Minio Hadoop-3.3.0 Spark-3.0.0 集群搭建和代码测试
文章目录
- 任务简介
- 主要参考
- 挂载磁盘
- 配置hosts和SSH免密登录
- 安装Minio集群
- 配置node环境
- 配置Hadoop
- YARN
- Spark
- Spark访问minio文件
- spark local
- spark standalone cluster
- spark yarn
- pyspark
- koalas
任务简介
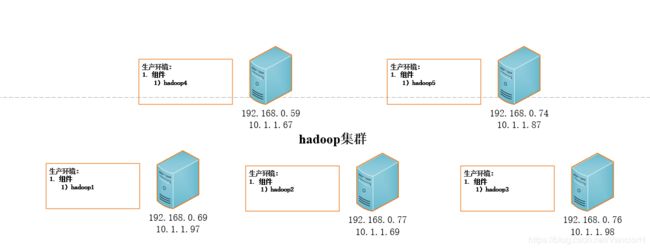
此项任务主要是给组里搭建一套用于数据分析的Spark集群,共5台4C8G的机器,集群内IP和外网IP如下图所示。先搭建了Minio集群用于一些安装包的分发(并且Minio可以通过网页上传数据文件,在Spark中使用s3地址进行访问方便使用),再进行Hadoop-3.3.0的搭建,再在Hadoop的基础上搭建Spark-3.0.0。在配置的过程中尽量做到最小配置,搞懂每个配置项的用途。时间原因暂时未加入HA支持。
主要参考
linode post
hadoop doc
挂载磁盘
按具体需求挂载磁盘作为安装和数据文件夹,在每个node上执行。
fdisk /dev/vdb
# p # 查看
# n # 创建新partition
# p # primary
# 1 # partition number
# 下面两条均默认,其实上面两条也是默认值,一路回车就行了
# p # 查看创建成功
# w # 保存退出
mkfs.ext4 /dev/vdb1
blkid # 查看vdb1的UUID
vim /etc/fstab
# 新增如下条目
# UUID=刚才查看的UUID /data ext4 defaults 0 2
mkdir /data
mount -a
配置hosts和SSH免密登录
在master(hadoop1)上执行。
echo -e "192.168.0.69\thadoop1\n192.168.0.77\thadoop2\n192.168.0.76\thadoop3\n192.168.0.59\thadoop4\n192.168.0.74\thadoop5\n" >> /etc/hosts
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys # 重要,start-dfs时即使是master自己也是ssh过去
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop2
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop3
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop4
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop5
ssh hadoop2 "echo -e \"192.168.0.69\thadoop1\n192.168.0.77\thadoop2\n192.168.0.76\thadoop3\n192.168.0.59\thadoop4\n192.168.0.74\thadoop5\n\" >> /etc/hosts"
ssh hadoop3 "echo -e \"192.168.0.69\thadoop1\n192.168.0.77\thadoop2\n192.168.0.76\thadoop3\n192.168.0.59\thadoop4\n192.168.0.74\thadoop5\n\" >> /etc/hosts"
ssh hadoop4 "echo -e \"192.168.0.69\thadoop1\n192.168.0.77\thadoop2\n192.168.0.76\thadoop3\n192.168.0.59\thadoop4\n192.168.0.74\thadoop5\n\" >> /etc/hosts"
ssh hadoop5 "echo -e \"192.168.0.69\thadoop1\n192.168.0.77\thadoop2\n192.168.0.76\thadoop3\n192.168.0.59\thadoop4\n192.168.0.74\thadoop5\n\" >> /etc/hosts"
安装Minio集群
在每个node上执行。
mkdir /data/minio
cp "下载的minio可执行文件路径" /opt/minio && chmod +x /opt/minio
MINIO_ACCESS_KEY=acbot MINIO_SECRET_KEY=acbot123 nohup /opt/minio server \
http://hadoop1/data/minio \
http://hadoop2/data/minio \
http://hadoop3/data/minio \
http://hadoop4/data/minio \
http://hadoop5/data/minio >/dev/null 2>&1 &
完成后访问任一node的9000端口均能使用minio网页端。后续Hadoop和Spark的安装包都先上传到minio,开放bucket的下载权限,然后直接用wget就可以下载了。
注意minio目前不支持动态扩缩容。
配置node环境
Hadoop
cd /data
mkdir hadoop
cd hadoop
wget "http://localhost:9000/test-bucket/hadoop-3.3.0.tar.gz" -O hadoop-3.3.0.tar.gz
tar -xf hadoop-3.3.0.tar.gz
cd .. && ln -s hadoop/hadoop-3.3.0 hadoop-3.3.0 && cd hadoop
Java
cd /data
mkdir java
cd java
wget "http://localhost:9000/test-bucket/jdk-8u261-linux-x64.tar.gz" -O jdk-8u261-linux-x64.tar.gz
tar -xf jdk-8u261-linux-x64.tar.gz
