针对移动端TBDR架构GPU特性的渲染优化
TBDR(Tile-Base-Deffered-Rendering)是现代移动端gpu的设计架构,它同传统pc上IR(Immediate-Rendering)架构的gpu在硬件设计上是差别很大的。手游正是运行在这些移动端的TBDR架构上,所以手游的渲染优化在硬件的角度上讲有其独特之处,甚至一些特点和优化点与PC是大相径庭的,基于硬件的优化是应用程序优化很重要的一部分,最近阅读了一些tbdr的硬件设计的文档,本文试图对TBDR的特点做些介绍并基于这些特点的优化做个简单的总结。
1.为什么移动端选择了tbdr
提到tbdr,很多人第一反应是这是一个DefferedRendering技术,它应该是为了优化渲染的,但是它同我们软件层面的延迟渲染不同,它是在硬件中实现的一种延迟渲染。那么又有很多人又会想到那既然DR这么好的技术,为什么在pc的显卡中不去这么设计,而反而在更加廉价的手机显卡中设计。这要从移动端gpu的一大瓶颈来说起。
移动端的硬件在设计最开始想到的最重要的问题就是功耗,功耗意味着发热量,意味着耗电量,意味着芯片大小…所以gpu也是把功耗摆在第一位,然而在gpu的渲染过程中,对功耗影响最大的是带宽,对,bandwith,这是功耗的第一大杀手。可以算一下,在移动端,一个1920*1080的屏幕上,每渲染一帧图像,对FrameBuffer的访问量是惊人的(各种test,blend,再算上MSAA, overdraw等等),通常gpu的onchip memory(也就是SRAM,或者L1 L2 cache)很小,这么大的FrameBuffer要存储在离gpu相对较远的DRAM(显存)上,可以把gpu想象成你家,SRAM想象成小区便利店,DRAM想象成市中心超市,从gpu对framebuffer的访问就相当于一辆货车大量的在你家和市中心之间往返运输,带宽和发热量之巨大是手机上无法接受的。
于是移动端的gpu想到了一种化整为零的方法,把巨大的FrameBuffer分解成很多小块,使得每个小块可以被离gpu更近的那个SRAM可以容纳,块的多少取决于你的硬件的SRAM的大小。这样gpu可以分批的一块块的在SRAM上访问framebuffer,一整块都访问好了后整体转移回DRAM上,这样问题就解决了。为什么这样可以减少带宽?想想,对FrameBuffer现在几乎全部的访问在渲染这一块的时候(test,read,write,blend…)都完全在SRAM上解决,只在最后把这一块整体渲染完了才整体搬回DRAM。这种模式就叫做TBR(tile-based-rendering),他和pc上从传统的IR(immediate-rendering)的对比如下图。
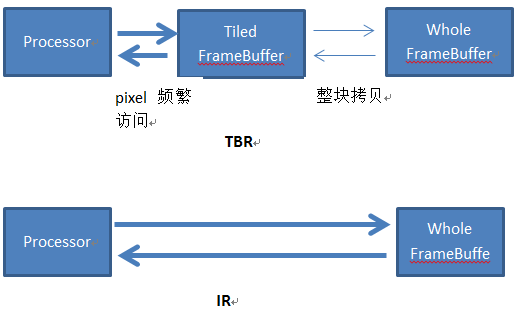
那么为什么pc不使用tbr,这是因为实际上直接对DRAM上进行读写的速度是最快的,tbdr需要一块块的绘制然后回拷,可以说如果哪一天手机上可以解决带宽产生的功耗问题,或者说sram可以做的足够大了,那么就没有TBDR什么事了。可以简单的认为TBR牺牲了执行效率,但是换来了相对更难解决的带宽功耗。
2 FrameData
Ok,tbr的前世今生搞清楚了。然后说说这个TBR种加入的D。在设计了TBR后,移动端gpu接受cpu的绘制指令后的绘制行为其实完全改变掉了。大家可以看到,在tbr的架构上,是不能够来一个commandbuffer就执行一个的,那是噩梦,因为任何一个commandbuffer都可能影响到到整个FrameBuffer,如果来一个画一个,那么gpu可能会在每一个drawcall上都来回搬迁所有的Tile。这太慢了!所以TBR一般的实现策略是对于cpu过来的commandbuffer,只对他们做vetex process,然后对vs产生的结果暂时保存,等待非得刷新整个FrameBuffer的时候,才真正的随这批绘制做光栅化,做tile-based-rendering。什么是非得刷新整个FrameBuffer的时候?比如Swap Back and Front Buffer,glflush,glfinish,glreadpixels,glcopytexiamge,glbitframebuffer,queryingocclusion,unbind the framebuffer..总之是所有gpu觉得不得不把这块fb绘制好的时候。所以tbr的真正的绘制管线是这样的。
