项目总结之机器翻译(使用tensor2tensor框架,transformer算法实现)--实战篇(机器翻译,序列生成)
下面会分这几部分来介绍
1 tensor2tensor的介绍
2 使用tensor2tensor训练翻译模型的具体操作
3 模型部署
4 目前使用的一些数据预处理,清洗的方法
T2T使用了TensorFlow进行的有监督学习和为序列任务提供支持。它由谷歌大脑团队得工程师和研究员进行维护和使用。该系统最初是希望完全使用Attention方法来建模序列到序列(Sequence-to-Sequence,Seq2Seq)的问题,对应于《Attention Is All You Need》这篇论文。该项工作有一个有意思的名字叫“Transformer”。随着系统的不断扩展,T2T支持的功能变得越来越多,目前可以建模的问题包括:图像分类,语言模型、情感分析、语音识别、文本摘要,机器翻译。T2T在很多任务上的表现很好,并且模型收敛比较快,在TF平台上的工程化代码实现的也非常好。
系统对数据处理、模型、超参、计算设备都进行了较高的封装,在使用的时候只需要给到数据路径、指定要使用的模型和超参、说明计算设备就可以将系统运行起来了。
目录:
安装方法
文件目录
运行前,需要准备的代码
运行训练方法
模型部署与预测predict代码
解码预测方法
安装方法:
本人使用的版本如下:
# Assumes tensorflow or tensorflow-gpu installed,需要先安装好
pip install tensor2tensor==1.13.2
pip install tensorflow==1.12.0
备注:下面的文件或者例子均由英语翻译成德语来进行说明
系统的运行分三个阶段:数据处理,训练,解码。
对应着三个入口:t2t-datagen,t2t-trainer,t2t-decoder。运行完这三个命令就可以得到自己的模型了。
下面的安装方法摘抄来自其他博客,有对安装的版本有要求
首先在开始正式的操作之前还是要先安装一些包和创建一些文件夹。首先要安装的就是tensorflow和tensor2tensor包,由于tensorflow和tensor2tensor的兼容性不是特别好,有一些版本之间是不兼容的。最新的tensorflow2.0版本就和tensor2tensor不怎么兼容。跑这个模型的话建议使用GPU版的tensorflow,会比CPU版的tensorflow训练模型快很多,首先是CPU版的安装,推荐tf1.5和t2t1.6,这两个亲测是可以兼容的:
pip install tensorflow==1.5
pip install tensor2tensor==1.6
然后如果是GPU版的tensorflow的话还要注意tf和cuda的版本匹配,我之前安装的是tensorflow-gpu==1.13.1和CUDA 10.0
文件目录:
在生成训练数据之前,我们还需要修改一些文件
首先我们整体的文件目录如下:
|machine_translate/ # 最外层的文件夹名
|--en_de.en # 用于生成训练数据(序列数据)的英语句子文件
|--en_de.de # 用于生成训练数据(序列数据)的德语句子文件
|--train_model/ # 第二层文件夹,用来放置训练相关数据
|----__init__.py # 用来导入自定义的problem,后文会介绍
|----en_de.py # 使用上面的en_de.en, en_de.de文件来生成训练数据的代码
|----data/ ##使用t2t-datagen命名生成的序列化数据存储的位置(实际位置也可以修改,在上面的en_de.py文件里修改)
|----output/ ## 训练完成后的checkpoint模型保存的位置,存储路径可修改,方法同上。
|--export.py # 用于导出模型,导出的路径可以在运行命令的时候进行指定,本人是放在output目录下的
|----output/export/ # 用于放置最后打包好的pb文件
最后导出的pb文件目录结构如下:
|export/ # 到处模型的路径
|--1/ # 模型版本(一般可取1,2,3...方便后面部署模型,默认的名字是一串数值)
|----saved_model.pb
|----variables/
|------variables.data-000000-of-00001
|------variables.index
运行前,需要准备的代码
1 需要生成每行一句话的英语文件en2de.en和德语文件en2de.de,后面会使用着两个文件用t2t=datagen生成序列化数据用于训练
具体的生成方法如下:
# 输入数据en_de数组,[[en1,de1],[en2,de2].....],输出en_de.en和en_de.de文件
def write_gfile():
import tensorflow as tf
with tf.gfile.GFile("en_de.en", mode="w") as en:
for item_en in en_de:
re_n = re.compile(r'\n')
