《Cortex™-A系列编程者指南(V3.0)》第4章笔记
文档来源:DEN0013C_cortex_a_series_PG.pdf
文档说明:前三章略过,值得关注的是Linaro网站:www.linaro.org
本章介绍ARM处理器的基础特性,包括寄存器、工作模式和指令集的细节。我们也会涉及一些处理器实现细节,包括指令流水线和分支预测。
ARMv7架构是一个32位处理器架构。它是一种load/store架构,意味着数据处理指令操作通用寄存器中的值。只有加载(load)和存储(store)指令访问存储器。通用存储器也是32位的。本书中,字(word)代表32位,双字(doubleword)代表64位,半字(halfword)代表16位宽。
尽管ARMv7架构是一种32位架构,单独的处理器对所有模块和内部连接的实现不一定必须都是32位宽。例如,对于指令获取和数据访问,具有64位或更宽的路径是可能的。
实现ARMv7-A架构的处理器不具有由架构固定的存储器映射。处理器能访问4GB的虚拟地址空间,存储器和外设都可以在那个空间范围之内自由地映射。我们将会在第9章和第10章中讲述存储器管理,那里我们会看到缓存和内存管理单元(MMU)。
4.1 指令集
大多数ARM处理器支持超过一种指令集:
>ARM--- 一种32位指令集
>Thumb--- 一种16位指令集,具有更好的代码密度(但是相比ARM代码,性能有所降低)
在程序的控制之下,处理器可以在这两种指令集之间来回切换。
所有的Cortex-A系列处理器实现了Thumb-2技术,它扩展了Thumb指令集。混合使用32位和16位指令,以Thumb指令集的代码密度和接近ARM指令集的性能。自从所有的Cortex-A系列处理器支持这一扩展,针对它们的软件常被编译成Thumb指令集。(本文作者注:按照文章《如何使用Thumb-2改善代码密度和性能》所述,Thumb-2代码大小约为ARM代码的74%,性能则为其98%)
4.2 模式
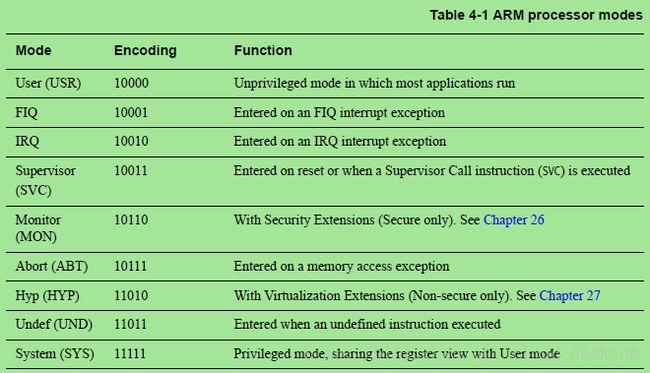
ARM架构有9种处理器模式,在表4-1中所总结。有8种特权模式和一种非特权模的用户模式。在用户模式,在某些操作上具有限制,例如MMU访问,修改操作模式是一种特权操作。注意,模式与异常事件有联系,将会在第12章异常处理中讲述。
4.3 寄存器
ARM架构具有一批通用寄存器,提供处理器内部的数据存储。除了通用寄存器,还有R15,程序计数器,和包含ALU标志位与其它执行状态信息的程序状态寄存器。这些寄存器中很多是分组的,那就是,除非是在特定处理器模式,否则处理器不能访问。当进入一个不同的处理器模式,这些分组的寄存器自动地切入和换出。每个异常模式(不包括系统模式)附加有一个备份程序状态寄存器,包含一份异常触发时程序状态寄存器的拷贝。
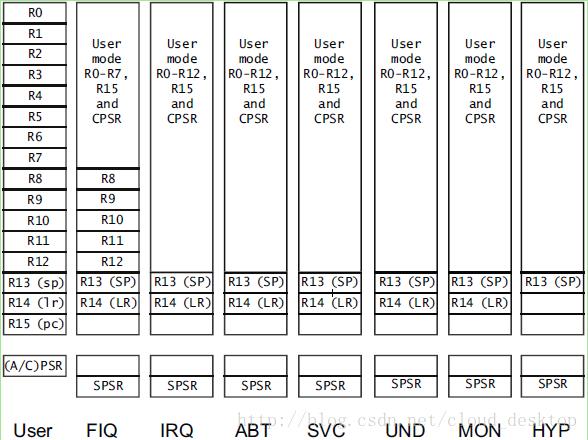
因此,在图4-1中,如果处理器是在IRQ模式,我们可以看见R0,R1...R12(与在用户模式看到的相同的寄存器),加上SP_IRQ和LR_IRQ(仅在IRQ模式中可以访问的寄存器)和R15(程序计数器,PC)。我们通常不必指定模式中的寄存器名。如果我们在一行代码中引用R13,处理器会访问当前模式对应的SP寄存器。
在用户模式,程序状态寄存器(CPSR)的受限形式被称为应用程序状态寄存器(APSR)。R15是程序计数器,保持当前程序地址(实际上,在ARM状态,它总是指向提前8个字节当前指令的位置;在Thumb状态,它总是指向提前4个字节当前指令的位置)。
我们可以写值到PC以修改程序流。LR是链接寄存器,存放函数或异常的返回地址。R13,通常被用作堆栈指针。R0-R12是通用寄存器。一些16位Thumb指令可访问的寄存器受限---可访问的子集被称为低寄存器(low registers),由R0-R7组成。图4-2显示了对通用数据处理指令可见的寄存器子集。

