快速排序 (挖坑法)+partion函数的应用
目录
快排与冒泡排序比较
快排分析
代码如下:
测试结果:
partion函数的应用(第k大数 力扣703)
传统的堆(priority_queue)排序解决第k大数代码:
堆排序结果:
快排partion解决代码:
partion思路结果:
快排与冒泡排序比较
相同:快速排序也属于交换排序,通过元素之间的比较和交换位置来达到排序的目的。
不同:冒泡排序在每一轮只把一个元素冒泡到数列的一端,理论需要n-1轮。故时间复杂度为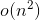
而快速排序采用分治的思想,在每一轮挑选一个基准元素,并让其他比它大的元素移动到数列一边,比它小的元素移动到数列的另一边,从而把数列拆解成了两个部分。需要 轮,每个部分减小到1,从而有序。平均时间复杂度
轮,每个部分减小到1,从而有序。平均时间复杂度![]()
快排分析
但是,假如有一个原本逆序的数列,期望排序成顺序数列,则会导致需要n轮分治,最坏时间复杂度为,故pivot应该随机选择

挖坑法移动元素

首先,选定基准元素Pivot,并记住这个位置index,这个位置相当于一个“坑”。并且设置两个指针left和right

从right指针开始,把指针所指向的元素和基准元素做比较。如果比pivot大,则right指针向左移动;如果比pivot小,则把right所指向的元素填入坑中。
在当前数列中,1<4,所以把1填入基准元素所在位置,也就是坑的位置。这时候,元素1本来所在的位置成为了新的坑。同时,left向右移动一位。

left左边绿色的区域代表着小于基准元素的区域。
接下来,我们切换到left指针进行比较。如果left指向的元素小于pivot,则left指针向右移动;如果元素大于pivot,则把left指向的元素填入坑中。
数列中,7>4,所以把7填入index的位置。这时候元素7本来的位置成为了新的坑。同时,right向左移动一位

此时,right右边橙色的区域代表着大于基准元素的区域。
。。。。。。
这时候left和right重合在了同一位置,这一轮完毕,将pivot放到最后重合的位置。

一轮完毕:左边绿色的小于pivot,右边黄色的大于pivot,但是都不一定是顺序的(图中一轮顺序特殊),之后左边右边递归分治,
直到分一个部分为一个数字为止。
代码如下:
int partition(int arrey[], int startindex, int endindex);
void quickSort(int arrey[], int startindex, int endindex)
{
//递归结束条件 startindex >= endindex
if (startindex >= endindex)
return;
//得到基准元素
int pivotindex = partition(arrey, startindex, endindex);
//用分治法递归数列的两部分
quickSort(arrey, startindex, pivotindex);
quickSort(arrey, pivotindex + 1, endindex);
}
int partition(int arrey[], int startindex, int endindex)
{
//取第一个元素作为privot
int pivot = arrey[startindex];
int left = startindex;
int right = endindex;
int hole_index = startindex;
while (right > left)
{
while (right >= left)
{
if (arrey[right] < pivot)//右指针小于pivot
{
arrey[left] = arrey[right];//用右指针填坑
hole_index = right;//坑转移到右指针
left++;//左指针处的坑被填,左指针加1
break;
}
right--;//若有指针大于pivot则有指针左移
}
while (right >= left)
{
if (arrey[left] > pivot)
{
arrey[right] = arrey[left];
hole_index = left;
right--;
break;
}
left++;
}
}
arrey[hole_index] = pivot;//坑的位置填入pivot
return hole_index;//返回坑的位置
}
//测试程序
void main()
{
int arrey[] = { 3,1,6,4,9,10,12,20,18,17,16,5,22};
int len = sizeof(arrey) / sizeof(*arrey);
printArrey(arrey, len);
quickSort(arrey, 0, len - 1);
printArrey(arrey, len);
system("pause");
}
确定 取消 测试结果如下:

partion函数的应用(第k大数 力扣703)
设计一个找到数据流中第K大元素的类(class)。注意是排序后的第K大元素,不是第K个不同的元素。
你的 KthLargest 类需要一个同时接收整数 k 和整数数组nums 的构造器,它包含数据流中的初始元素。每次调用 KthLargest.add,返回当前数据流中第K大的元素。
示例:
int k = 3; int[] arr = [4,5,8,2]; KthLargest kthLargest = new KthLargest(3, arr); kthLargest.add(3); // returns 4 kthLargest.add(5); // returns 5 kthLargest.add(10); // returns 5 kthLargest.add(9); // returns 8 kthLargest.add(4); // returns 8
说明:
你可以假设 nums 的长度≥ k-1 且k ≥ 1。
传统的堆排序解决第k大数代码:
//用堆来保存k个数据,流式进入的数据
//则不停地和堆顶(最小元素)比较,大于则弹出堆顶入队。否则跳过
class KthLargest {
public:
KthLargest(int k, vector nums) {
for (int i = 0; i < nums.size(); i++)
{
if (q2.size(), greater >q2;
int mk;
}; 堆排序结果:
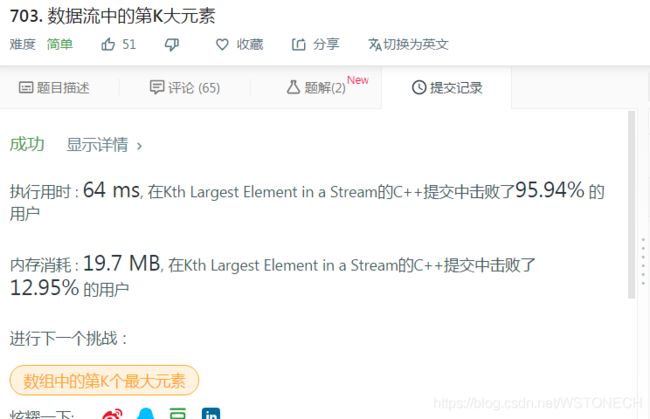
快排partion解决代码:
写入KthLargest(int k, vector
int KthMax(vector&num, int k, int m, int n)
{
int base = num[m];
int i = m, j = n;
while (i < j)
{
while (i < j) {
if (num[j] > base)
{
num[i++] = num[j];//i++ 坑转移至j
break;
}
j--;
}
while (i < j) {
if (num[i] < base)
{
num[j--] = num[i];
break;
}
i++;
}
num[i] = base;
}
if (k - 1 < i)
KthMax(num, k, m, i - 1);
if (k - 1 > i)
KthMax(num, k, i + 1, n);
else
return num[k - 1];
} partion思路结果:
开学研二了,c++基础基本学的差不多了,linux网络编程也开始看了,实验室师妹师弟也来了,老师换是么有给我科研方方,感觉毕业困难,老师说了自由发挥,参考科研方向给了自组网,人工智能,嗯嗯就7个字,反正他说他也不会,我随便做。阿西吧。。。上面师兄么人做过,我也不知道从何着手,为毛上研上通信?肯定是脑子进水了,师兄找工作感觉学java就是好,学通信什么也不好,哎一失足成千古恨,安慰一下自己,患有一年,好好自学吧。