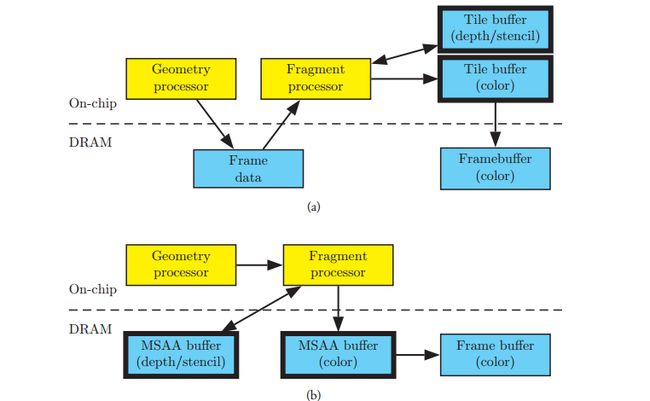
上面是tbr,下面是ir,这里可以看到TBR的管线上在PixelShader之前增多了一个步骤,即vs和gs处理后的数据(这里叫做FrameData)被暂时保存下来排好队,然后后面再对framebuffer分块,然后对每一块,绘制所有影响这个块的pixel。
FrameData这个是tbr特有的在gpu绘制时所需的存储数据,在powervr上叫做arguments buffer,在arm上叫做plolygon lists。既然tbr上是等待所有的framedata数据一起绘制pixel的,那么gpu就又多了一个优化的可能,deffered rendering,现有的大部分tbr的显卡都或多或少做了这个优化,例如ios的powervr,它多了一个叫做ISR的硬件,专门对这些framedata做处理,找到这次渲染真正有可能会被写入到Framebuffer上的那些drawcall,而过滤掉大部分的drawcall。例如对于不透明物体,一些可能不通过ztest的,一些会被stencil reject的,他们在ISR处理framedata后根本都不会进入pixel shader。(所以其实在power vr上对不透明物体的排序是没有太大意义的,而early-z这种策略也是不存在ios上的。)看,硬件巧妙的利用tbr的framedata队列实现了一种延迟渲染,即尽可能只渲染那些最终影响fb的物体,和软件层面的延迟渲染不同的是,软件层面的延迟渲染是针对一个drawcall的,对于从后到前的不透明物体绘制是每次都会绘制的,而硬件层面的延迟渲染时对一批drawcall的,它会从这批绘制里面找到最终要绘制的物体。所以现在大部分的移动端的gpu可以被称为TBDR架构。
3.基于TBDR的渲染优化
Tbdr和pc的gpu 模式有如此之大的不同,那么针对tbdr的特点,我们可以总结一些重要的优化特性,有些甚至和pc是南辕北辙的。
3.1记得不使用Framebuffer的时候clear或者discard
前面说到framedata会一直积攒下来直到等到一些必须要绘制到framebuffer上的时候,这意味着tbdr的架构下commandbuffer不会被立即执行,只是积攒到一定的时间点。而glclear这种操作是可以把当前的framedata清空的,这样就会节省很多不必要的绘制。
设想一种情况,你一直往一个Rendertexture上绘制,过了一会当你不再使用这张rendertexture的时候(即unbind)也会触发这些framedata的绘制,如果在你不再使用这张图之前能够调用一次clear,那么unbind的时候framedata就是清空的,可以减少很多不必要的绘制。在gl上还有这样一个扩展EXT_discard_framebuffer可以更加明显的暗示当前的这个framebuffer不需要使用了,framedata将被清空。
所以在unity里面对rendertexture的使用也特别说明了一下,当不再使用这个rt之前,调用一次Discard()可以在某些移动设备上提高性能,即是这个原理,如果不discard,那么在unbind那一刻会触发此刻还存在的那个FrameData的处理。
PC显卡不需要这样做,因为pc上每次commandbuffer都是来了立即绘制,不存在framedata排队直说,所以在移动平台上一定牢记绘制不是立即的,是在特定时间触发对整个framedata的延迟渲染。