4.3.1 程序状态寄存器
程序状态寄存器形成了一组额外的分组寄存器集。每中异常模式有它自己的备份程序状态寄存器(Saved Program Status Register ,SPSR),当一个异常发生时自动保存一份异常前CPSR拷贝。
《ARM架构参考手册》(ARM Architecture Reference Manual)描述了程序状态是如何在32位应用程序状态寄存器(Application Program Status Register ,APSR)中报告的,其它状态和控制位(系统级信息)任然保留在CPSR。本书中涉及的ARMv7-A架构,APSR实际上同CPSR是相同的寄存器,尽管它们有分开的名字。APSR只能访问N/Z/C/V/Q和GE[3:0]位。这些位通常不能直接访问,由条件代码设置指令设置,并由有条件执行的指令测试。重命名因此是尝试清理旧的ARM架构中CPSR的混合访问,图4-3显示了CPSR的组成。

独立位代表如下:
> N --- 来自ALU的负结果
> Z --- 来自ALU的零结果
> C --- ALU操作进位
> V --- ALU操作溢出
> Q --- 累积饱和
> J --- 指示处理器是否在加速状态
> GE[3:0] --- 由一些SIMD指令使用
> IT[7:2] --- Thumb-2指令组的If-Then条件执行
> E --- 控制load/store字节序
> A --- 禁止异步中止
> I --- 禁止IRQ
> F --- 禁止FIQ
> T --- 指示处理器是否在Thumb状态
> M[4:0] --- 指定处理器模式(FIQ,IRQ等)
处理器可以在模式间切换通过指令直接写CPSR模式位(用户模式不能)。更为常见的,处理器修改模式是异常事件的结果。
4.4 指令流水线
指令流水线是一种被用于处理器设计的技术,提升指令的吞吐量。信息的处理由一连串对输入数据不同的操作组成。为了优化性能,处理器核被设计为级联的基本功能单元块,每个块由前面单元的输出作为输入:在每个时钟,单元N处理单元N-1的输出数据。这么选择主要的原因是简单的处理块能够比复杂的运行得快,因此流水线的结构能够让数字电路设计工作在GHz时钟频率。每个指令从一步移动到另一步,通过几个时钟周期。每个流水线阶段处理执行一个指令过程的一部分,因此在给定的任何时钟周期,一些不同的指令可能会在流水线的不同阶段。处理器的总体速度由最慢一步的速度决定,这比执行所有步骤需要的时间极大地减少。一个非流水线架构较为低效,因为处理器内一些模块会在指令执行期间被闲置。
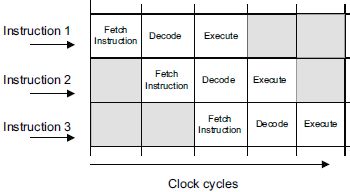
经典的流水线由三个阶段组成 --- 取指、译码和执行,如图4-4中所示。更为普遍地,一个指令流水线会被分成下面广泛的定义:
> 指令预取:决定将会被获取指令在内存中的位置,执行相关总线访问
> 指令获取:从内存系统中读取读取将被执行的指令
> 指令译码:得出将被执行的指令,为数据路径生成合适的控制信号
> 寄存器获取:提供正确的寄存器值
> 发出:发出指令到合适的执行单元
> 执行:实际的ALU或乘法器操作等
> 内存访问:执行数据加载或存储
> 寄存器写回:用结果更新处理器寄存器
在单独的处理器实现时,这些步骤的一些可被组合成一个单一的流水线阶段,或一些步骤可被分布在几个周期。较长的流水线意味着每个流水线之间的关键路径中更少的逻辑门,从而更快地执行。然而,典型地指令之间会有依赖。如果一个指令依赖于前一指令的结果,控制逻辑需要插入位置(或泡沫)到流水线,直到依赖解决。需要附加的逻辑来检测和解决这样的依赖。
