论文盘点:ICCV 2019 Top 20,MobileNetV3居首!

ICCV 是计算机视觉领域三大顶会之一,往届都是奇数年开(与此对应ECCV 在偶数年开,CVPR 每年都开),ICCV 2019 于 2019年10月27日-11月2日召开,距今不足一年。
继盘点CVPR 2019 ,ECCV 2018 Top 20 论文后:
时隔一年,盘点CVPR 2019影响力最大的20篇论文
时隔两年,盘点ECCV 2018影响力最大的20篇论文
本文盘点 ICCV 2019 的Top 20 的论文,同之前一样,依然以谷歌学术上显示的论文的引用数为标准,截止时间为2020年8月6日。
1. MobileNetV3 是ICCV 2019 所有论文中引用量最高的,但仅有262次。第10 位 引用数139,第20位 90 。
2. 巧的是,截止今天前20的论文中多篇引用数相同,比如目标检测算法 FCOS 与 图像修复算法Gated Convolution 引用量都是218次,并列第二位,不同于CVPR 2019 和 ECCV 2018 引用量第一和第二差距很大,因时间不长,ICCV 2019 的引用量都不高。
3. 这些论文包含方向:神经架构搜索(2)、目标检测(3,FCOS、TridentNet、CenterNet)、图像修复、动作识别(2,SlowFast、TSM)、模型预训练的再思考、姿态迁移、深度估计、语义分割(CCNet)、人脸编辑检测数据集、图像压缩(使用GAN的方法)、数据增广(CutMix)、自监督学习(VideoBERT)、点云卷积(KPConv)、面部重演、新型卷积方法(Octave convolution)、实体AI模拟。
4. 由以上可以看出,这些论文的方向是相对比较分散的,即使研究的是较为小众的方向也有可能被很多论文参考。
5. 明星学者何恺明参与了其中三篇论文,分别为动作识别算法Slowfast、模型预训练的再思考和随机连接神经网络(RandWireNN)。
6. 工业界里Facebook参与的论文最多,有 6 篇,其次是谷歌 2篇,国内公司字节跳动、图森、华为、依图各参与 1 篇。
以下不仅列出了论文、代码和相应解读,还包括不少的Demo,欢迎参考~
NO.1 MobileNetV3
Searching for MobileNetV3
作者 | Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam
单位 | 谷歌AI;谷歌大脑
论文 | https://arxiv.org/abs/1905.02244
解读 | 重磅!MobileNetV3 来了!
代码 | https://github.com/tensorflow/models/tree/master/research/deeplab
引用次数 | 264
使用神经架构搜索得到的用于移动端的轻量级模型,已经成为众多计算机视觉任务的骨干网的选择。MobileNetV3 几乎已经进入所有计算机视觉主流开源库了。
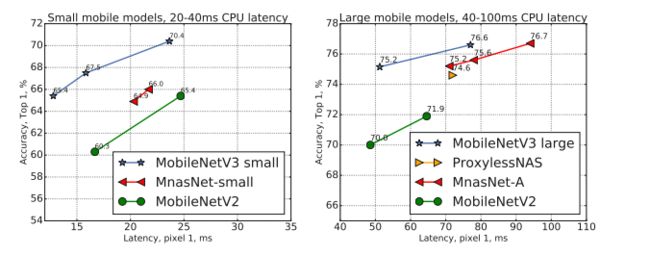
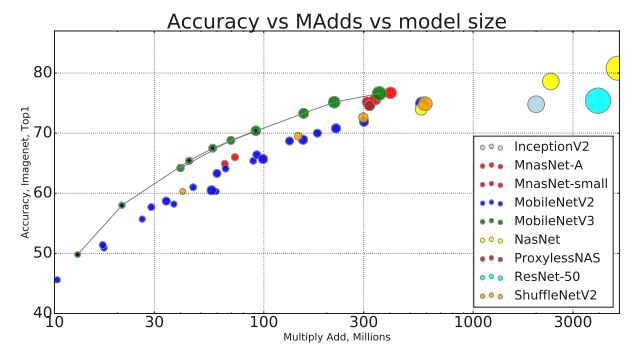
NO.2 FCOS
FCOS: Fully convolutional one-stage object detection
一阶全卷积目标检测
作者 | Zhi Tian, Chunhua Shen, Hao Chen, Tong He
单位 | 澳大利亚阿德莱德大学
论文 | https://arxiv.org/abs/1904.01355
代码 | https://github.com/tianzhi0549/FCOS/
解读 | https://zhuanlan.zhihu.com/p/63868458
引用次数 | 218
一种基于FCN的逐像素目标检测方法,anchor-free、proposal free ,并提出了中心度(Center—ness)的概念,精度超越大多数主流的anchor-base的算法。