3.2在每帧渲染之前尽量clear
在一些渲染技巧里面可能每帧渲染前不clear当前的buffer,例如认为下一帧一定会把整个fb都写掉,就没必要先clear了。这是对于pc显卡来说的,对于tbr架构这就是个噩梦了。因为如果不clear,那么每个tile在初始化的时候都要从dram上的framebuffer把那一块的内容完整拷贝过来,而clear这个初始化就变得非常简单了。
3.3不要在一帧里面频繁的切换framebuffer
前面说到,tbdr的架构,gpu会尽可能的只在不得不绘制的时候才渲染framebuffer。假设这样一种情况,你先在fb上绘制a,然后使用fb,然后绘制b,再使用fb,再绘制c,再使用fb,这对于pc显卡问题不大,但是移动设备上每次使用fb都会触发一个所有tile的绘制,如果我们能尽量做到绘制a,b,c后再一起使用fb就好了。
同样的我们看到游戏中的全屏后处理被大量的使用,这在手机上性能不高,主要就是这些后处理可能在1帧内触发很多次不同的framebuffer之间的bind unbind,每一次bindunbind都需要对整个framebuffer的一次立即绘制。而tbr的绘制速度是不能和ir相比的,毕竟tile是要一块块从dram拷贝到sram进行渲染的。切换framebuffer在tbdr的架构是性能瓶颈。
3.4 关于early-z
因为tbdr有framedata队列,很多gpu会很聪明的尽量筛去不需要绘制的framedata。所以在tbdr上earlyz,或者stencil test这些是非常有益处的。例如你定义了一个stencil,gpu有可能在对framedata处理的过程中就筛掉了那些不能通过stencil的drawcall了。或者通过scissor test可能一整块tile都不需要绘制。
关于Early-z也一样,很多程序会通过预先渲染一遍简单的zpass来占住z,这样就可以在对framedata处理阶段就reject掉那些不能通过z的drawcall了。但是要注意的是powervr的gpu不需要eralyz,因为它内部的isr硬件会自动处理这批framedata最终绘制到屏幕的drawcall,甚至也不需要对不透明的物体做从前到后的绘制排序。至于大部分android设备,预先的一遍early-z pass可能就可以大大减少你的overdraw了,不过还是需要慎重,因为预先的一遍early-z pass又会增加cpu的提交负担,尽管很多android显卡对于zpass有特殊的优化。总之如果带宽瓶颈严重,那么early-z是有必要开的。但这里要明确的概念是,移动端的early-z发生在哪个阶段,不是在光栅化和ps之间,而是更早的对framedata的处理过程中。
3.5 blending和MSAA的效率其实很高,alpha-test效率很低
回头看下tbdr的渲染管线,对于一个tile上所有pixel的绘制都是在on-chip的mem上的,只在最后绘制好了才整体回拷给dram。所以我们通常认为会造成大量带宽的操作,例如blending(对framebuffer的读和写),msaa(增加对framebuffer读取的次数)其实在tbdr上反而是非常快速的。(当然msaa除了会造成framebuffer访问增多,还会带来渲染像素的数量增多,这个是tbr没什么优化的)
这时我们来细说一下另一种透明技术alpha-test这个东西,很多文献说到alpha-test这种技术在ios的显卡上效率较差,不如alpha-blending。道理是什么?从这个聪明的基于tbdr的gpu来看,如果他看到连续的不透明物体的绘制,因为写入的depth其实不用经过pixel shader已经是固定了,所以很多depth靠后的的在tile上有可能被去掉,但是alpha-test这个东西,他对depth的写入是不能预先确定的,它必须等到pixel shader执行,这导致了alpha-test之后的那些framedata失去了early –z的机会,也就增加了渲染量。而用alpha-blending则不会写入depth,所以对于这个聪明的gpu提前剔除z是不影响的,再加上blending的带宽消耗在tbr上又微乎其微。