一般来说,ARM架构试图对编程者隐藏流水线影响。这意味着,编程者只能通过阅读处理器手册来决定流水线结构。然而,一些流水线工件仍然存在。例如,程序计数器寄存器(R15)在ARM状态时,指向超前于当前正执行指令两个指令的指令,最初ARM1处理器三阶段流水线的遗留物。
长流水线一个更近一步的缺点是有时来自内存的指令的串行执行会被打断。这可能会发生在一个分支指令执行的结果,或被一个异常事件(例如一个中断)。当此发生时,处理器无法决定下一条应该被获取指令的正确位置,直到分支被解决。在典型的代码中,很多分支指令是有条件的,作为循环或者if声明的结果。因此,分支是否会被执行不能再指令获取时决定。如果我们获取的指令紧跟着一个分支,并且分支被执行,流水线必须清空,来自分支目的地的指令新指令集必须从内存获取。随着流水线变长,分支惩罚的代价变得更高。
Cortex-A系列处理器具有分支预测逻辑,目的是减少分支惩罚的影响。本质上,处理器预测一个分支是否会被执行,获取的指令要么来自紧跟分支之后的指令(如果预测表明条件分支不会被执行),要么来自分支的目标指令(如果预测表明分支会被执行)。如果预测正确,分支不会清空流水线。如果预测错误,流水线必须清空,并且获取来自正确位置的指令来充填。我们将在下面的分支预测里看到更多细节。
4.4.1 多发布流水线
一个精致的处理器流水线是我们可以有超过一个硬件单元来处理流水线阶段。在ARM11处理器家族,例如,有三个并行后端流水线 --- 一个ALU流水线,一个load/store流水线和一个乘法流水线。指令可被发布进这些中的任何流水线。这个想法的一个合乎逻辑的发展是,有多个执行硬件的实例 --- 例如两个ALU流水线。我们就可以在一个周期发布超过一个指令到这些并行流水线 --- 一个指令级并行的例子。这样的处理器被称为超标量体系结构(superscalar)。Cortex-A8,Cortex-A9和Cortex-A15处理器是超标量处理器 --- 它们可以在一个时钟周期中潜在地译码和发布超过一个指令。Cortex-A5和Cortex-A7处理器相对受限制,只能双发射特定指令的组合 --- 例如,一个分支和一个数据处理指令可以在同一周期内发布。指令仍然从内存中的串行指令流中发布。需要额外的硬件逻辑来检查指令间的依赖性,例如,在一个指令必须等待其它指令结果的情况下。
乱序执行为提升流水线效率提供了空间。如果指令被串行执行,一个指令在下一个处理之前完全退休。在乱序处理中,多内存访问可以是立刻显著的,并且可以以不同的顺序完成。
经常地,一个指令必须停滞,由于依赖(例如,需要使用来自前面指令的结果)。我们可以执行下面的没有共享这一依赖的指令,提供指令之间的逻辑危害是严格推崇的。Cortex-A9和Cortex-A15处理器使用这一技术实现非常高等级的效率和指令吞吐量。它们可以被认为是可变长度的流水线,因为流水线长度取决于一个指令使用的后端执行流水线。它们可以独立地执行指令,并且在每个时钟可以译码两个指令,但是有在一个独立时钟周期发布最高四条指令的能力。这可以提高性能,如果流水线已经变得畅通,前面由于一些原因停滞了。
4.4.2 寄存器重命名
Cortex-A9处理器有一个有趣的微架构实现,使用了一个寄存器重命名方案。作为标准ARM架构一部分的寄存器集对程序员可见,但是处理器的硬件实现实际上有一个更为大的物理寄存器池,逻辑上动态地映射程序员可见寄存器到物理寄存器。图4-5显示了分开的架构寄存器池和物理寄存器池。
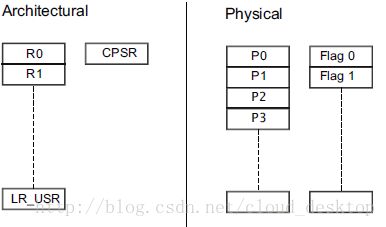
考虑一种情况,代码写一个寄存器的值到外部存储器,紧接着其后,读取一个不同外部存储器位置的值到相同的寄存器。这在前面的处理器中可能会引起流水线停滞,尽管在此特殊的例子中,没有实际上的数据依赖。寄存器重命名避免这个问题,通过确保两个R0实例被重命名到不同的物理寄存器,移除了依赖。这允许了一个编译器或汇编程序员在没有内部指令之间的依赖时,重用寄存器,而不需要考虑因为重用寄存器导致的架构上的惩罚。重要的是,这允许了write-after-write和write-after-read序列的乱序执行。(write-after-write的危害出现在两个独立的指令写值到相同的寄存器。处理器必须确保来自这两条指令之后的指令看到的是后一条指令的结果)
