Python语音基础操作--4.1语音端点检测
《语音信号处理试验教程》(梁瑞宇等)的代码主要是Matlab实现的,现在Python比较热门,所以把这个项目大部分内容写成了Python实现,大部分是手动写的。使用CSDN博客查看帮助文件:
Python语音基础操作–2.1语音录制,播放,读取
Python语音基础操作–2.2语音编辑
Python语音基础操作–2.3声强与响度
Python语音基础操作–2.4语音信号生成
Python语音基础操作–3.1语音分帧与加窗
Python语音基础操作–3.2短时时域分析
Python语音基础操作–3.3短时频域分析
Python语音基础操作–3.4倒谱分析与MFCC系数
Python语音基础操作–4.1语音端点检测
Python语音基础操作–4.2基音周期检测
Python语音基础操作–4.3共振峰估计
Python语音基础操作–5.1自适应滤波
Python语音基础操作–5.2谱减法
Python语音基础操作–5.4小波分解
Python语音基础操作–6.1PCM编码
Python语音基础操作–6.2LPC编码
Python语音基础操作–6.3ADPCM编码
Python语音基础操作–7.1帧合并
Python语音基础操作–7.2LPC的语音合成
Python语音基础操作–10.1基于动态时间规整(DTW)的孤立字语音识别试验
Python语音基础操作–10.2隐马尔科夫模型的孤立字识别
Python语音基础操作–11.1矢量量化(VQ)的说话人情感识别
Python语音基础操作–11.2基于GMM的说话人识别模型
Python语音基础操作–12.1基于KNN的情感识别
Python语音基础操作–12.2基于神经网络的情感识别
Python语音基础操作–12.3基于支持向量机SVM的语音情感识别
Python语音基础操作–12.4基于LDA,PCA的语音情感识别
代码可在Github上下载:busyyang/python_sound_open
双门限法
所谓的端点检测其实就是将语音进行分段,分为轻音,浊音,静音等。主要依据的短时能量以及短时过零率。
短时能量表示为:
E n = ∑ m = 1 N x n 2 ( m ) E_n=\sum\limits_{m=1}^Nx_n^2(m) En=m=1∑Nxn2(m)
短时过零率表示为:
Z n = 1 2 ∑ m = 1 N ∣ s g n [ x n ( m ) ] − s g n [ x n ( m − 1 ) ] ∣ Z_n=\frac{1}{2}\sum\limits_{m=1}^N|sgn[x_n(m)]-sgn[x_n(m-1)]| Zn=21m=1∑N∣sgn[xn(m)]−sgn[xn(m−1)]∣
在双门限法中,短时能量可以较好地区分浊音,静音,清音的能量比较小,容易误判为静音,而过零率可以区分静音和清音。双门限的方法是设定一高一低两个门限,当达到高门限要求时,并在后面的一段时间内持续超过低门限,表示语音信号的开始。
算法过程:
- 计算信号的短时能量和短时过零率;
- 选择一个高门限 T 2 T_2 T2,语音信号的能量包络大部分在门限上,可以进行一次初判。语音起止点位于文献与短时能量包络交点 N 3 , N 4 N_3,N_4 N3,N4的时间间隔之外。
- 根据背景噪声,选择一个较低的门限 T 1 T_1 T1,并从初判起点向左,终点向右搜索,分别找到能语音信号与门限值的交点 N 2 , N 5 N_2,N_5 N2,N5, N 2 N 5 N_2N_5 N2N5段就是双门限判定的语音段。
- 以短时过零率为准,从 N 2 N_2 N2向左, N 5 N_5 N5向右搜索,找到过零率低于的阈值 T 3 T_3 T3的点 N 1 N_1 N1和 N 6 N_6 N6,即为语音段的起止点。
门限的选择是试验获得的。
from chapter3_分析实验.C3_1_y_1 import enframe
from chapter3_分析实验.timefeature import *
def findSegment(express):
"""
分割成語音段
:param express:
:return:
"""
if express[0] == 0:
voiceIndex = np.where(express)
else:
voiceIndex = express
d_voice = np.where(np.diff(voiceIndex) > 1)[0]
voiceseg = {}
if len(d_voice) > 0:
for i in range(len(d_voice) + 1):
seg = {}
if i == 0:
st = voiceIndex[0]
en = voiceIndex[d_voice[i]]
elif i == len(d_voice):
st = voiceIndex[d_voice[i - 1]+1]
en = voiceIndex[-1]
else:
st = voiceIndex[d_voice[i - 1]+1]
