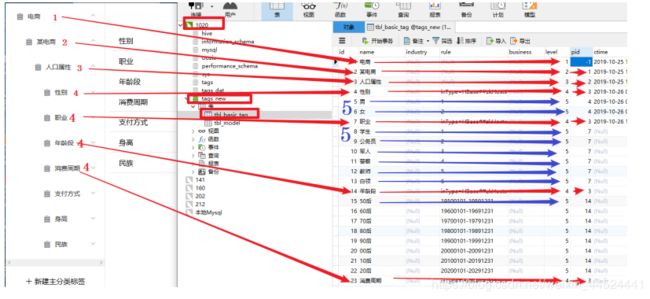
添加四级标签:

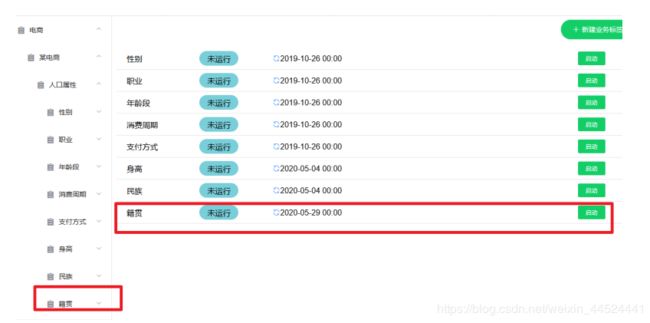
添加后的数据库

添加五级标签
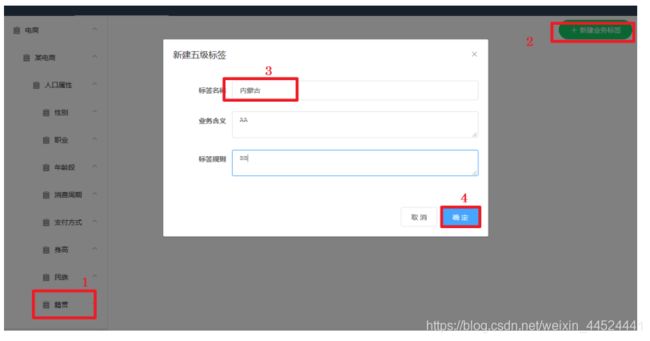

打标签示例

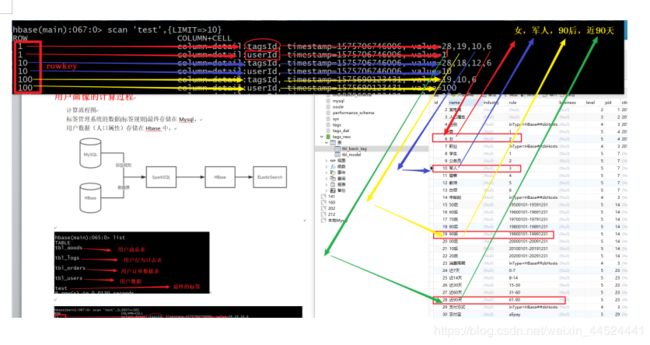
用户画像的计算过程
计算流程图
标签管理系统的数据(标签规则)最终存储在Mysql。

用户数据(人口属性)存储在Hbase中。
Hbase数据说明

使用Spark读取mysql标签数据,读取hbase用户数据, 进行标签计算(匹配,统计,挖掘),打标签,计算出标签后将标签写入Hbase。
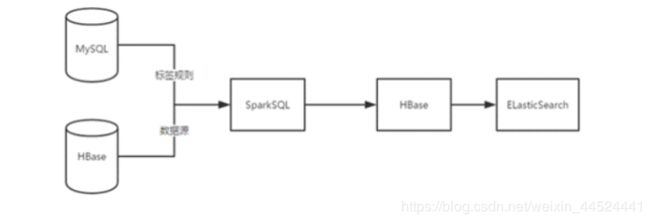
计算后的结果

标签数据说明
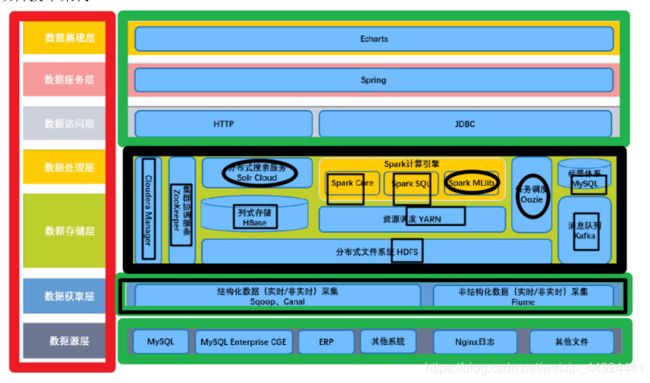
项目技术架构
项目计算流程架构

需求的分类

按照业务类型划分
将分类内的标签记住
- 业务标签一:人口属性
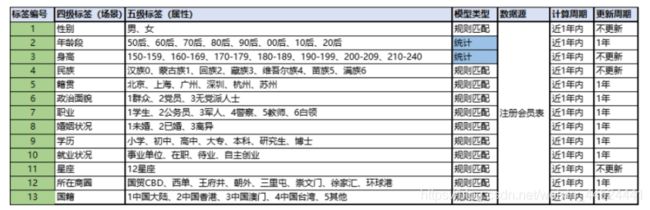
-
业务标签二:商业属性
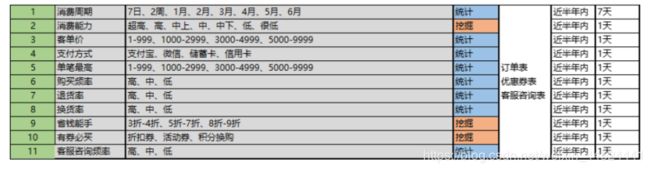
-
业务标签三:行为属性

-
业务标签四:用户价值

分类标签说明
一级、二级、三级标签说明(添加一次)

四级标签:频繁添加,删除等
五级标签: 频繁添加,删除等
四级五级标签详细说明
每一个四级的标签都要独立的编写一个jar文件

四级标签详细说明

五级标签详细说明