为避免与标志位设置和比较相关的指令间的依赖,APSR标志也使用相同的技术。
4.5 分支预测
如我们已看到的,分支预测逻辑在Cortex-A系列处理器中对实现高吞吐量是一个重要的因素。没有分支预测,我们不得不等待知道一个条件分支执行,在我们能够决定获取下一条指令位置之前。
一个条件跳转指令第一次被获取时,没有关于下一条指令地址的可依赖信息。旧的ARM处理器使用静态分支预测。这是最简单的分支预测方法,因为它不需要关于分支的先前信息。我们推测向后的分支会被采用,向前的分支不会。向后的分支具有一个目标地址,低于它自己的地址。我们因此可以看一个单一的操作位来决定分支方向。这个技术可以给与合理的预测精度,归因于代码中循环的普遍,循环代码总是包含后向分支,并且后向总比前向多很多。由于Cortex-A系列处理器的流水线长度,我们通过使用更为复杂的给予更好预测精度的分支预测方法,可以获得更好的性能。
动态分支预测可以进一步减少平均分支惩罚,通过使用在前面执行时条件分支是否被采用的历史信息。Cortex-A8处理器中的分支目标地址缓存(Branch Target Address Cache ,BTAC),也称为分支目标缓冲(Branch Target Buffer ,BTB),是一个缓存,保存有前次分支指令执行的信息。它使得硬件能够推测一个条件分支是否会被采用。
处理器仍然必须评估附带在分支指令上的条件代码。如果分支预测硬件预测正确,流水线不必停滞。如果分支预测硬件评估错误,处理器必须清空流水线并充填它。
4.5.1 返回堆栈(return stack)
在分支预测中的描述看到了处理器可以用于预测分支是否会被采用的策略。对绝大多数分支指令,目标地址固定并编码在指令中。然而,有一类分支,分支目标的目的地不能通过看指令决定。例如,如果我们执行一个数据处理操作,它修改了PC(例如,MOV,ADD or SUB),我们必须等待ALU来评估结果,在我们能够直到分支目标之前。类似的,如果我们从内存加载PC,使用一个LDR,LSM,或POP指令,我们不能知道目标地址直到加载完成。
通常,这样的分支(常称为间接分支)不能在硬件上被预测。然而,有一个常见的情况可以很有用地被优化,在预取硬件中使用一个后进先出堆栈(return stack)。任何时候一个函数调用(BL或BLX)指令被执行,我们进入压入接下来的指令到这个堆栈。任何时候当我们遇到一个指令,它可以被识别为函数返回指令(BX LR,或一个在寄存器列表中包含PC的堆栈pop操作),我们可以投机地从堆栈pop一个条目,硬件比较指令生成的地址和堆栈预测的地址。如果未命中,流水线被清空,我们从正确的位置重新开始。
返回堆栈有固定的大小(例如,在Cortex-A8或Cortex-A9处理器中有8个条目)。如果一个特殊的代码序列包含大量嵌套的函数调用,一个8条目返回堆栈可以预测前8个函数返回。
4.5.2 程序员的角度
对于大多数应用级的程序员,分支预测是硬件实现的一部分,可以安全的被忽略。然而,处理器分支行为的知识可以是有用的,当编写高度优化的代码时。硬件性能监视器计数器可以生成关于分支正确与否预测数目的信息。这一硬件在第19章被进一步描述。
分支预测逻辑在复位时被禁止。启动代码序列的一部分典型地会被用于设置CP15:SCTLR(系统控制寄存器)的Z位,这使能了分支预测。有一个其它的情形编程者需要注意。当在一个地址移动或修改代码,在此地址上的代码已在系统中被执行,从分支历史逻辑中移除旧的条目是必要的(并且总是明智的),通过使用CP15指令作废所有条目。