en = voiceIndex[d_voice[i]]
seg['start'] = st
seg['end'] = en
seg['duration'] = en - st + 1
voiceseg[i] = seg
return voiceseg
def vad_TwoThr(x, wlen, inc, NIS):
"""
使用门限法检测语音段
:param x: 语音信号
:param wlen: 分帧长度
:param inc: 帧移
:param NIS:
:return:
"""
maxsilence = 15
minlen = 5
status = 0
y = enframe(x, wlen, inc)
fn = y.shape[0]
amp = STEn(x, wlen, inc)
zcr = STZcr(x, wlen, inc, delta=0.01)
ampth = np.mean(amp[:NIS])
zcrth = np.mean(zcr[:NIS])
amp2 = 2 * ampth
amp1 = 4 * ampth
zcr2 = 2 * zcrth
xn = 0
count = np.zeros(fn)
silence = np.zeros(fn)
x1 = np.zeros(fn)
x2 = np.zeros(fn)
for n in range(fn):
if status == 0 or status == 1:
if amp[n] > amp1:
x1[xn] = max(1, n - count[xn] - 1)
status = 2
silence[xn] = 0
count[xn] += 1
elif amp[n] > amp2 or zcr[n] > zcr2:
status = 1
count[xn] += 1
else:
status = 0
count[xn] = 0
x1[xn] = 0
x2[xn] = 0
elif status == 2:
if amp[n] > amp2 and zcr[n] > zcr2:
count[xn] += 1
else:
silence[xn] += 1
if silence[xn] < maxsilence:
count[xn] += 1
elif count[xn] < minlen:
status = 0
silence[xn] = 0
count[xn] = 0
else:
status = 3
x2[xn] = x1[xn] + count[xn]
elif status == 3:
status = 0
xn += 1
count[xn] = 0
silence[xn] = 0
x1[xn] = 0
x2[xn] = 0
el = len(x1[:xn])
if x1[el - 1] == 0:
el -= 1
if x2[el - 1] == 0:
print('Error: Not find endding point!\n')
x2[el] = fn
SF = np.zeros(fn)
NF = np.ones(fn)
for i in range(el):
SF[int(x1[i]):int(x2[i])] = 1
NF[int(x1[i]):int(x2[i])] = 0
voiceseg = findSegment(np.where(SF == 1)[0])
vsl = len(voiceseg.keys())
return voiceseg, vsl, SF, NF, amp, zcr
from chapter2_基础.soundBase import *
from chapter4_特征提取.vad_TwoThr import *
data, fs = soundBase('C4_1_y.wav').audioread()
data /= np.max(data)
N = len(data)
wlen = 200
inc = 80
IS = 0.1
overlap = wlen - inc
NIS = int((IS * fs - wlen) // inc + 1)
fn = (N - wlen) // inc + 1
frameTime = FrameTimeC(fn, wlen, inc, fs)
time = [i / fs for i in range(N)]
voiceseg, vsl, SF, NF, amp, zcr = vad_TwoThr(data, wlen, inc, NIS)
plt.subplot(3, 1, 1)
plt.plot(time, data)
plt.subplot(3, 1, 2)
plt.plot(frameTime, amp)
plt.subplot(3, 1, 3)
plt.plot(frameTime, zcr)
for i in range(vsl):
plt.subplot(3, 1, 1)