cd .. && ln -s java/jdk1.8.0_261 jdk1.8.0 && cd java
文件目录
mkdir -p /data/hadoop-3.3.0/data/name
mkdir -p /data/hadoop-3.3.0/data/data
mkdir -p /data/hadoop-3.3.0/data/namesecondary
环境变量(只在master上)
编辑/etc/profile.d/hadoop.sh。
export JAVA_HOME=/data/jdk1.8.0
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/data/hadoop-3.3.0
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/sbin:$PATH
# 懒得去创建新账号了
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_RESOURCEMANAGER_USER=root
配置之后执行source /etc/profile即可。
配置Hadoop
目录$HADOOP_HOME/etc/hadoop。
core-site.xml
fs.defaultFS是对于hdfs dfs命令的默认路径,方便使用,见链接。fs.default.name已经处于deprecated状态。
8020端口为默认值,在hdfs-site.xml/dfs.namenode.rpc-address中配置。
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop1:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/data/hadoop/tmpvalue>
property>
configuration>
hdfs-site.xml
dfs.namenode.name.dir这些配置的默认值为${hadoop.tmp.dir}/data/name。
dfs.replication默认为3。
dfs.namenode.http-address默认为0.0.0.0:9870,为WebUI。
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>/data/hadoop/data/namevalue>
property>
<property>
<name>dfs.dataname.data.dirname>
<value>/data/hadoop/data/datavalue>
property>
<property>
<name>dfs.dataname.checkpoint.dirname>
<value>/data/hadoop/data/namesecondaryvalue>
property>
configuration>
hadoop-env.sh
export JAVA_HOME=/data/jdk1.8.0
同步配置
master不会自动同步worker上的配置,如果不同步会在worker上出现missing NameNode address的错误。
for node in hadoop2 hadoop3 hadoop4 hadoop5; do
scp /data/hadoop-3.3.0/etc/hadoop/* $node:/data/hadoop-3.3.0/etc/hadoop/;
done
logs默认目录为$HADOOP_HOME/logs,可以通过设置$HADOOP_LOG_DIR覆盖。
启动HDFS
hdfs namenode -format # 首次启动,否则报错
start-dfs.sh
hdfs dfs -ls / # √
hdfs dfs -ls hdfs://hadoop1:8020/ # master hostname √
hdfs dfs -ls hdfs://192.168.0.69:8020/ # master cluster-ip √
hdfs dfs -ls hdfs://10.1.1.97:8020/ # master public-ip √
hdfs dfs -ls hdfs://hadoop1/ # omit default port √
hdfs dfs -ls hdfs://192.168.0.69/ # √
hdfs dfs -ls hdfs://10.1.1.97/ # √
hdfs dfs -ls hdfs://localhost/ # ×
其他配置参考
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/core-default.xml
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
YARN
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop1value>
property>
configuration>
配置完之后记得同步。
start-yarn.sh
yarn node -list
默认dashboard在resourcemanager的8088。
通过jps -l查看,在master上有如下进程:
66100 org.apache.spark.deploy.master.Master
47701 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
102008 sun.tools.jps.Jps
47947 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
47420 org.apache.hadoop.hdfs.server.namenode.NameNode
在slave上有如下进程:
9121 org.apache.hadoop.hdfs.server.datanode.DataNode
41955 sun.tools.jps.Jps
9262 org.apache.hadoop.yarn.server.nodemanager.NodeManager
