pandas数据分析案例--2012美国总统竞选赞助数据分析
美国总统竞选赞助数据分析
本文内容参考阿里云天池实验室,在原有基础上添加了一些结论的分析。
原案例地址
数据来源
1、首先导入相关的python数据分析的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
2、数据的载入和预览
2.1 数据载入
由于文件较大,数据被分为三个文件,分别导入。
data_01 = pd.read_csv('./data_01.csv')
data_02 = pd.read_csv('./data_02.csv')
data_03 = pd.read_csv('./data_03.csv')
2.2 数据合并
data=pd.concat([data_01,data_02,data_03])
data.head()
显示前五行

2.3 数据预览
data.info()

cintbr_st列含有4和空值,而contbr_employer和contbr_occupation这两列中含有较多空值,后续如果使用此数据需要进行处理。
各字段含义
- cand_nm – 接受捐赠的候选人姓名
- contbr_nm – 捐赠人姓名
- contbr_st – 捐赠人所在州
- contbr_employer – 捐赠人所在公司
- contbr_occupation – 捐赠人职业
- contb_receipt_amt – 捐赠数额(美元)
- contb_receipt_dt – 收到捐款的日期
data.describe()

从describe方法输出的结果可以看出赞助金额的一系列统计分析数值,从结果中可以发现赞助金额的最小值为负值,必定为异常值,需要后续处理。
3.数据清洗
3.1 缺失值处理
由于我们后续需要使用contbr_employer,contbr_occupation这两列,所以此处我们用not provided填充缺失值。
data["contbr_occupation"].fillna('not provied', inplace=True)
data["contbr_employer"].fillna('not provied', inplace=True)
预览数据信息,缺失值没有了

3.2 数据筛选
#赞助金额中有负数,为了简化分析过程,我们限定数据集只有正出资额。
data = data[data['contb_receipt_amt']>0]
#查看各个候选人获得的赞助总金额
- List item
#选取候选人为Obama、Romney的子集数据
3.3 数据转换
3.3.1 党派分析(利用字典映射进行转换)
#首先获取竞选人的名单
data["cand_nm"].unique()

#通过搜索引擎等途径,获取到每个总统候选人的所属党派,建立字典parties,候选人名字作为键,所属党派作为对应的值*
parties = {'Bachmann, Michelle': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'Huntsman, Jon': 'Republican',
'Johnson, Gary Earl': 'Republican',
'McCotter, Thaddeus G': 'Republican',
'Obama, Barack': 'Democrat',
'Paul, Ron': 'Republican',
'Pawlenty, Timothy': 'Republican',
'Perry, Rick': 'Republican',
"Roemer, Charles E. 'Buddy' III": 'Republican',
'Romney, Mitt': 'Republican',
'Santorum, Rick': 'Republican'}
#通过map映射函数,增加一列party存储党派信息
#map中可以传入一个字典
data["party"]=data['cand_nm'].map(parties)
data['party'].value_counts()

data.groupby('party')['contb_receipt_amt'].sum()
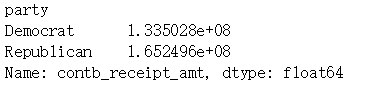
从以上结果可以看出Republican(共和党)接受的赞助总金额更高,Democrat(民主党)获得的赞助次数更多一些
3.3.2 按照职业汇总对赞助金额进行排序
group_occupation = data.groupby('contbr_occupation')['contb_receipt_amt'].sum()
group_occupation.sort_values(ascending=False)[:20]
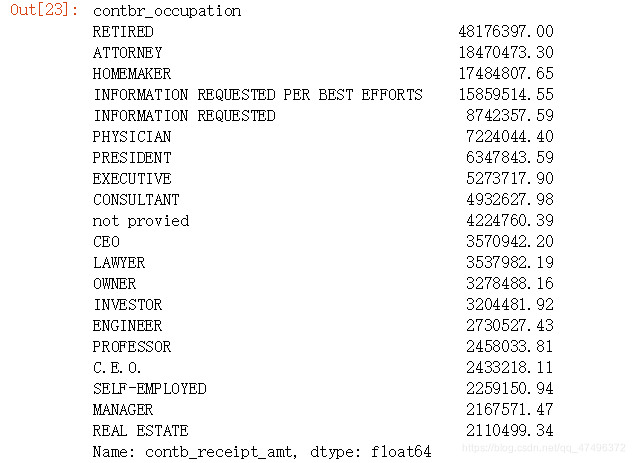
按照职业汇总对赞助总金额进行排序,按照职位进行汇总,计算赞助总金额,展示前20项,发现不少职业是相同的,只不过是表达不一样而已,如C.E.O.与CEO,都是一个职业。我们对职业进行转换,建立一个职业对应字典,把相同职业的不同表达映射为对应的职业。
occupation = {
'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED':'NOT PROVIDED',
'SELF' : 'SELF-EMPLOYED',
'SELF EMPLOYED' : 'SELF-EMPLOYED',
'C.E.O.':'CEO',
'LAWYER':'ATTORNEY',}
f= lambda x : occupation.get(x,x)
data['contbr_occupation'] = data['contbr_occupation'].map(f)
查看一下
group_occupation = data.groupby('contbr_occupation')['contb_receipt_amt'].sum()
group_occupation.sort_values(ascending=False)[:20]

