snort学习以及规则编写
一、结构
CIDF模型(Common Intrusion Detection Framework):
包含事 件生成器(event generator:E-boxes),分析引擎(analysis engines:A-boxes),存储机制(storage mechanisms:D-boxes),以及响应模块(countermeasures:C-boxes)
SNORT数据流
snort
并没有原生的数据包抓取功能,基于一个外部的数据包修改库: libpcap 实现了这个功能。事实上,
2.9
版本的
snort
还可以配置使用其他的包抓取模块,它实现了一个
DAQ 模块
,对如
libpcap
进行了上层封装。先在可选的替代有如
BPF(Berkeley Packet Filter),PF_RING 等。snort的数据流如下图所示:

还有很多snort其他相关的内容,我并不过多的深入了解了,工作中主要对snort规则进行编写,所以着重于对snort规则编写进行笔记的记录
二、编写Snort规则
拿一条规则来举例:
alert tcp any any -> any any (msg:"xxx"; sid:12345;)
规则头
动作actions
|
Action(动作)
|
描述
|
仅支持 Inline mode
|
| alert |
基于规则对应的告警消息生成一个警告,并将数据包记录日志
|
|
|
log
|
将数据包记录日志
|
|
|
pass
|
忽略这个数据包
|
|
|
Drop
|
使用 iptables 丢弃这个数据包并将数据包记录入日志
|
yes |
|
Reject
|
使用 iptables 丢弃数据包,记录日志,并发送一个 TCP reset(TCP
协议),或者发送一个 ICMP 端口不可达消息(UDP 协议)
|
yes |
|
Sdrop
|
使用 iptables 丢弃数据包,但不记录日志(silent drop)
|
yes |
协议protocol
Snort
已经支持的协议有
IP,TCP,UDP,ICMP.
IP
地址可以支持
CIDR
模式,
/24
代表一个
C
段网络,
/16
代表一个
B
段网络,
/32
代表一个特定机
器地址。
端口号
port
端口号可以被顶一个多种方式,包括静态的端口定义、端口范围、或者取反。
”any”
则指任意端口。
方向操作符
direction
仅支持两种方向操作符:
”->” “<>”
通用规则选项
| keyword | 描述或范例 |
| msg |
msg:" |
|
reference
|
alert tcp any any -> any 7070 (msg:"IDS411/dos-realaudio"; \
flags:AP; content:"|fff4 fffd 06|"; reference:cve,1234-5678;)
|
|
sid
|
标识规则的编号 |
| rev |
定义规则版本,允许使用更新的规则替代旧版本规则。
|
Payload Detection规则选项
Content
用于匹配网络流量中的静态模式.每当规则中有一条 content 匹配检测发生的时候,引擎将使用Boyer-Moore 算法对待检测数据包执行针对 content 内容的匹配运算
; \ "需要转义,也可以使用!来做取非操作,!对整个content搜索的结果取非
下面的修饰符可以改变content的行为:
| keyword | 描述或范例 | 备注 |
|
offset
|
定义搜索起点(基于整个数据包头)
|
默认偏移为0 |
|
depth
|
定义搜索深度 | 既然是深度,那么depth的值一定不能小于content的长度,否则会报错 |
|
distance
|
定义下一个conntent的搜索起点(基于前一个数据包) | 该关键字肯定要两个或以上的content,并且是第二个之后的content使用的,加上distance关键字,就说明两个content有了前后关系 |
| within | 定义后面content的搜索深度 | 有了within,说明有了默认的distance:0;distance定义了搜索起点,within定义了搜索深度 |
| nocase | 使大小写不敏感 | 可以防止大小写绕过 |
| fast_pattern |
强制指定了入口条件,方便快速匹配
|
进入了规则后,还将对这个content重新匹配一次 |
| raw_bytes |
基于未进一步处理的
raw packet data
进行检测,忽略所有预处理器的解码工作。
|
无 |
|
多个
content的修饰
|
http_method
http_uri
http_header
http_cookie
http_client_body
http_raw_cookie
http_raw_header
http_raw_uri
http_stat_code
http_stat_msg
http_encode
|
1、限定从
HTTP
请求的
method
部分进行
content
匹配
2、对正规化的
URI
区域进行
content
匹配。
3、解析获得的
header
部分会是被正规化的数据
(normalized)
进行
content
匹配
4、对于
HTTP
请求,获取的是
"Cookie:"
之后内容;对于
HTTP
响应,获取的是
"Set-Cookie:"
之后的内容,并以 CRLF
识别为
cookie
结尾。进行
content
匹配。
5、http_client_body
的
raw data.
