内核字符串与链表
字符串与链表Review
1.字符串操作:
char *str = { “my first string” }; //ANSI字符串
wchar_t *wstr = { L“my first string” };//Unicode字符串
区别:
ANSI( char)是用一个字节来表示的,最多256个符号。
Unicode( w_char )是用两个字节来表示的,能代表更多的字符。
字符串在内核中的定义:
UNICODE:( 宽字符串 )
Typedef struct _UNICODE_STRING{
USHORT Length;
USHORT MaximumLength;
PWSTR Buffer;
} UNICODE_STRING, *PUNICODE_STRING;
注:并不保证Buffer指向的字符串是以空结束的。(例取空UNICODE_STRING的Buffer会使内核崩溃)
最好使用微软提供的Rtl系列函数来操作字符串。
ANSI:( 窄字符串 )
Typedef struct _STRING{
USHORT Length;
USHORT MaximumLength;
PSTR Buffer;
} ANSI_STRING , *PANSI_STRING;
字符串在内核中的初始化:
以下代码会导致蓝屏:
UNICODE_STRING str = { 0 };//清空UNICODE_STRING,意味着Buffer也为0 ;
//会导致空指针异常,str.Buffer为0。缓冲区大小为零啊。
//为避免空指针异常,应该为str. Buffer指定一个固定大小的缓冲区,如:
WCHAR strBuf[ 128 ] = { 0 };
str. Buffer=strBuf;
wcscpy(str. Buffer , L”my first string !”);
str. Length = str. MaximumLength = wcslen( L”my first string!” ) *sizeof( WCHAR );
更方便的,WDK提供了一个API来帮助开发者简单的初始化一个UNICODE_STRING:
VOID RtlInitUnicodeString(
IN OUT PUNICODE_STRING DestinationString;//需要初始化的字符串变量
IN PCWSTR SourceString; //字符串
);
如:
UNICODE_STRING str = { 0 };
RtlInitUnicodeString( &str, L”my first string!” );
字符串的拷贝:
字符串不再是以空结束的,所以不能使用wcscpy()来拷贝。
注:拷贝目标字符串的Buffer指向的缓冲区必须有足够的空间,倘若Buffer空间不够,那么字符串会拷贝不完全。(也就是说拷贝的目标STRING都必须有足够 大小的已初始化Buffer)
UNICODE_STRING src = RTL_CONSTANT_STRING( L”My source string!” );
//dst的copy前操作:
UNICODE_STRING dst ;
WCHAR dst_buf [256];
RtlInitEmtyUnicodeString( &dst ,dst_buf , 256*sizeof(WCHAR) );
//copy操作:
RtlCopyUnicodeString( &dst ,&src );
字符串的连接:
1.source Append to UNICODE_STRING
NTSTATUS RtlAppendUnicodeToString(
IN OUT PUNICODE_STRING Destination,//Pointer to the buffered string.
IN PCWSTR Source
);
2.UNICODE Append to UNICODE_STRING
NTSTATUS RtlAppendUnicodeStringToString(
IN OUT PUNICODE_STRING Destination,//Pointer to a buffered Unicode string.
IN PUNICODE_STRING Source//Pointer to the buffered string to be concatenated
);
字符串的打印:
在WDK中用RtlStringCbPrintW()替代C语言中的打印函数(sprintf,swprintf,_snprintf..).
//在ntstrsafe.h中
NTSTATUS RtlStringCbPrintfW(
OUT LPWSTR pszDest,//Supplies a pointer to a caller-supplied buffer(字符串)
IN size_t cbDest, //Supplies the size of the destination buffer, in bytes
IN LPCWSTR pszFormat,//Supplies a pointer to a null-terminated text string
....
....
);
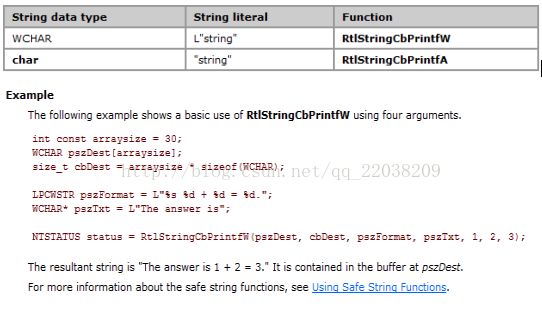
其在目标缓冲区内存不足时仍然可以打印,但多余部分会被截去。
2.内存与链表:
在驱动中最常调用的是ExAllocatePoolWithTag();
如:dst .Buffer = (PWCHAR)ExAllocatePoolWithTag( NonPagedPool ,
Src .Length,
MEM_TAG,
);
PVOID ExAllocatePoolWithTag(
IN POOL_TYPE PoolType,//Specifies the type of pool memory to allocate.