a = re_n.sub(" ", item_en[0].strip())
re_out = re.compile(r"\s{2,}")
a = re_out.sub(" ", a)
en.write(a)
en.write("\n")
with tf.gfile.GFile("en_de.de", mode="w") as de:
for item_de in en_de:
re_n = re.compile(r'\n')
a = re_n.sub(" ", item_de[1].strip())
re_out = re.compile(r"\s{2,}")
a = re_out.sub(" ", a)
de.write(a)
de.write("\n")
with tf.gfile.GFile("en_de.en") as en_:
en = en_.readlines()
with tf.gfile.GFile("en_de.de") as de_:
de = de_.readlines()
print("finish gfile")
print(len(de))
print(len(en))
2 init.py 代码如下(一行代码即可),该代码与en_de.py文件一起用于自定义自己的problem问题类
from . import en_de
3 en_de.py代码如下
注意:这个文件对于不同的翻译数据要修改的地方有,1是类的名字EnDe,要与当前py文件en_de.py名字对应(都首字母大写,去掉下划线),这个是命名规范,用于自己定义的任务的注册。2是输入数据的路径修改(en_de两个平行语料的路径)
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import tarfile
from tensor2tensor.data_generators import generator_utils
from tensor2tensor.data_generators import problem
from tensor2tensor.data_generators import text_encoder
from tensor2tensor.data_generators import text_problems
from tensor2tensor.data_generators import translate
from tensor2tensor.data_generators import tokenizer
from tensor2tensor.utils import registry
import tensorflow as tf
import os
DATA_DIR = os.path.expanduser("./data")
OUTPUT_DIR = os.path.expanduser("./output")
TMP_DIR = os.path.expanduser("./tmp")
tf.gfile.MakeDirs(DATA_DIR)
tf.gfile.MakeDirs(OUTPUT_DIR)
tf.gfile.MakeDirs(TMP_DIR)
#t2t-datagen --t2t_usr_dir=train_model --problem=zaful_sp --data_dir=./train_model/data
#t2t-trainer --t2t_usr_dir=train_model --problem=zaful_sp --data_dir=./train_model/data --model=transformer --hparams_set=transformer_base_single_gpu --output_dir=./train_model/output --worker_gpu_memory_fraction=1 --hparams='batch_size=4096' --worker_gpu=1
#python export.py --model=transformer --hparams_set=transformer_base_single_gpu --problem=en_po --t2t_usr_dir=train_model --data_dir=./train_model/data --output_dir=./train_model/output
from tensor2tensor.data_generators import problem
from tensor2tensor.data_generators import text_problems
from tensor2tensor.utils import registry
@registry.register_problem
class EnDe(text_problems.Text2TextProblem):
"""Sort words on length in randomly generated text."""