6、对未经规范化
(Unnormalized cookie)
请求
cookie
或者响应
cookie
进行
content
匹配。
7、对 未 经 正 规 化 的
header
进 行
content
匹 配 。
8、对未经过正规化的
URI
区域进行
content
匹配。
9、基于服务器响应中的
status code
进行
content
匹配。
10、基于服务器响应中的
Status Message
进行
content
匹配。
11、允许针对
http
请求和响应的编码情况进行匹配。
不允许在对同一个 content
使用了
rawbytes
修饰符后再使用该修饰符。
|
| uricontent |
uricontent
关键字用于告知
snort
在规范化
(NORMALIZED)
的
URI
区域搜索匹配。和使用
content
配合 http_uri
修饰后的效果相同。
|
uricontent进行了规范化:
/scripts/..%c0%af../winnt/system32/cmd.exe?/c+ver
规范化成:
/winnt/system32/cmd.exe?/c+ver
|
|
urilen
|
告知
snort
检查
uri
的长度
urilen:<5;(长度小于5)
urilen:5<>10; (长度在5~10之间)
urilen:>500,norm;(规范化后长度大于500) urilen:>500,raw; (基于raw缓冲区,长度大于500) |
无 |
isdataat
验证payload在特定位置存在数据
eg:alert tcp any any -> any 111 (content:"PASS"; isdataat:50,relative; \content:!"|0a|"; within:50;)
这条规则检测
PASS
这个字符串在流量数据包中是否存在,在匹配成功后将检测
PASS
之后至少有
50
字节长度的数据。如果确认这个位置存在数据,则将以 PASS
后第一个字节开始,搜索
50
字节内是否不存在"|0a|"(换行字符
)
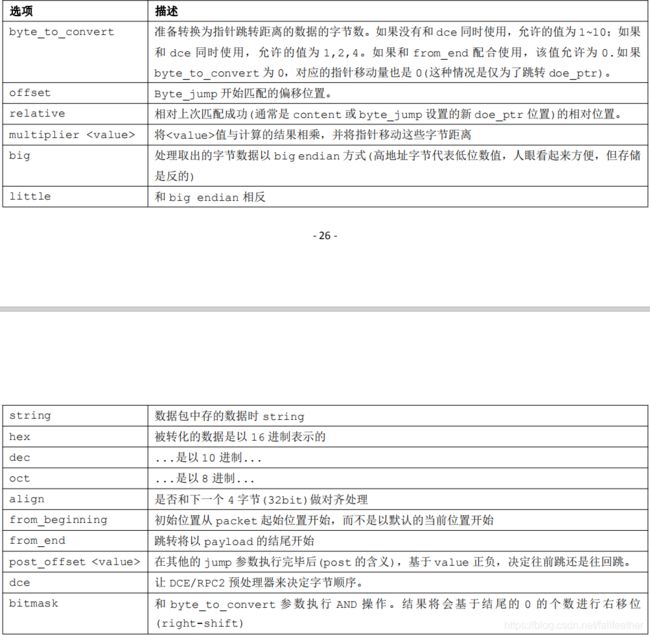
长度编码与指针跳转byte_xxx
| keyword | 描述 |
| byte_jump | 可以取出特定位置的字节数据,跳过该数据的整数位 eg:取出的数据位00 00 00 08 就跳8位 |
| byte_test | 检测一个字节区域代表的数值和某个值的关系 |
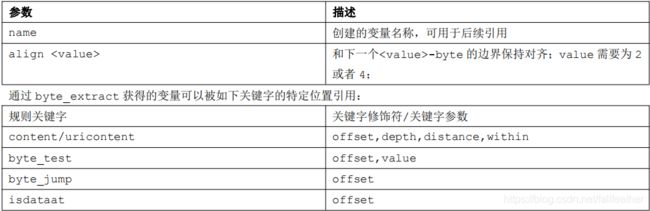
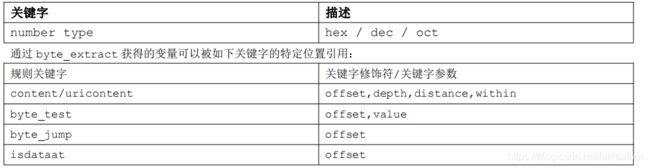
| byte_extract |
读取特定位置的一定数量的字节,并将之保存到一个变量中。这个变量可以在后续同一条规则中引用。每条规则最多创建两个基于
byte_extract
获得的变量。但两个变量可以被引用多次。
|
| byte_math |
基于
extracted
数值与特定变量或常量进行数学运算,并存储这个新的值到一个新的变量中。这个新的变 量可以在同一条规则中被引用。
|
关键字使用格式以及选项
byte_jump
byte_jump:, [, relative][, multiplier ] \
[, ][, string, ][, align][, from_beginning][, from_end] \
[, post_offset ][, dce][, bitmask ];
bytes = 1 - 10
offset = -65535 to 65535
mult_value = 0 - 65535
post_offset = -65535 to 65535
bitmask_value = 1 to 4 bytes hexadecimal value
byte_test
byte_test: , [!], , \
[, relative][, ][, string, ][, dce] \
[, bitmask ];
bytes = 1 - 10
operator = ’<’ | ’=’ | ’>’ | ’<=’ | ’>=’ | ’&’ | ’ˆ’
