Python与MySQL联动实例一两则
Python 2.7
IDE Pycharm 5.0.3
PyMySQL 0.7.6
MySQL 5.7
MySQL Workbench 6.3
回家有点颓废了,练个小内容,把抓到的数据写到SQL里面,存起来,以后用作数据分析用吧。
扫盲
MySQL读法: “My Ess Que Ell”(not “my sequel”)
来,跟我读,“My Ess Que Ell”哈哈,这可是官方说法,是不是面试的时候又可以抖个机灵。。。。。“会什么?””My Ess Que Ell”“啥?”“就是数据库。。”“你走,我们公司不要你这样装逼的”
正题时间
首先Mysql稍微知道点,什么select,from等等就可以了,建议按照mysql必知必会敲一遍就熟悉了,当然我现在也忘得差不多了,就是捡起来比没学的快那么一点。。。跑题了
建立数据库(在Command Line Client操作)
注意分号结尾
注意mysql中不区分大小写,所以命令和名字最好区分一下看着舒服,我就懒得大小写切换了。打个比方
mysql> create database scrapying;↑ 和 ↓ 是一样的效果
mysql> CREATE DATABASE scrapying;最后输出:
Query OK, 1 row affected (0.00 sec)指定使用数据库
mysql> use scrapyingDatabase changed创立一个数据表来存放数据,最少要有一列
mysql> create table pages(id bigint(7) not null auto_increment,title varchar(200),content varchar(10000),created timestamp default current_timestamp,primary key(id));Query OK, 0 rows affected (0.33 sec)这里稍微了解下参数设么意思;
#整数数据类型bigint,它应用于整数超过int数据范围的场合
#auto_increment 就是对主键 id 自动增加编号的
#VARCHAR(200),可以存入200个字符,不足的话直接按照实际长度,char则是不足按空格填充
#CURRENT_TIMESTAMP,时间戳上述之后,数据库中的一个名为pages的数据表就创建好了
查看一下自己创建的数据表
mysql> describe pages;显示如下
+---------+----------------+------+-----+-------------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+----------------+------+-----+-------------------+----------------+
| id | bigint(7) | NO | PRI | NULL | auto_increment |
| title | varchar(200) | YES | | NULL | |
| content | varchar(10000) | YES | | NULL | |
| created | timestamp | NO | | CURRENT_TIMESTAMP | |
+---------+----------------+------+-----+-------------------+----------------+
4 rows in set (0.00 sec)突然觉得数据库好优美有木有,和python结合简直perfect!
随便键入值存储
mysql> insert into pages(title,content) values("test page title","this is content values");之后可以在workbench上看下键入效果,也可以直接在command line上查看下,使用命令
mysql> select * from pages where title like "%test%";显示如下
+----+-----------------+------------------------+---------------------+
| id | title | content | created |
+----+-----------------+------------------------+---------------------+
| 1 | test page title | this is content values | 2016-08-01 08:54:56 |
+----+-----------------+------------------------+---------------------+
1 row in set (0.00 sec)删除数据库操作
mysql> drop database 数据库名称;结合Python
这里我使用pymysql的第三方库PyMySQL 下载,你也可以使用mysql-connector-python:是MySQL官方的纯Python驱动;我试过,感觉没这个好用,你可以尝试@廖雪峰–使用MySQL
安装PyMySQL
1.下载好后解压压缩包
2.打开cmd窗口,采用命令cd 路径名,切换到解压文件路径下
3.使用命令 python setup.py install
Python和MySQL联动
以一个栗子实现,上一篇写了“抓老师”的实现代码,如果不嫌烦可以看下BeautifulSoup使用一两则(不定期补充),这里写入数据库只写入名字和对应的超链接,其余的应该多是一个道理,就不浪费时间了。
代码
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import re
import pymysql
import random
import datetime