NO.2(并列) 图像修复-Gated Convolution
Free-form image inpainting with gated convolution
作者 | Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, Thomas Huang
单位 | 伊利诺伊大学厄巴纳-香槟分校;Adobe Research;字节跳动人工智能实验室
论文 | https://arxiv.org/abs/1806.03589
解读 | https://zhuanlan.zhihu.com/p/82514925
代码 | https://github.com/JiahuiYu/generative_inpainting
主页 | http://jiahuiyu.com/deepfill/
备注 | ICCV 2019 Oral
引用次数 | 218
Gated Convolution,为所有层每一个维度的位置提供了一种可学习的,动态的特征选择机制,并提出了SN-Patch GAN来稳定GAN的训练学习。相比之前的方法,修复的结果质量更高,方法更灵活。

NO.4 Slowfast 视频识别/动作识别
Slowfast networks for video recognition
用于视频识别的Slowfast 网络
作者 | Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, Kaiming He
单位 | FAIR
论文 | https://arxiv.org/abs/1812.03982
Facebook开源算法代码库PySlowFast,轻松复现前沿视频理解模型
代码 | https://github.com/facebookresearch/
SlowFast
解读 | https://zhuanlan.zhihu.com/p/53199842
引用次数 | 211
该文提出了一种快慢结合的网络结构进行视频分类,Slow网络输入为低帧率,用来捕获空间语义信息,Fast网络,输入为高帧率,用来捕获运动信息。
SlowFast 已经有多个开源实现,成为视频分类领域的标杆模型。
NO.5 重新思考ImageNet预训练
Rethinking imagenet pre-training
作者 | Kaiming He, Ross Girshick, Piotr Dollár
单位 | FAIR
论文 | https://arxiv.org/abs/1811.08883
解读 | https://zhuanlan.zhihu.com/p/51507048
引用次数 | 210
何恺明大佬的论文,发现ImageNet预训练并不是必须的,在目标检测,语义分割等任务中从随机初始化开始训练也可以达到使用 ImageNet 预训练的效果,只不过迭代的轮数多一些而已。
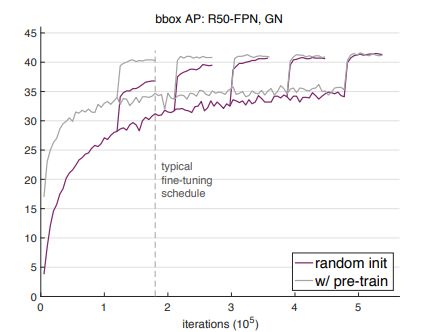
NO.6 神奇的舞姿迁移
Everybody dance now
作者 | Caroline Chan, Shiry Ginosar, Tinghui Zhou, Alexei A. Efros
单位 | UC伯克利
论文 | https://arxiv.org/abs/1808.07371
解读 | https://zhuanlan.zhihu.com/p/67942949
代码 | https://carolineec.github.io/
everybody_dance_now/#code
主页 | https://carolineec.github.io/
everybody_dance_now/
引用次数 | 204
将一段视频中的舞姿迁移给另一个视频中的人。效果惊艳!
NO.7 MonoDepth2 深度估计
Digging into self-supervised monocular depth estimation
自监督的单目深度估计
作者 | Clément Godard, Oisin Mac Aodha, Michael Firman, Gabriel Brostow
单位 | 伦敦大学学院;加州理工学院;Niantic Labs
论文 | https://arxiv.org/abs/1806.01260
解读 | https://zhuanlan.zhihu.com/p/70651836
代码 | https://github.com/nianticlabs/
monodepth2
引用次数 | 187
NO.8 语义分割 CCNet
CCNet: Criss-cross attention for semantic segmentation
作者 | Zilong Huang, Xinggang Wang, Yunchao Wei, Lichao Huang, Humphrey Shi, Wenyu Liu, Thomas S. Huang
单位 | 华中科技大学
论文 | https://arxiv.org/abs/1811.11721
解读 | https://zhuanlan.zhihu.com/p/51393573
代码 | https://github.com/speedinghzl/CCNet
引用次数 | 152
对 Non-local 模型的改进,和 Non-local 相比,仅需要1/11的内存消耗,15%的计算开销!精度超越DeepLabv3+!

