Android Studio Profiler Memory (内存分析工具)的简单使用及问题分析
Memory Profiler 是 Android Studio自带的内存分析工具,可以帮助开发者很好的检测内存的使用,在出现问题时,也能比较方便的分析定位问题,不过在使用的时候,好像并非像自己一开始设想的样子。
如何查看整体的内存使用概况
如果想要看一个APP整体内存的使用,看APP heap就可以了,不过需要注意Shallow Size跟Retained Size是意义,另外native消耗的内存是不会被算到Java堆中去的。
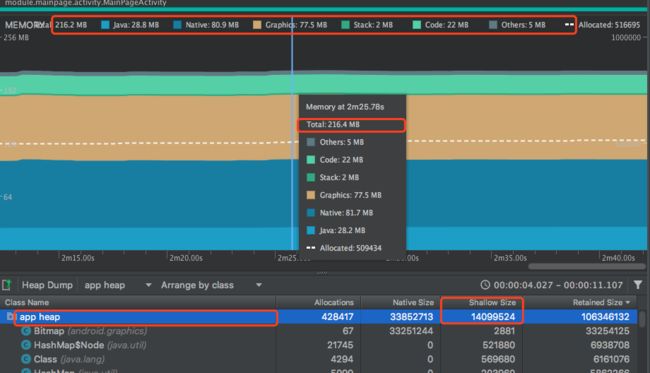
- Allocations:堆中的实例数。
- Shallow Size:此堆中所有实例的总大小(以字节为单位)。其实算是比较真实的java堆内存
- Retained Size:为此类的所有实例而保留的内存总大小(以字节为单位)。这个解释并不准确,因为Retained Size会有大量的重复统计
- native size:8.0之后的手机会显示,主要反应Bitmap所使用的像素内存(8.0之后,转移到了native)
举个例子,创建一个List的场景,有一个ListItem40MClass类,自身占用40M内存,每个对象有个指向下一个ListItem40MClass对象的引用,从而构成List,
class ListItem40MClass {
byte[] content = new byte[1000 * 1000 * 40];
ListItem40MClass() {
for (int i = 0; i < content.length; i++) {
content[i] = 1;
}
}
@Override
protected void finalize() throws Throwable {
super.finalize();
}
ListItem40MClass next;
}
@OnClick(R.id.first)
void first() {
if (head == null) {
head = new ListItem40MClass();
} else {
ListItem40MClass tmp = head;
while (tmp.next != null) {
tmp = tmp.next;
}
tmp.next = new ListItem40MClass();
}
}
我们创建三个这样的对象,并形成List,示意如下
A1->next=A2
A2->next=A3
A3->next= null
这个时候用Android Profiler查看内存,会看到如下效果:Retained Size统计要比实际3个ListItem40MClass类对象的大小大的多,如下图:
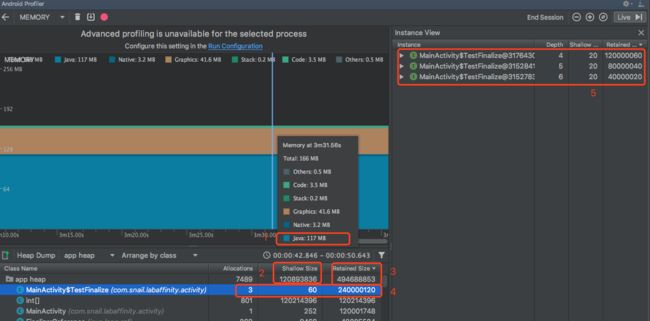
可以看到就总量而言Shallow Size基本能真是反应Java堆内存,而Retained Size却明显要高出不少, 因为Retained Size统计总内存的时候,基本不能避免重复统计的问题,比如:A对象有B对象的引用在计算总的对象大小的时候,一般会多出一个B,就像上图,有个3个约40M的int[]对象,占内存约120M,而每个ListItem40MClass对象至少会再统计一次40M,这里说的是至少,因为对象间可能还有其他关系。我们看下单个类的内存占用-Instance View
- Depth:从任意 GC 根到所选实例的最短 hop 数。
- Shallow Size:此实例的大小。