@property
def is_generate_per_split(self):
return False
def generate_samples(self, data_dir, tmp_dir, dataset_split):
del tmp_dir
del data_dir
del dataset_split
with tf.gfile.GFile("en_de.de") as target_file:
target_data = target_file.readlines()
with tf.gfile.GFile("en_de.en") as source_file:
source_data = source_file.readlines()
for target,source in zip(target_data,source_data):
sentence_input = source
sentence_target = target
yield {
"inputs" : sentence_input,
"targets" : sentence_target,
}
@property
def vocab_type(self):
return text_problems.VocabType.SUBWORD
@property
def approx_vocab_size(self):
return 2**15 # ~8k
@property
def dataset_splits(self):
return [{
"split": problem.DatasetSplit.TRAIN,
"shards": 200,
}, {
"split": problem.DatasetSplit.EVAL,
"shards": 1,
}
# {
# "split": problem.DatasetSplit.TEST,
# "shards": 1,
# }
]
3 export.py代码较长,就不在这里列出来了,贴一个Git上的代码链接
https://gitlab.com/huangrs/translate_train/-/tree/master/en_span
运行训练方法
1 Datasets训练数据集
使用t2t-datagen方法生成序列数据
需要使用我们上一小章生成的en_de.en和en_de.de文件
具体生成数据的命令如下:
t2t-datagen --t2t_usr_dir=train_model --problem=en_de --data_dir=./train_model/data
参数解释:data_dir生成的序列化数据的保存位置, problem主要用于加载源数据,该数据的位置在problem中指定的en_de中配置
对上面数据生成做一个整体的解释(想了解有关problem有关信息的可以参考下面的解释,否则直接跳过下面这一大段也可以):
数据集通过tensorflow.Example的协议缓冲在TFRecord文件中进行标准化。所有的数据集通过data generator进行注册和生成,许多常用的序列数据集都已经可以用生成和使用。
Tensor2Tensor的使用是比较方便的,对于系统中可以支持的问题,直接给系统设置好下面的信息就可以运行了:数据,问题(problem),模型,超参集合,运行设备。这里的实现其实是采用了设计模型中的工厂模式,即给定一个问题名字,返回给相应的处理类;给定一个超参名,返回一套超参的对象。实现这种方式的一个重点文件是utils/registry.py。在系统启动的时候,所有的问题和超参都会在registry中注册,保存到_MODELS,_HPAPAMS,_RANGED_HPARAMS中等待调用。
数据处理的过程包括:
(1).(下载)读取训练和开发数据。如果需要使用自己的数据的话,可以在问题中指定。
(2).(读取)构造词汇表。可以使用自己预先构造好的词汇表。系统也提供构建BPE词汇表的方法。注意,这里有个实现细节是系统在抽取BPE词汇表的时候,有个参数,默认并非使用全量的数据。通过多次迭代尝试,得到最接近预设词汇表规模的一个词汇表。在大数据量的时候,这个迭代过程会非常慢。
(3). 使用词汇表将单词映射成id,每个句子后会加EOS_ID,每个平行句对被构造成一个dict对象({‘inputs’:value,‘targets’:value}),将所有对象序列化,写入到文件中,供后面训练和评价使用。
2 训练模型
使用上一步生成的序列化数据进行训练
命令如下:
t2t-trainer --t2t_usr_dir=train_model --problem=en_de --data_dir=./train_model/data --model=transformer --hparams_set=transformer_base_single_gpu --output_dir=./train_model/output --worker_gpu_memory_fraction=1 --hparams='batch_size=4096' --worker_gpu=1
现在我来解释一下每个参数的含义:
①–t2t_usr_dir:这个参数只要是你使用自己的数据,对应的是你定义自己problem的文件夹(即en_de.py的文件夹)
②–data_dir:就是之前上一步生成的序列化数据的文件夹
③–problem:就是之前定义的问题的名字
④–model:这里是指你要是用什么模型去训练,我这里使用的transformer,还有lstm_attention等等等等很多其他模型,具体请参考tensor2tensor的官方文档