blending更高效,alpha-test是性能瓶颈这些都是因为tbdr的gpu会对framedata做预先的优化处理带来的,这点是要牢记的。事实上powervr的gpu推荐的一个渲染顺序是opaque,再alpha-test,最后blending。这样alpha-test不会阻挡到更多的不透明物体的z预剔除。
3.6 延迟
很明显tbr的模式比ir存在延迟,例如想得到framebuffer上的一些结果,理论上是要存在一定的时间的,毕竟gpu会在最后一刻逼不得已的时候做渲染,这种延迟在一些使用的场景要记住。
3.7避免大量的drawcall和顶点量
传统的pc上看,drawcall以及顶点数量对gpu是没有太多严重的影响,但是放到tbr的移动设备上,结论就不是这样的,显然我们看到tbr渲染的时候再gs后会存储framedata队列,这个framedata数据会随着你的drawcall,你的顶点量而增大,顶点量占大头,甚至在一些情况增大到内存放不下的情况,而需要暂时移动到别处,这种情况对framedata的访问速度就奇慢无比了。
Tbr比ir多需要一份framedata的存储,这是比较重要的一个特性,因此手游上的drawcall和顶点量是要有限度的,因为它们不只是像pc那样影响cpu,还会严重影响到你的gpu。虽然没有找到这个framedata究竟在不同的设备上可以存放多大,但是测试来看百万的顶点量不管你的drawcall多少,shader多简单,在大部分机器都肯定会触发这个瓶颈了。
3.8避免gpu上的copy-on-write
因为tbdr的渲染是延迟的,想象这样一种情况,你当前帧内对一个mesh做个顶点动画,传递给gpu绘制,然后后面又改变了它的顶点动画,又提交给gpu,这样前面一个的vb还绑定在gpu上没有被处理,处于framedata队列状态,这一份同样的vb(改变过的)又要过来了,这时gpu会对这个vb做一个新的拷贝,以存储vb的多份不同的数据。显然这又增加了framedata的存储,会触发上面3.7的瓶颈。所以千万不要在同一帧内多次改变提交给gpu的资源,这会迅速把framedata撑大到装不下的状态。
其实总结了这些,我们发现tbdr完全是为了降低手机的带宽功耗而采取的一种分批次分区块绘制的折衷,并且在这个过程中利用framedata的list尽可能的挖掘延迟渲染的潜力,当然这一切都是硬件做的,硬件的优化水平有高有低,powervr就优化到了一种极致,arm的则相对弱一些,但是不管怎样,作为程序开发层的我们如果能够理解这个硬件上的变化,就可能更加顺应硬件的设计初衷,做出更高效的程序。同时tbdr的诞生就是为了对抗功耗,也在警醒我们在平时开发过程中,也应该把功耗视为手机上最大的性能陷阱,在功耗和表现之间做平衡。
参考资料:
1. Opengl Insights:performance Tuning for Tile-based_architectures
2. ARM. Mali GPUApplication Optimization Guide, 2011. Version 1.0.
3. Imagination Technologies Ltd. POWERVRSeries5 Graphics SGX Architecture Guide
for Developers, 2011. Version 1.0.8.
4. Qualcomm Incorporated. Adreno™200 Performance Optimization: OpenGL ES
Tips and Tricks, 2010
5. PowerVR PerformanceRecommendations The Golden Rules