同样地,对雇主信息进行类似转换
emp_mapping = {
'INFORMATION REQUESTED PER BEST EFFORTS' : 'NOT PROVIDED',
'INFORMATION REQUESTED' : 'NOT PROVIDED',
'SELF' : 'SELF-EMPLOYED',
'SELF EMPLOYED' : 'SELF-EMPLOYED'}
f = lambda x: emp_mapping.get(x, x)
data.contbr_employer = data.contbr_employer.map(f)

4. 分析数据
4.1 查看各个候选人的赞助总金额,并选取前10位绘制饼图。
cand_nm_amt = data.groupby('cand_nm')['contb_receipt_amt'].sum().sort_values(ascending=False)[:10]
plt.figure(figsize=(6,6))
cand_nm_amt.plot(kind='pie')

从图中可以发现赞助基本集中在Obama、Romney之间,为了更好的聚焦在两者间的竞争,我们选取这两位候选人的数据子集作进一步分析。
data_vs = data[data['cand_nm'].isin(['Obama, Barack','Romney, Mitt'])]
data_vs.head()
4.2 根据职业和雇主信息分组运算
#由于职业和雇主的处理非常相似,我们定义函数get_top_amounts()对两个字段进行分析处理
def get_top_amounts(group,key,n):
#传入groupby分组后的对象,返回按照key字段汇总的排序前n的数据
totals = group.groupby(key)['contb_receipt_amt'].sum()
return totals.sort_values(ascending=False)[:n]
grouped = data_vs.groupby('cand_nm')
grouped.apply(get_top_amounts,'contbr_occupation',7)

从数据上看,Obama更受精英群体(律师、医生、咨询顾问)的欢迎,Romney则得到更多企业家、企业高管的支持。
同样的,使用get_top_amounts()对雇主进行分析处理
grouped.apply(get_top_amounts,'contbr_employer',7)

Obama:微软、盛德国际律师事务所;Romney:瑞士瑞信银行、高盛公司、巴克莱资本
4.3 对赞助金额进行分组分析
面元化数据用cut进行数据离散化
首先将contb_receipt_amt捐赠数额进行数据离散化
bins = np.array([0,1,10,100,1000,10000,100000,1000000,10000000])
labels = pd.cut(data_vs['contb_receipt_amt'],bins)
labels.head()

接下来对每个离散化的面元进行分组分析
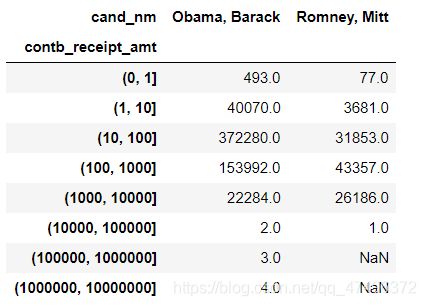
grouped_bins = data_vs.groupby(['cand_nm',labels])
grouped_bins.size().unstack(0)
接下来,我们再统计各区间的赞助金额
amt_sums=data_vs.groupby(['cand_nm',labels]).sum().unstack(0)
amt_sums.fillna(0,inplace=True)
amt_sums

绘制一个简单的条形图来观察一下
amt_sums.plot(kind='bar')

从图中发现Obama有少量的献金者的献金数额达到了10万以上而Romney则没有,我们来查看一下这些人或者机构的名单。
cond = data[data['contb_receipt_amt']>100000]
cond

从查询出来的结果我们发现这些大额的捐款都来自于OBAMA VICTORY FUND 2012 - UNITEMIZED(奥巴马(Obama)胜利基金2012),通过了解这是民众集体的筹集而建立的基金,我们本次主要想研究个人的捐款,所以将这些数据先去除。
#个人的捐款
amt_sums[:-2].plot(kind='bar')
plt.xticks(rotation=45)
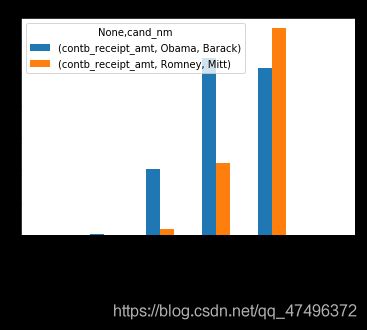
上图虽然大致可以看出两位主要候选人的赞助资金的区间分布,但对比并不突出,如果用百分比堆积图效果会更好,下面我们就实现。
首先算出每个区间两位候选人收到赞助总金额的占比
normed_sums = amt_sums.div(amt_sums.sum(axis=1),axis=0)
normed_sums

堆积条形图
normed_sums.plot(kind='bar',stacked = True)
plt.xticks(rotation=45)

可以看出,小额方面Obama获得的数量和金额比Romney多得多。
4.4 时间处理
4.4.1 str转datetime
data_vs.contb_receipt_dt = pd.to_datetime(data_vs.contb_receipt_dt)
data_vs.head()

4.4.2 以时间位索引
data_vs_time = data_vs.set_index('contb_receipt_dt')
data_vs_time.head()

4.4.3 重采样和频度转换
vs_month = data_vs_time.groupby(['cand_nm']).resample('M')['contb_receipt_amt'].count().unstack(level = 0)
vs_month.head()

绘制面积图
plt.figure(figsize=(20,9))
ax = plt.subplot(1,1,1)
vs_month.plot(kind = 'area',ax = ax,alpha = 0.6)

我们用面积图把11年4月-12年4月两位总统候选人接受的赞助笔数做个对比可以看出,越临近竞选,大家赞助的热情越高涨,奥巴马在各个时段都占据绝对的优势。