26559 org.apache.spark.deploy.worker.Worker
Spark
```shell
cd /data
mkdir spark
cd spark
wget "http://localhost:9000/test-bucket/spark-3.0.0-bin-without-hadoop.tgz" -O spark-3.0.0-bin-without-hadoop.tgz
tar -xf spark-3.0.0-bin-without-hadoop.tgz
cd .. && ln -s spark/spark-3.0.0-bin-without-hadoop spark-3.0.0 && cd spark
cd spark-3.0.0-bin-without-hadoop
cp conf/slaves.template conf/slaves
vim conf/slaves
# hadoop2
# hadoop3
# hadoop4
# hadoop5
cp conf/spark-env.sh.templates conf/spark-env.sh
vim conf/spark-env.sh
# 参考下方
for node in hadoop2 hadoop3 hadoop4 hadoop5; do
scp /data/spark-3.0.0/conf/* $node:/data/spark-3.0.0/conf/;
done
spark-env.sh
export JAVA_HOME=/data/jdk1.8.0
export PATH=/data/hadoop-3.3.0/bin:$PATH
# spark调用hadoop的库
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
# 后续配置pyspark使用
export PYSPARK_PYTHON=python3
export PYSPARK_DRIVER_PYTHON=ipython
# 指定master URL为yarn时需要这两条配置
export HADOOP_CONF_DIR=/data/hadoop-3.3.0/etc/hadoop
export YARN_CONF_DIR=$HADOOP_CONF_DIR
不要把spark/sbin放到PATH里,start-all命令和hadoop冲突。
Spark访问minio文件
之前因为装Spark时选择了spark-3.0.0-bin-hadoop-3.2的包,导致访问s3路径时出了问题,本来期望使用ivy2下载依赖或者用jar包打包依赖都没有解决,就不详细描述踩的坑了,当时执行的如下:
# ivy2配置的代理
export ANT_OPTS="-Dhttp.proxyHost=localhost -Dhttp.proxyPort=1090"
bin/spark-shell \
--packages org.apache.hadoop:hadoop-aws:3.3.0,com.google.guava:guava:29.0-jre \
--conf spark.hadoop.fs.s3a.access.key=acbot \
--conf spark.hadoop.fs.s3a.secret.key=acbot123 \
--conf spark.hadoop.fs.s3a.endpoint=127.0.0.1:9000 \
--conf spark.hadoop.fs.s3a.connection.ssl.enabled=false
碰到java.lang.ClassNotFoundException: Class org.apache.hadoop.fs.s3a.S3AFileSystem not found加了hadoop-aws:3.3.0,碰到java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument加了guava:29.0-jre但错误还是不解决。
所以一定要下without hadoop的包。
spark local
bin/spark-shell \
--conf spark.hadoop.fs.s3a.access.key=acbot \
--conf spark.hadoop.fs.s3a.secret.key=acbot123 \
--conf spark.hadoop.fs.s3a.endpoint=127.0.0.1:9000 \
--conf spark.hadoop.fs.s3a.connection.ssl.enabled=false \
--master local
# sc textFile("s3a://test-data/increment_number.txt") collect() foreach println
# 成功执行
spark standalone cluster
bin/spark-shell \
--conf spark.hadoop.fs.s3a.access.key=acbot \
--conf spark.hadoop.fs.s3a.secret.key=acbot123 \
--conf spark.hadoop.fs.s3a.endpoint=127.0.0.1:9000 \
--conf spark.hadoop.fs.s3a.connection.ssl.enabled=false \
--master spark://hadoop1:7077
# sc textFile("s3a://test-data/increment_number.txt") collect() foreach println
# 成功执行
spark yarn
需要配置YARN_CONF_DIR见上方配置。
bin/spark-shell \
--conf spark.hadoop.fs.s3a.access.key=acbot \
--conf spark.hadoop.fs.s3a.secret.key=acbot123 \
--conf spark.hadoop.fs.s3a.endpoint=127.0.0.1:9000 \
--conf spark.hadoop.fs.s3a.connection.ssl.enabled=false \
--master yarn