#核心代码--关于数据库的写入,调用第三方模块pymysql
conn = pymysql.connect(host = '127.0.0.1',user='root',passwd='A089363b',db='mysql',charset='utf8')
#连接数据库,passwd每个人都不一样,填入自己数据root密码
#注意编码是utf8,不是utf-8
cur = conn.cursor()#实例化光标对象
cur.execute('create database professors')#创建名为professors数据库
cur.execute('use professors')#切到该数据库
cur.execute('create TABLE pages(id BIGINT(7) NOT NULL AUTO_INCREMENT,title VARCHAR(200),content VARCHAR(10000),created TIMESTAMP DEFAULT CURRENT_TIMESTAMP ,PRIMARY KEY(id))')
#整数数据类型bigint,它应用于整数超过int数据范围的场合
#auto_increment 就是对主键 id 自动增加编号的
#VARCHAR(200),可以存入200个字符,不足的话直接按照实际长度,char则是不足按空格填充
#CURRENT_TIMESTAMP,时间戳
random.seed(datetime.datetime.now())
def store(title,content):
cur.execute("insert into pages (title,content) VALUES (%s,%s)",(title,content))
cur.connection.commit()
url = 'http://icec.hrbeu.edu.cn/xintongxueyuan/ShowArticle.asp?ArticleID=138877'
html = requests.get(url)
html.encoding='gbk'
bs = BeautifulSoup(html.text,'lxml')
url_f=[]
p = r"/xintongxueyuan/ShowArticle.asp\?ArticleID=[0-9]+"#正则表达式
patten = re.compile(p)#编译正则表达式
#读取名字和URL
#try/except防止网络问题导致数据故障
try:
for i in range(13,44):
url_f.append(bs.findAll("a",{"href":re.compile("/xintongxueyuan/ShowArticle.asp\?ArticleID=[0-9]+")})[i])
#跳过中间的(校内)
if i < 35:
title = bs.findAll("td",{"class":"STYLE3"})[i-12].get_text()
if i >=35:
title = bs.findAll("td",{"class":"STYLE3"})[i-11].get_text()
content= u'http://icec.hrbeu.edu.cn'+re.findall(r"/xintongxueyuan/ShowArticle.asp\?ArticleID=[0-9]+",str(url_f[i-13]))[0]
store(title,content) #调用store函数写入数据库中
except:
print 'insert mysql failed!'
#无论如何,都必须将数据库关闭,节约资源
finally:
cur.close()#关闭光标对象
conn.close() #关闭连接对象
#一个连接可以有很多光标,一个光标跟踪一种状态信息实现效果
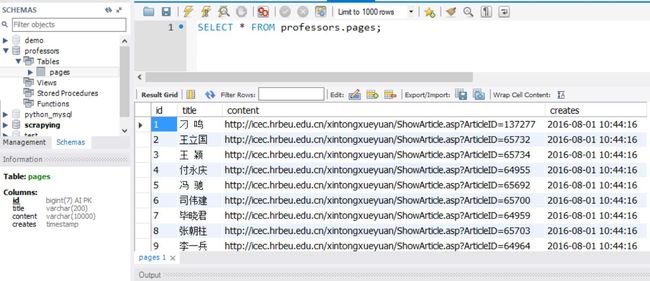
ok,这就是我想要的效果,小功告成!
遇到的问题和解决方案
1.数据写入带了“”问题,如下图描述

1.解决方案,问题出在
cur.execute("insert into pages (title,content) VALUES (\"%s\",\"%s\")",(title,content))的两个引号上,按照python网络数据采集这本书上的例子,他是有引号的,所以排查之后在这里出错,去掉引号即可,因为格式化字符串的方法,写入的就是字符串
2.写入中文出现???现象
2.解决方案,这是因为没有正确规定编码,连接数据库时候加入这句话charset='utf8'即可
为了保险起见,让自己的数据库支持unicode比较好,加入四句话,注意对对应的数据库进行操作:
mysql> alter database scrapying character set = utf8mb4 collate = utf8mb4_unicode_ci;
mysql> alter table pages convert to character set utf8mb4 collate utf8mb4_unicode_ci;
mysql> alter table pages change title title varchar(200) character set utf8mb4 collate utf8mb4_unicode_ci;
mysql> alter table pages change content content varchar(10000) character set utf8mb4 collate utf8mb4_unicode_ci;四句话的内容有,数据库,数据表,以及两个字段的默认编码都是从utf8mb4转变为utf8mb4_unicode_ci
致谢
Python网络数据采集[Ryan Mitchell著][人民邮电出版社]
@MrLevo520–BeautifulSoup使用一两则(不定期补充)
@廖雪峰–使用MySQL