value = 0 - 4294967295
offset = -65535 to 65535
bitmask_value = 1 to 4 byte hexadecimal value
byte_extract
byte_extract:, , [, relative] \
[, multiplier ][, ][, string][, hex][, dec][, oct] \
[, align ][, dce][, bitmask ];
bytes_to_extract = 1 - 10
operator = ’<’ | ’=’ | ’>’ | ’<=’ | ’>=’ | ’&’ | ’ˆ’
value = 0 - 4294967295
offset = -65535 to 65535
bitmask_value = 1 to 4 byte hexadecimal value
byte_math
byte_math:bytes , offset , oper ,
rvalue , result [, relative]
[, endian ] [, string ][, dce]
[, bitmask ];
bytes_to_extract = 1 - 10
operator = ’+’ | ’-’ | ’*’ | ’/’ | ’<<’ | ’>>’
r_value = 0 - 4294967295 | byte extract variable
offset_value = -65535 to 65535
bitmask_value = 1 to 4 byte hexadecimal value
- 30 -
result_variable = Result Variable name
pcre
使用格式:
pcre:[!]"(//|m)[ismxAEGRUBPHMCOIDKYS]";

base64_decode 和 base64_data
流量特征如下所示:
GET /PSIA/Custom/SelfExt/userCheck HTTP/1.1Connection: keep-aliveAccept: */*Accept-Encoding: gzip, deflateAuthorization: Basic YWRtaW46MTIzNDU= Host: 103.240.34.46User-Agent: python-requests/2.20.1
注:
"
YWRtaW46MTIzNDU=
"
是如下数据的
base64
编码结果:
"
admin:12345
"
规则示例:
alert tcp any any -> any $HTTP_PORTS \(msg:"base64 test"; flow:stateless; content:"Authorization: Basic"; \base64_decode:relative; base64_data; content:"admin:12345"; nocase; \reference:cve,2017-7921; sid:11070087; rev:1;)
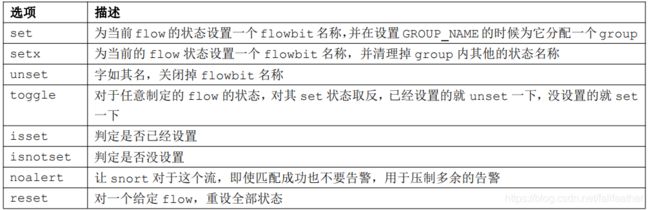
flowbits
用于会话跟踪的场景,对于
TCP
会话特别有用,允许跟踪应用层的协议。规则编写者可以为自己设定的某个会话状态设定一个名称,一些关键字使用 group name
。当没有
group name
的时候,
snort
引擎将认为它是默认的 group
。一个特定的
flowbit
可以属于多个
group
,
Flowbit name
和
group name
命名应使用[ a-zA-Z0-9.-_ ]
eg:
alert tcp any 143 -> any any (msg:"IMAP login";content:"OK LOGIN"; flowbits:set,logged_in;flowbits:noalert;)------alert tcp any any -> any 143 (msg:"IMAP LIST"; content:"LIST";flowbits:isset,logged_in;)