# sc textFile("s3a://test-data/increment_number.txt") collect() foreach println
# 成功执行
在yarn上运行时默认executor数量为2,可以通过--num-executors来调节。从jps来看,有两个node上存在org.apache.spark.executor.YarnCoarseGrainedExecutorBackend。
pyspark
在每个node上安装python3及其他包。
apt-get update
apt-get install -y python3-pip
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pip -U
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install numpy pandas ipython
cd /data/spark-3.0.0/python
python3 setup.py install
spark-env.sh上文已配置完毕。
创建py文件:
import numpy as np
import pandas as pd
from pyspark import SparkContext
import pyspark.sql as sql
import time
foo_name = "/tmp/pyspark-pandas-foo-" + str(time.time()) + ".log"
def foo(r): # r的类型是numpy.ndarray
_df = pd.DataFrame(r)
result = _df.max(axis=0)
f = open(foo_name, "a")
f.write(repr(type(r)))
f.write("\n")
return result
bar_name = "/tmp/pyspark-pandas-bar-" + str(time.time()) + ".log"
def bar(r): # r的类型是pandas.Series
f = open(bar_name, "a")
f.write(repr(type(r)))
f.write("\n")
return r
sc = SparkContext()
rdd = sc.parallelize(np.random.rand(100, 100))
rdd.map(foo).map(bar).reduce(lambda x,y: x+y)
rdd2 = sc.parallelize(np.random.rand(100, 100))
rdd2.map(foo).map(bar).reduce(lambda x,y: x+y)
提交:
bin/spark-submit --master yarn --num-executors 4 /root/hujuntao/pyspark-pandas.py
查看各log文件,可以发现4个node各分到50条数据,并且我们发现RDD在进行分发了之后仍然保持着原始的数据类型,只要这个类型是pickle可序列化的(或者自定义serializer)。
koalas
在每个node上安装
pip3 install koalas s3fs
使用ipython执行如下代码之前记得先source $SPARK_HOME/conf/spark-env.sh,否则会出现JNI Error。如果在pyspark中执行则先要把默认的sc.stop()再创建新的SparkContext。
import databricks.koalas as ks
import pyspark as spark
conf = spark.SparkConf()
conf.set("spark.hadoop.fs.s3a.endpoint", "127.0.0.1:9000")
conf.set("spark.hadoop.fs.s3a.access.key", "acbot")
conf.set("spark.hadoop.fs.s3a.secret.key", "acbot123")
conf.set("spark.hadoop.fs.s3a.connection.ssl.enabled", "false")
spark_context = spark.SparkContext.getOrCreate(conf=conf)
sql_context = spark.SQLContext(spark_context)
df = sql_context.read.csv("s3a://test-data/students_final.csv") # df: DataFrame[_c0:string, _c1:string]
kdf = ks.DataFrame(df)
kdf2 = ks.read_csv("s3a://test-data/students_final.csv", names=["id", "name"]) # 测试对s3a的支持
测试koalas基于pyspark的并行,强制并行。
import databricks.koalas as ks
import pyspark as spark
ks.set_option('compute.default_index_type','distributed')
ks.set_option('compute.shortcut_limit',1)
spark_context = spark.SparkContext.getOrCreate()
kdf = ks.DataFrame({"A": range(100)})
def foo(x):
f = open("tmp/kdf", "a")
f.write(repr(x))
f.write("\n")
f.close()
return len(x)
r = kdf.apply(foo)
r.head()
# A 50
# A 50
# Name: 0, dtype: int64
(kdf ** 2).sum()
# A 328350.0
# Name: 0, dtype: float64
很奇怪的是,在worker上可以看到tmp/kdf各有50条数据,但是在driver也可以看到有2条数据。