天池新人赛,服装关键点检测记录(一)
天池新人赛,服装关键点检测记录(一)
- 赛题理解
- 尝试用YOLOv3解决关键点问题
- YOLOv3回顾:
- 实现:
- 训练结果:
- 后续,既然用物体检测的YOLOv3 难以解决该问题,那么能否用专用的关键点检测模型来解决呢。TODO....
赛题理解
Keypoints Detection of Apparel-Challenge the Baseline
服装关键点检测。
训练集集格式:
image_id,image_category,neckline_left,neckline_right,center_front,shoulder_left,shoulder_right,armpit_left,armpit_right,waistline_left,waistline_right,cuff_left_in,cuff_left_out,cuff_right_in,cuff_right_out,top_hem_left,top_hem_right,waistband_left,waistband_right,hemline_left,hemline_right,crotch,bottom_left_in,bottom_left_out,bottom_right_in,bottom_right_out
Images/blouse/d21eab37ddc74ea5a5f1b4a5d3d9055a.jpg,blouse,241_135_1,301_135_1,259_136_1,216_142_1,319_144_1,212_186_1,307_202_1,-1_-1_-1,-1_-1_-1,203_236_1,195_256_1,278_241_1,283_261_1,206_243_0,292_252_0,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1
Images/blouse/02b54c183d2dbd2c056db14303064886.jpg,blouse,244_76_1,282_76_1,257_99_1,228_81_0,303_85_1,222_134_1,295_131_1,-1_-1_-1,-1_-1_-1,199_153_1,178_100_0,293_173_1,332_150_1,229_161_1,297_162_0,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1,-1_-1_-1
测试集格式:
image_id,image_category
Images/blouse/00009cb5cebc3fe3d7502d6fb2cfe71c.jpg,blouse
Images/skirt/fffeeda340a2865c1c508e2323b1ea1c.jpg,skirt
Images/trousers/000d474348e8e079b24d402650c1447c.jpg,trousers
由于不同服装种类不同,存在的关键点种类有差异(详见链接表格)
关键点有三种状态:-1:不存在,0:存在但被遮挡,1:存在并无遮挡
评价公式:
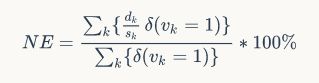
dk是预测点和真实点的欧式距离,sk是归一化系数,δ(vk==1) 中 vk为关键点的状态,当且仅当vk=1的时候δ()=1,也就是说只考虑关键点可见时的结果。这其实已经降低了难度。
尝试用YOLOv3解决关键点问题
YOLOv3回顾:
先贴一个标准YOLOv3模型图:

yolov3 的关键或者说YOLO相较于之前的入Faster-rcnn等模型的 特点在于这几条:
- 引用了DarkNet,引用了深度残差网络,并在每个激活函数前加上一个BN层,抛弃了dropout、全连接层和池化层。
- 通过上采样,实现了predictions across scales,输出了y1~y3 三个尺度的预测。
- 将原图分割成若干个格子,进行预测。
实现:
将最终输出n * n * 255 改为 n * n * (24种关键点 * ( 2个坐标 + 3种状态 + 1可信度)) = n * n * 144 ,
即讲原图分为若干个格子,每个格子都要预测24个关键点相对格子左上角的坐标,以及对应关键点的状态,和可信度。
- 关键点坐标loss 我用了欧式距离 * 2
- 3种状态用了独热code,用交叉熵 * 0.5
- 可信度label 为欧氏距离 与预测值的差 再用 sigmoid 归一化。
- loss 为上面三条相加 再乘以 一个系数 δ ,当且仅当label中关键点落在该格子里时 ,对应预测关键点的δ =1 ,否则 = 0 也就是说只计算相落在对应格子里的关键点 的loss,
由于改动比较小,就不贴代码了。
训练结果:
之所以尝试用YOLOv3解决问题,是因为刚刚学了YOLOv3 , 实际上这么修改模型去解决关键点是比较粗糙的。实际上loss也非常大,维持在200左右降不下来。无法收敛。
但是通过实践,有以下收获和思考:
- 自己实现训练集的dataset,深入了解了YOLOv3训练集是怎么转化成label的
- 每个格子(或者说输出的每格特征)都要预测144个参数,原版中255个参数是包含了9个anchers的,而144个参数中24个特征点每个只预测了1个位置,这是十分粗糙且暴力的。
- 由于服装种类不同,有些关键点的状态为-1,这个特征是没有利用上的。
- 评价函数中,只评价状态为1的关键点,因此,状态为0(不可见) 和 -1 (不存在) 的关键点的 loss 也是可以不计算的。