IN SIZE_T NumberOfBytes,//Specifies the number of bytes to allocate.
IN ULONG Tag //Specifies the pool tag for the allocated memory.
);
第一个参数表明分配的内存是锁定内存,永远存在于真实物理内存上,不会被分页交换到硬盘。
第二个参数是要分配的长度。
第三个参数是一个内存分配标识。(TAG)
Windows NT把内核模式地址空间分成分页内存池和非分页内存池。(用户模式地址空间总是分页的)必须驻留的代码和数据放在非分页池;不必常驻的代码和数据放在分页池中。Windows NT为决定代码和数据是否需要驻留非分页池提供了一个简单规则。
非分页内容的空间是很小的,所以一般的东西都会放入分页内存中。
执行在高于或等于DISPATCH_LEVEL级上的代码必须存在于非分页内存中。
Windows规定有些虚拟内存可以交换到文件中,这类内存被称为分页内存。
有些虚拟内存永远不会交换到文件中,这些内存叫非分页内存。
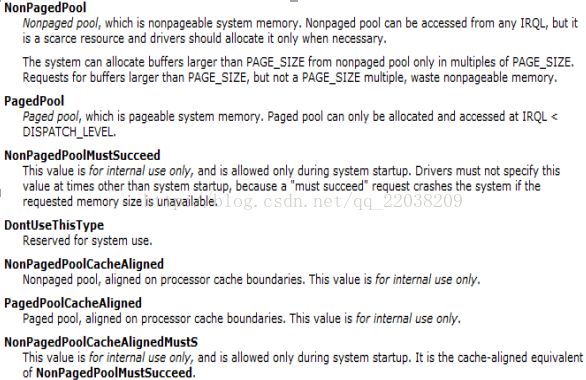
其中,主要的两个区别就是分页内存和非分页内存。
分页内存是低中断级别的例程可以访问的。
而非分页内存则是各个中断级别的例程都可以使用的。
区别在于:
分页内存是虚拟内存,在物理上未必总是能得到。
操作系统实现虚拟内存的主要方法就是通过分页机制。在Win32中,物理地址空间,二维虚拟地址空间和实际内存地址是三个不同的概念。操作系统通过段选择构成二维虚拟地址空间,每个进程有一个4G的地址空间,然后操作系统的内存管理器件把每个进程映射到一维物理地址空间的不同部分,但是因为我们实际机器 上大都没有4G内存,所以,实际内存空间是物理地址空间的子集。
分页管理器把地址空间划分成4K大小的页面(非Intel X86体系与之不同),当进程访问某个页面时,操作系统首先在Cache中查找页面,如果该页面不在内存中,则产生一个缺页中断(Page Fault),进程就会被阻塞,直至要访问的页面从外存调入内存中。
我们知道,在处理低优先级的中断时,仍可以发生高优先级的中断。既然缺页过程也是一个中断过程,那么就产生一个问题,即,缺页中断和其他中断的优先级的问题。如果在高于缺页中断的中断优先级上再发生缺页中断,内核就会崩溃。所以在DISPATCH_LEVEL级别以上,绝对不能使用分页内存,一旦使用分页内存,就有发生缺页中断的可能,前面说过,这样会导致内核崩溃。
利用ExFreePool();释放申请的内存池内存
使用LIST_ENTRY:
一个双向链表结构,总是在使用中插入到已经存在的数据结构中。
为了让一个struct成为一个节点,则可以将LIST_ENTRY放入struct结构内。
Typedef struct {
LIST_ENTRY list_entry;
PFILE_OBJECT file_object;
UNICODE_STRING file_name;
LARGE_INTEGER file_length;
} MY_FILE_INFOR, * PWY_FILE_INFOR;
若LIST_ENTRY作为链表的头,那么在使用之前,必须在调用前用InitializeListHead初始化。
将LIST_ENTRY插入到MY_FILE_INFOR结构头部,这样看来,整个MY_FILE_INFOR看起来就像是一个LIST_ENTRY。
但是,并非所有情况都可以那样。如:MS的许多结构喜欢一开头就是结构的长度,因此在通过LIST_ENTRY结构的地址获取所在节点的地址时,有个地址偏移计算的过程。
For(p = my_list_head.Flink; p != &my_list_head.Flink; p = p->Flink){
PMY_FILE_INOR elem =
CONTATINING_RECORD(p, MY_FILE_INFOR, list_entry);
//....