⑤–hparams_set:这里的transformer_small是指使用大中小里面哪种模型,不同的模型尺寸适合于不同规模的数据,一般的话transformer_small就够用了,模型越大训练的资源和时间开销也越大,当然如果你的机器足够nb那就随意好了,这里我们使用的是transformer_base_single_gpu
⑥–hparams:训练时候的一些参数,可以调一调batch_size,效果上基本是越大越好,当然训练起来也是越大越慢
⑦–schedule:意思应该是训练的模式,这里选择的是边训练边evaluate,也就是训练1000步保存一个模型的时候evaluate一下看看效果(这里我们没有设置,使用默认参数)
⑧–output_dir:也就是保存模型的文件夹了
3 模型打包
命令如下:
python export.py --model=transformer --hparams_set=transformer_base_single_gpu --problem=en_de --t2t_usr_dir=train_model --data_dir=./train_model/data --output_dir=./train_model/output
参数含义和训练时候的类似,这里就不解释了,打包好的模型位置在output目录下的export文件夹中
模型部署
命令如下:
NV_GPU=0 nvidia-docker run --name en_de_translate -p 8007:8007 --mount type=bind,source=$(pwd)/translate_model,target=/translate_model -t --entrypoint=tensorflow_model_server tensorflow/serving:latest-gpu --port=8007 --enable_batching=true --file_system_poll_wait_seconds=300 --grpc_channel_arguments=“grpc.max_connection_age_ms=5000” --model_config_file=/translate_model/tfserv.conf --per_process_gpu_memory_fraction=0.9&
需要把前面打包好的模型放在translate_model中,具体目录如下:
#serving manages models目录结构:
|translate_model/
|--en_de_model/
|----1/
|------variables/
|--------variables.data-000000-of-00001
|--------variables.index
|------saved_model.pb
|--tfserv.conf
tfserv.conf文件格式如下:
model_config_list: {
config: {
name: "en_de",
base_path: "/translate_model/en_de_model",
model_platform: "tensorflow",
model_version_policy: {
latest: {
num_versions: 1
}
}
},
config: {
name: "en_es",
base_path: "/_translate_model/en_es",
model_platform: "tensorflow",
model_version_policy: {
latest: {
num_versions: 1
}
}
}
}
解码预测方法
由于代码文件较多,贴一下代码链接https://gitlab.com/huangrs/translate_train/-/tree/master/translate_web
文件目录如下:
|--translate_web/
|--problem/ #
|----en_de/
|------__init__.py # 与之前的problem文件内容一下
|------en_de.py # 与之前的problem文件内容一下
|----en_es/
|------__init__.py
|------en_span.py
|--vocab/ # vocab字典
|----vocab.en_de.32768.subwords
|----vocab.en_es.32768.subwords
|--serving_utils.py # grpc和预测的主要代码
|--web.py # web文件,使用tornado
|--en_de_translator.py # 输入时的一些预处理数据代码
|--de_def.py # 输入时的一些预处理数据代码
如果看到这,恭喜你,完成了模型的训练,部署,接下来就可以通过HTTP请求翻译数据了。
下面为其他的一些扩展知识:
详细信息参考:https://cloud.tencent.com/developer/article/1153079

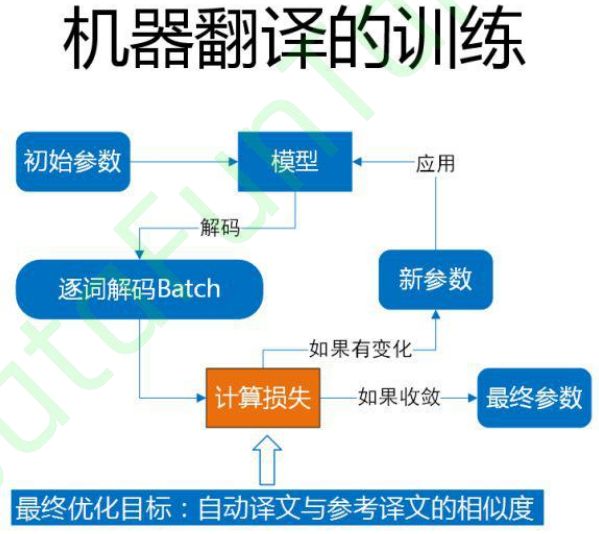
一般而言在翻译领域,如何去评价一个自动译文好不好呢,我们的评价指标叫 blue,它是和参考译文去比对,一元的串匹配的有多少,二元的串匹配的有多少,三元四元有多少。但是在神经网络翻译训练当中,我们是没有办法用 blue 这种方式的,这时候就用 PPL,用的比较广泛,虽然在统计规律中讲 PPL 越低,blue 值会增的,但是好多时候,在一些比较狭小的空间,它会有个反馈,所以这个时候会有个模型选择。(摘自DataFunTalk)(PPL:perplexity困惑度)