NO.9 目标检测-TridentNet
Scale-aware trident networks for object detection
作者 | Yanghao Li, Yuntao Chen, Naiyan Wang, Zhaoxiang Zhang
单位 | 国科大;TuSimple;中国科学院自动化研究所;中科院
论文 | https://arxiv.org/abs/1901.01892
代码 | https://github.com/TuSimple/simpledet/
tree/master/models/tridentnet
解读 | https://zhuanlan.zhihu.com/p/54334986
引用次数 | 147
解决目标检测中最为棘手尺度变化问题,在标准的COCO 数据集上,使用ResNet101单模型可以得到MAP 48.4的结果,远远超越了当时公开的单模型最优结果。

NO.10 FaceForensics++ 人脸编辑检测
Faceforensics++: Learning to detect manipulated facial images
学习检测被篡改了的面部图像
作者 | Andreas Rössler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, Matthias Nießner
单位 | 慕尼黑工业大学;那不勒斯菲里德里克第二大学;埃尔朗根-纽伦堡大学
论文 | https://arxiv.org/abs/1901.08971
代码 | https://github.com/ondyari/FaceForensics
引用次数 | 139
随着技术的进步,越来越多的假视频出现,为研究识别这些合成的假视频,慕尼黑工业大学等通过人脸重演和换脸推出大型数据集 Faceforensics++。

NO.11 用于图像压缩的GAN
Generative adversarial networks for extreme learned image compression
作者 | Eirikur Agustsson, Michael Tschannen, Fabian Mentzer, Radu Timofte, Luc Van Gool
单位 | 苏黎世联邦理工学院
论文 | https://arxiv.org/abs/1804.02958
代码 | https://github.com/Justin-Tan/generative-compression (非官方)
引用次数 | 138
神经网络图像视频压缩越来越引起学术界的兴趣,本文用GAN做图像压缩,体积小清晰度却很高。

NO.12 目标检测-CenterNet
CenterNet: Keypoint triplets for object detection
用于目标检测的关键点三联体
作者 | Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, Qi Tian
单位 | 国科大;牛津大学;华为诺亚方舟实验室
论文 | https://arxiv.org/abs/1904.08189
代码 | https://github.com/Duankaiwen/
CenterNet
引用次数 | 137
不同于 Objects as Points 论文的 CenterNet,该CenterNet是在ECCV 2018 CornerNet基础上增加预测中心点,以此决定目标检测的包围框。

NO.13 TSM:视频理解/动作识别
TSM: Temporal shift module for efficient video understanding
高效视频理解的时空转换模块
作者 | Ji Lin, Chuang Gan, Song Han
单位 | 麻省理工学院;MIT-IBM Watson AI Lab
论文 | https://arxiv.org/abs/1811.08383
代码 | https://github.com/mit-han-lab/temporal-shift-module
引用次数 | 111
该方法是能够插入2D CNNs的网络中实现时序上的学习而不增加额外的性能上的花费。TSM是一个高效且识别率非常好的模型,相对于传统的一些算法其速度有数倍的提升,在视频理解问题中验证了其有效性。
NO.13(并列) CutMix 数据增广
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
作者 | Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo
单位 | Naver公司;LINE Plus;延世大学
论文 | https://arxiv.org/abs/1905.04899
代码 | https://github.com/clovaai/CutMix-PyTorch
备注 | ICCV 2019 oral
引用次数 | 111
一种新的数据增广方法,随机Cut一块区域,填充训练集中其他图像块,取得了更好的效果。该方法被用于YOLOv4的训练。

NO.15 Randomly wired neural networks 神经架构搜索
Exploring randomly wired neural networks for image recognition
探索随机布线神经网络在图像识别中的应用
作者 | Saining Xie, Alexander Kirillov, Ross Girshick, Kaiming He
单位 | FAIR
论文 | https://arxiv.org/abs/1904.01569
代码 | https://github.com/seungwonpark/
RandWireNN
引用次数 | 107
该文运用经典随机图理论,创造性的去生成随机连线的图,但实验表明这些随机生成连接的图的网络在ImageNet数据集上的accuracy超越的经典的手工设计的方法。
文章认为探究如何设计出更好的网络生成器可能能带来更好的突破。