plt.plot(frameTime[voiceseg[i]['start']], 1, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 1, 'or')
plt.subplot(3, 1, 2)
plt.plot(frameTime[voiceseg[i]['start']], 1, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 1, 'or')
plt.subplot(3, 1, 3)
plt.plot(frameTime[voiceseg[i]['start']], 1, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 1, 'or')
plt.savefig('images/TwoThr.png')
plt.close()

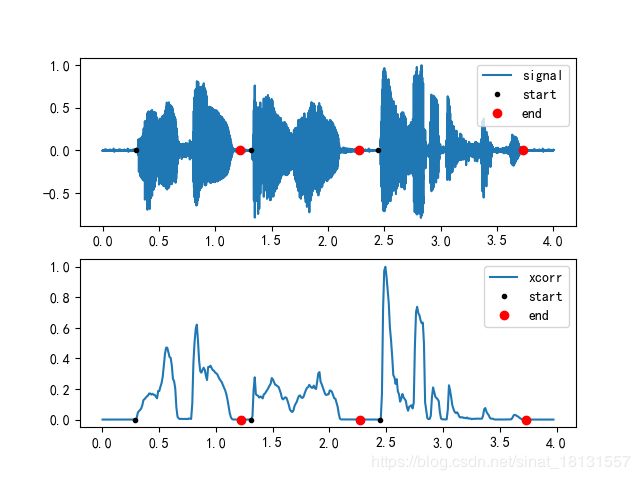
相关法
短时自相关:
R n ( k ) = ∑ m = 1 N − k x n ( m ) x n ( m + k ) , 其 中 ( 0 ⩽ k ⩽ K ) R_n(k)=\sum\limits_{m=1}^{N-k}x_n(m)x_n(m+k),其中(0\leqslant k \leqslant K) Rn(k)=m=1∑N−kxn(m)xn(m+k),其中(0⩽k⩽K)
K K K是最大延迟点数。对于浊音语音可以用于自相关函数求出语音波形序列的基音周期。为了避免检测过程的绝对能量带来的影响,把自相关函数进行归一化处理:
R n ( k ) = R n ( k ) / R n ( 0 ) , ( 0 ⩽ k ⩽ K ) R_n(k)=R_n(k)/R_n(0),(0\leqslant k \leqslant K) Rn(k)=Rn(k)/Rn(0),(0⩽k⩽K)
只有噪声的信号求自相关得到的序列是比较小的序列,如果是含噪语音信号,会有一个较大的值,可以通过这个获取语音起点。设置两个阈值 T 1 , T 2 T_1,T_2 T1,T2,当相关函数最大值大于 T 2 T_2 T2判定为语音,当相关函数最大值大于或小于 T 1 T_1 T1时,判断为语音信号的端点。
from chapter3_分析实验.C3_1_y_1 import enframe
from chapter3_分析实验.timefeature import *
def vad_forw(dst1, T1, T2):
fn = len(dst1)
maxsilence = 8
minlen = 5
status = 0
count = np.zeros(fn)
silence = np.zeros(fn)
xn = 0
x1 = np.zeros(fn)
x2 = np.zeros(fn)
for n in range(1, fn):
if status == 0 or status == 1:
if dst1[n] > T2:
x1[xn] = max(1, n - count[xn] - 1)
status = 2
silence[xn] = 0
count[xn] += 1
elif dst1[n] > T1:
status = 1
count[xn] += 1
else:
status = 0
count[xn] = 0
x1[xn] = 0
x2[xn] = 0
if status == 2:
if dst1[n] > T1:
count[xn] += 1
else:
silence[xn] += 1
if silence[xn] < maxsilence:
count[xn] += 1
elif count[xn] < minlen:
status = 0
silence[xn] = 0
count[xn] = 0
else:
status = 3
x2[xn] = x1[xn] + count[xn]
if status == 3:
status = 0
xn += 1
count[xn] = 0
silence[xn] = 0
x1[xn] = 0
x2[xn] = 0
el = len(x1[:xn])
if x1[el - 1] == 0:
el -= 1
if x2[el - 1] == 0:
print('Error: Not find endding point!\n')
x2[el] = fn
SF = np.zeros(fn)
NF = np.ones(fn)
for i in range(el):
SF[int(x1[i]):int(x2[i])] = 1
NF[int(x1[i]):int(x2[i])] = 0
voiceseg = findSegment(np.where(SF == 1)[0])
vsl = len(voiceseg.keys())
return voiceseg, vsl, SF, NF
def findSegment(express):
"""
分割成語音段
:param express:
:return:
"""
if express[0] == 0:
voiceIndex = np.where(express)
else:
voiceIndex = express
d_voice = np.where(np.diff(voiceIndex) > 1)[0]
voiceseg = {}
if len(d_voice) > 0:
for i in range(len(d_voice) + 1):
seg = {}
if i == 0:
st = voiceIndex[0]
en = voiceIndex[d_voice[i]]
elif i == len(d_voice):
st = voiceIndex[d_voice[i - 1] + 1]
en = voiceIndex[-1]
else:
st = voiceIndex[d_voice[i - 1] + 1]
en = voiceIndex[d_voice[i]]
seg['start'] = st
seg['end'] = en
seg['duration'] = en - st + 1
voiceseg[i] = seg
return voiceseg
def vad_corr(y, wnd, inc, NIS, th1, th2):
x = enframe(y, wnd, inc)
Ru = STAc(x.T)[0]
Rum = Ru / np.max(Ru)
thredth = np.max(Rum[:NIS])
T1 = th1 * thredth
T2 = th2 * thredth
voiceseg, vsl, SF, NF = vad_forw(Rum, T1, T2)
return voiceseg, vsl, SF, NF, Rum
from chapter2_基础.soundBase import *
from chapter4_特征提取.end_detection import *
data, fs = soundBase('C4_1_y.wav').audioread()
data -= np.mean(data)
data /= np.max(data)
IS = 0.25
wlen = 200
inc = 80
N = len(data)
time = [i / fs for i in range(N)]
wnd = np.hamming(wlen)
NIS = int((IS * fs - wlen) // inc + 1)
thr1 = 1.1
thr2 = 1.3
voiceseg, vsl, SF, NF, Rum = vad_corr(data, wnd, inc, NIS, thr1, thr2)
fn = len(SF)
frameTime = FrameTimeC(fn, wlen, inc, fs)
plt.subplot(2, 1, 1)
plt.plot(time, data)
plt.subplot(2, 1, 2)
plt.plot(frameTime, Rum)
for i in range(vsl):
plt.subplot(2, 1, 1)
plt.plot(frameTime[voiceseg[i]['start']], 0, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 0, 'or')
plt.legend(['signal', 'start', 'end'])
plt.subplot(2, 1, 2)
plt.plot(frameTime[voiceseg[i]['start']], 0, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 0, 'or')
plt.legend(['xcorr', 'start', 'end'])
plt.savefig('images/corr.png')
plt.close()
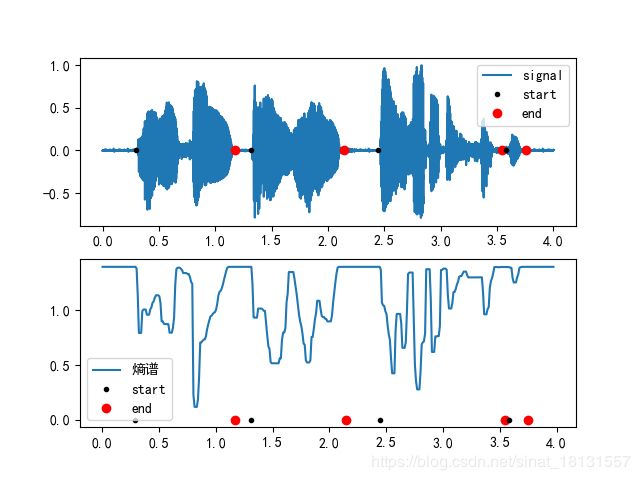
谱熵法
熵是表示信号的有序程度,语音信号的熵与噪声信号的上有较大差异。谱熵端点检测是通过检测谱的平坦程度,检测语音端点。在相同的语音信号,当信噪比降低时,谱熵值的形状大体保持不变。
假设语音信号为 x ( i ) x(i) x(i),加窗分帧后得到第 n n n帧为 x n ( m ) x_n(m) xn(m),其FFT表示为: X n ( k ) X_n(k) Xn(k),k表示第k条谱线。语音帧在频域的短时能量为:
E n = ∑ k = 0 N / 2 X n ( k ) X n ∗ ( k ) E_n=\sum_{k=0}^{N/2}X_n(k)X_n^*(k) En=k=0∑N/2Xn(k)Xn∗(k)
其中N为FFT长度,只取正频率部分。第 k k k谱线的能量谱为 Y n ( k ) = X n ( k ) X n ∗ ( k ) Y_n(k)=X_n(k)X_n^*(k) Yn(k)=Xn(k)Xn∗(k),每个频率分量的归一化谱概率密度函数为:
p n ( k ) = Y n ( k ) ∑ k = 0 N / 2 Y n ( l ) = Y n ( k ) E n p_n(k)=\frac{Y_n(k)}{\sum_{k=0}^{N/2}Y_n(l)}=\frac{Y_n(k)}{E_n} pn(k)=∑k=0N/2Yn(l)Yn(k)=EnYn(k)
该帧短时谱熵定义为:
H n = − ∑ l = 0 N / 2 p n ( k ) lg p n ( k ) H_n=-\sum_{l=0}^{N/2}p_n(k)\lg p_n(k) Hn=−l=0∑N/2pn(k)lgpn(k)
基于谱熵的端点检测算法过程:
- 对语音信号分帧,加窗,取FFT的点数。
- 计算出每帧的谱的能量。
- 计算每帧每个样本的概率密度函数。
- 计算每帧的谱熵值。
- 设置判决门限。
- 更加各帧的谱熵值进行端点检测。
计算每帧的谱熵值用:
H ( i ) = ∑ i = 0 N / 2 − 1 P ( n , i ) ∗ lg [ 1 / P ( n , i ) ] H(i)=\sum_{i=0}^{N/2-1}P(n,i)*\lg [1/P(n,i)] H(i)=i=0∑N/2−1P(n,i)∗lg[1/P(n,i)]
H ( i ) H(i) H(i)为第i帧的谱熵, H ( i ) H(i) H(i)计算的谱的能量变化,而不是谱的能量。可以在不同噪声环境下有一定的稳健性。
from chapter3_分析实验.C3_1_y_1 import enframe
from chapter3_分析实验.timefeature import *
def vad_revr(dst1, T1, T2):
"""
端点检测反向比较函数
:param dst1:
:param T1:
:param T2:
:return:
"""
fn = len(dst1)
maxsilence = 8
minlen = 5
status = 0
count = np.zeros(fn)
silence = np.zeros(fn)
xn = 0
x1 = np.zeros(fn)
x2 = np.zeros(fn)
for n in range(1, fn):
if status == 0 or status == 1:
if dst1[n] < T2:
x1[xn] = max(1, n - count[xn] - 1)
status = 2
silence[xn] = 0
count[xn] += 1
elif dst1[n] < T1:
status = 1
count[xn] += 1
else:
status = 0
count[xn] = 0
x1[xn] = 0
x2[xn] = 0
if status == 2:
if dst1[n] < T1:
count[xn] += 1
else:
silence[xn] += 1
if silence[xn] < maxsilence:
count[xn] += 1
elif count[xn] < minlen:
status = 0
silence[xn] = 0
count[xn] = 0
else:
status = 3
x2[xn] = x1[xn] + count[xn]
if status == 3:
status = 0
xn += 1
count[xn] = 0
silence[xn] = 0
x1[xn] = 0
x2[xn] = 0
el = len(x1[:xn])
if x1[el - 1] == 0:
el -= 1
if x2[el - 1] == 0:
print('Error: Not find endding point!\n')
x2[el] = fn
SF = np.zeros(fn)
NF = np.ones(fn)
for i in range(el):
SF[int(x1[i]):int(x2[i])] = 1
NF[int(x1[i]):int(x2[i])] = 0
voiceseg = findSegment(np.where(SF == 1)[0])
vsl = len(voiceseg.keys())
return voiceseg, vsl, SF, NF
def findSegment(express):
"""
分割成語音段
:param express:
:return:
"""
if express[0] == 0:
voiceIndex = np.where(express)
else:
voiceIndex = express
d_voice = np.where(np.diff(voiceIndex) > 1)[0]
voiceseg = {}
if len(d_voice) > 0:
for i in range(len(d_voice) + 1):
seg = {}
if i == 0:
st = voiceIndex[0]
en = voiceIndex[d_voice[i]]
elif i == len(d_voice):