- Retained Size:此实例支配的内存大小(根据 dominator 树)。
可以看到Head本身的Retained Size是120M ,Head->next 是80M,最后一个ListItem40MClass对象是40M,因为每个对象的Retained Size除了包括自己的大小,还包括引用对象的大小,整个类的Retained Size大小累加起来就大了很多,所以如果想要看整体内存占用,看Shallow Size还是相对准确的,Retained Size可以用来大概反应哪种类占的内存比较多,仅仅是个示意,不过还是Retained Size比较常用,因为Shallow Size的大户一般都是String,数组,基本类型意义不大,如下。
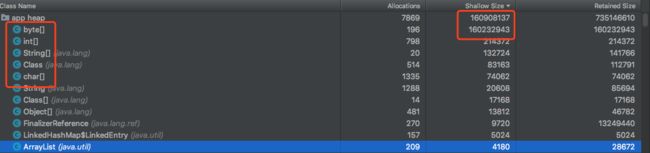
FinalizerReference大小跟内存使用及内存泄漏的关系
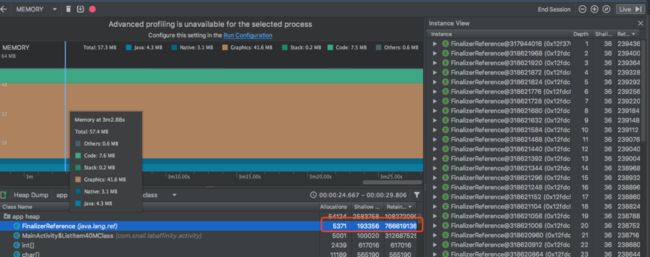
之前说Retained Size是此实例支配的内存大小,其实在Retained Size的统计上有很多限制,比如Depth:从任意 GC 根到所选实例的最短hop数,一个对象的Retained Size只会统计Depth比自己大的引用,而不会统计小的,这个可能是为了避免重复统计而引入的,但是其实Retained Size在整体上是免不了重复统计的问题,所以才会右下图的情况:

FinalizerReference中refrent的对象的retain size是40M,但是没有被计算到FinalizerReference的retain size中去,而且就图表而言FinalizerReference的意义其实不大,FinalizerReference对象本身占用的内存不大,其次FinalizerReference的retain size统计的可以说是FinalizerReference的重复累加的和,并不代表其引用对象的大小,仅仅是ReferenceQueue queue中ReferenceQueue的累加,
public final class FinalizerReference extends Reference {
// This queue contains those objects eligible for finalization.
public static final ReferenceQueue 每个FinalizerReference retained size 都是其next+ FinalizerReference的shallowsize,反应的并不是其refrent对象内存的大小,如下:
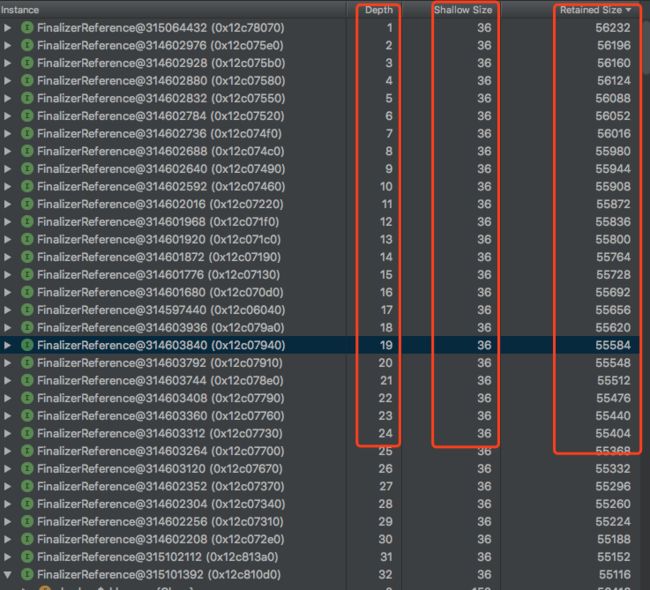
因此FinalizerReference越大只能说明需要执行finalize的对象越多,并且对象是通过强引用被持有,等待Deamon线程回收。可以通过该下代码试验下:
class ListItem40MClass {
byte[] content = new byte[5];
ListItem40MClass() {
for (int i = 0; i < content.length; i += 1000) {
content[i] = 1;
}
}
@Override
protected void finalize() throws Throwable {
super.finalize();
LogUtils.v("finalize ListItem40MClass");