}
CONTAINING_RECORD是WDK中已经定义的一个宏,作用是通过一个LIST_ENTRY结构的指针,找到这个结构所在节点的指针。定义如下:
#define CONTAINING_RECORD(address, type, field)
( (type *) ( \
(PCHAR)(address) - \
(ULONG_PTR)(&( (type *)0 )->field) ) \
)
注:
当自定义数据结构的第一个字段是LIST_ENTRY时,RemoveHeadList返回的指针可以当做用户自定义的指针。如:
PLIST_ENTRY pEntry = RemoveHeadList(&head);
PMYDATASTRUCT pMyData = (PMYDATASTRUCT) pEntry;
当自定义数据结构的第一个字段不是LIST_ENTRY时,RemoveHeadList返回的指针不可以当做用户自定义的指针。
此时需要通过自定义数据结构初始化的变量地址逆向算出自定义数据的指针。一般通过其变量在自定义数据中的偏移量,用变量减去这个偏移量,就会得到用户自定义结构的指针的地址。
PLIST_ENTRY pEntry = RemoveHeadList(&head);
PIRP pIrp = CONTAINING_RECORD(pEntry,
MYDATASTRUCT,
ListEntry
);
在WDK中,DDK提供了宏CONTAINING_RECORD:
第一个参数指的是RemoveHeadList返回的PLIST_ENTRY结构;
第二个参数是数据结构的名字;
第三个参数是数据结构中的字段。
(见《windows内核驱动详解》第五章windows内存管理P129)
自旋锁:
解决基本多线程问题,就使用锁。
注:
一般为全局变量,
http://blog.sina.com.cn/s/blog_612ae57d0100fsey.html
http://blog.csdn.net/chenyujing1234/article/details/7764288
如下:
KSPIN_LOCK my_spin_lock;
KeInitializeSpinLock( &my_spin_lock );//初始化一个自旋锁
KIRQL irql;//中断请求级别
//interrupt request level (IRQL)
The hardware priority level at which a given kernel-mode routineruns, masking off interrupts with an equivalent or lower IRQL onthe processor. A routine can be preempted by an interrupt with ahigher IRQL.
//提高中断级别
KeAcquireSpinLock( &my_spin_lock, &irql );
//.......to do some thing
KeReleaseSpinLock( &my_spin_lock, irql );
在双向链表中使用自旋锁:
LIST_ENTRY my_list_head;
KSPIN_LOCK my_list_lock;
Void List_Initialize()//链表初始化函数
{
InitializeListHead( &my_list_head );
KeInitializeSpinLock( &my_list_lock );
}
//链表一旦完成初始化,之后就可以用一系列加锁的操作来代替普通操作。比如,插入一个节点。
普通操作:InsertHeadList( &my_list_head, (PLIST_ENTRY)&my_file_infor );
加锁操作:
(插入操作)
ExInterLockedInsertHeadList(
&my_list_head,
(PLIST_ENTRY)& my_file_infor,
&my_list_lock
);
(移除操作)从链表中移除第一个节点并返回
My_file_infor = ExInterLockedRemovedHeadList(
&my_list_head,
&my_list_lock
);
使用队列自旋锁提高性能:
初始化自旋锁也是KeInitializeSpinLock.
KLOCK_QUEUE_HANDLE数据结构唯一的表示一个队列自旋锁
获取锁:VOID KeAcquireInStackQueuedSpinLock(
IN PKSPIN_LOCK SpinLock,
IN PKLOCK_QUEUE_HANDLE LockHandle);
释放锁:VOID KeReleaseInStackQueueSpinLock(
IN PKLOCE_QUEUE_HANDLE LockHandle
);