NO.16 VideoBERT 联合视频与语言的表示学习
VideoBERT: A joint model for video and language representation learning
作者 | Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, Cordelia Schmid
单位 | 谷歌
论文 | https://arxiv.org/abs/1904.01766
引用次数 | 101
为了利用 YouTube 等平台上的大规模无标签数据,自监督学习如今变得越来越重要。这篇论文中作者们提出了一个视觉和语义的联合模型,在没有额外显式监督的条件下学习高阶特征。在动作分类和视频描述测试了这一模型。表明该模型可直接用于开放词汇库的分类任务,超过了最优秀的视频描述模型。


NO.17 KPConv 点云卷积
KPConv: Flexible and deformable convolution for point clouds
作者 | Hugues Thomas, Charles R. Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, François Goulette, Leonidas J. Guibas
单位 | 国立巴黎高等矿业学院;FAIR;斯坦福大学
论文 | https://arxiv.org/abs/1904.08889
解读 | https://zhuanlan.zhihu.com/p/92244933
代码 | https://github.com/HuguesTHOMAS/
KPConv
解读 | https://blog.csdn.net/Dujing2019/article/
details/104178936
引用次数 | 99
点云特征提取的核心点卷积(Kernel Point Convolution)。
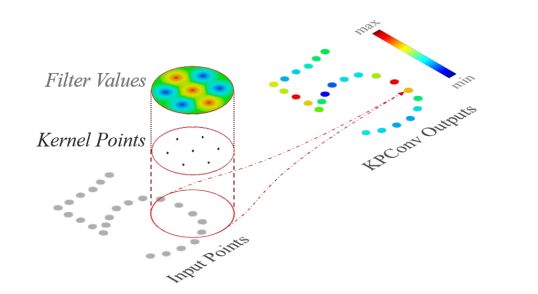
NO.18 面部重演
Few-shot adversarial learning of realistic neural talking head models
作者 | Egor Zakharov, Aliaksandra Shysheya, Egor Burkov, Victor Lempitsky
单位 | 莫斯科三星人工智能中心;Skolkovo 科学技术研究院
论文 | https://arxiv.org/abs/1905.08233
解读 | https://zhuanlan.zhihu.com/p/149289436
代码 | https://github.com/vincent-thevenin/Realistic-Neural-Talking-Head-Models
共享文件 | https://drive.google.com/drive/
folders/1PeGG6zO3ZjrHk2GAXItB8khwMhPPyDHe
引用次数 | 91
该文小样本的面部重演,即实现表情变换而身份不变。

NO.19 新型卷积 Octave convolution
Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution
作者 | Yunpeng Chen, Haoqi Fan, Bing Xu, Zhicheng Yan, Yannis Kalantidis, Marcus Rohrbach, Shuicheng Yan, Jiashi Feng
单位 | Facebook AI;新加坡国立大学;依图科技
论文 | https://arxiv.org/abs/1904.05049
解读 | https://zhuanlan.zhihu.com/p/62711929
代码 | https://github.com/facebookresearch/
OctConv
引用次数 | 90
为更好的提取图像频域信息,提出了 Octave convolution 新型卷积,在图像分类,行为识别等任务上,可在降低计算量的同时达到更好的效果。

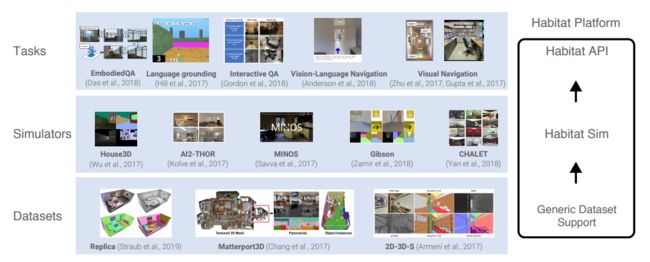
NO.19(并列) Habitat 实体AI模拟平台
Habitat: A platform for embodied ai research
实体AI研究平台
作者 | Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, Dhruv Batra
单位 | FAIR;FRL;佐治亚理工学院;西蒙弗雷泽大学;英特尔;UC伯克利
论文 | https://arxiv.org/abs/1904.01201
解读 | https://zhuanlan.zhihu.com/p/69310354
主页 | https://aihabitat.org/
引用次数 | 90
为了加速机器人等实体AI的开发,Facebook开源其AI模拟平台AI Habitat,为实体AI研究提供通用的人类模拟训练,同时还有3D模型数据集Replica,包括生成的一系列公寓、零售店等室内场景的3D模型。

备注如:CV

计算机视觉交流群
交流学习最新CV技术前沿,扫码备注拉入群。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 