}
ListItem40MClass next;
}
@OnClick(R.id.first)
void first() {
if (head == null) {
head = new ListItem40MClass();
} else {
for (int i = 0; i < 1000; i++) {
ListItem40MClass tmp = head;
while (tmp.next != null) {
tmp = tmp.next;
}
tmp.next = new ListItem40MClass();
}
}
}
多次点击后,可以看到finalize的对象线性上升,而FinalizerReference的retain size却会指数上升。
同之前40M的对比下,明显上一个内存占用更多,但是其实FinalizerReference的retain size却更小。再来理解FinalizerReference跟内存泄漏的关系就比价好理解了,回收线程没执行,实现了finalize方法的对象一直没有被释放,或者很迟才被释放,这个时候其实就算是泄漏了。
如何看Profiler的Memory图
- 第一:看整体Java内存使用看shallowsize就可以了
- 第二:想要看哪些对象占用内存较多,可以看Retained Size,不过看Retained Size的时候,要注意过滤一些无用的比如 FinalizerReference,基本类型如:数组对象
比如下图:Android 6.0 nexus5
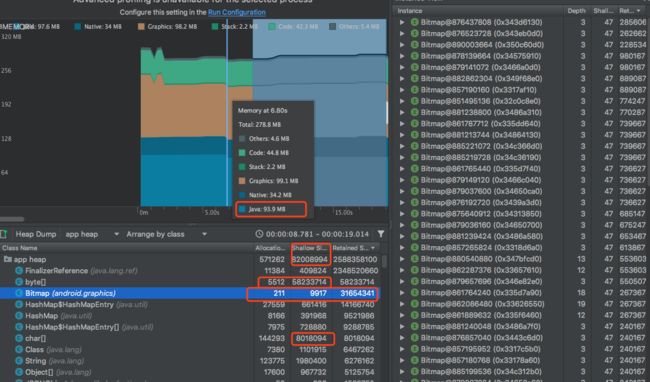
从整体概况上看,Java堆内存的消耗是91兆左右,而整体的shallow size大概80M,其余应该是一些堆栈基础类型的消耗,而在Java堆栈中,占比最大的是byte[],其次是Bitmap,bitmap中的byte[]也被算进了前面的byte[] retain size中,而FinilizerReference的retain size已经大的不像话,没什么参考价值,可以看到Bitmap本身其实占用内存很少,主要是里面的byte[],当然这个是Android8.0之前的bitmap,8.0之后,bitmap的内存分配被转移到了native。
再来对比下Android8.0的nexus6p:可以看到占大头的Bitmap的内存转移到native中去了,降低了OOM风险。
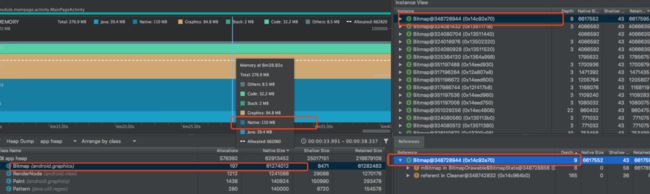
并且在Android 8.0或更高版本中,可以更清楚的查看对象及内存的动态分配,而且不用dump内存,直接选中某一段,就可以看这个时间段的内存分配:如下
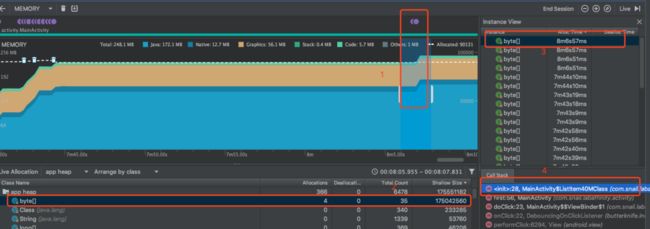
如上图,在时间点1 ,我们创建了一个对象new ListItem40MClass(),ListItem40MClass有一个比较占内存的byte数组,上面折线升高处有新对象创建,然后会发现内存大户是byte数组,而最新的byte数组是在ListItem40MClass对象创建的时候分配的,这样就能比较方便的看到,到底是哪些对象导致的内存上升。
总结
- 总体Java内存使用看shallow size
- retained size只是个参考,不准确,存在各种重复统计问题
- FinalizerReference retained size 大小极其不准确,而且其强引用的对象并没有被算进去,不过finilize确实可能导致内存泄漏
- native size再8.0之后,对Bitmap的观测有帮助。