st = voiceIndex[d_voice[i - 1] + 1]
en = voiceIndex[-1]
else:
st = voiceIndex[d_voice[i - 1] + 1]
en = voiceIndex[d_voice[i]]
seg['start'] = st
seg['end'] = en
seg['duration'] = en - st + 1
voiceseg[i] = seg
return voiceseg
def vad_specEN(data, wnd, inc, NIS, thr1, thr2, fs):
import matplotlib.pyplot as plt
from scipy.signal import medfilt
x = enframe(data, wnd, inc)
X = np.abs(np.fft.fft(x, axis=1))
if len(wnd) == 1:
wlen = wnd
else:
wlen = len(wnd)
df = fs / wlen
fx1 = int(250 // df + 1) # 250Hz位置
fx2 = int(3500 // df + 1) # 500Hz位置
km = wlen // 8
K = 0.5
E = np.zeros((X.shape[0], wlen // 2))
E[:, fx1 + 1:fx2 - 1] = X[:, fx1 + 1:fx2 - 1]
E = np.multiply(E, E)
Esum = np.sum(E, axis=1, keepdims=True)
P1 = np.divide(E, Esum)
E = np.where(P1 >= 0.9, 0, E)
Eb0 = E[:, 0::4]
Eb1 = E[:, 1::4]
Eb2 = E[:, 2::4]
Eb3 = E[:, 3::4]
Eb = Eb0 + Eb1 + Eb2 + Eb3
prob = np.divide(Eb + K, np.sum(Eb + K, axis=1, keepdims=True))
Hb = -np.sum(np.multiply(prob, np.log10(prob + 1e-10)), axis=1)
for i in range(10):
Hb = medfilt(Hb, 5)
Me = np.mean(Hb)
eth = np.mean(Hb[:NIS])
Det = eth - Me
T1 = thr1 * Det + Me
T2 = thr2 * Det + Me
voiceseg, vsl, SF, NF = vad_revr(Hb, T1, T2)
return voiceseg, vsl, SF, NF, Hb
from chapter2_基础.soundBase import *
from chapter4_特征提取.end_detection import *
data, fs = soundBase('C4_1_y.wav').audioread()
data -= np.mean(data)
data /= np.max(data)
IS = 0.25
wlen = 200
inc = 80
N = len(data)
time = [i / fs for i in range(N)]
wnd = np.hamming(wlen)
overlap = wlen - inc
NIS = int((IS * fs - wlen) // inc + 1)
thr1 = 0.99
thr2 = 0.96
voiceseg, vsl, SF, NF, Enm = vad_specEN(data, wnd, inc, NIS, thr1, thr2, fs)
fn = len(SF)
frameTime = FrameTimeC(fn, wlen, inc, fs)
plt.subplot(2, 1, 1)
plt.plot(time, data)
plt.subplot(2, 1, 2)
plt.plot(frameTime, Enm)
for i in range(vsl):
plt.subplot(2, 1, 1)
plt.plot(frameTime[voiceseg[i]['start']], 0, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 0, 'or')
plt.legend(['signal', 'start', 'end'])
plt.subplot(2, 1, 2)
plt.plot(frameTime[voiceseg[i]['start']], 0, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 0, 'or')
plt.legend(['熵谱', 'start', 'end'])
plt.savefig('images/En.png')
plt.close()
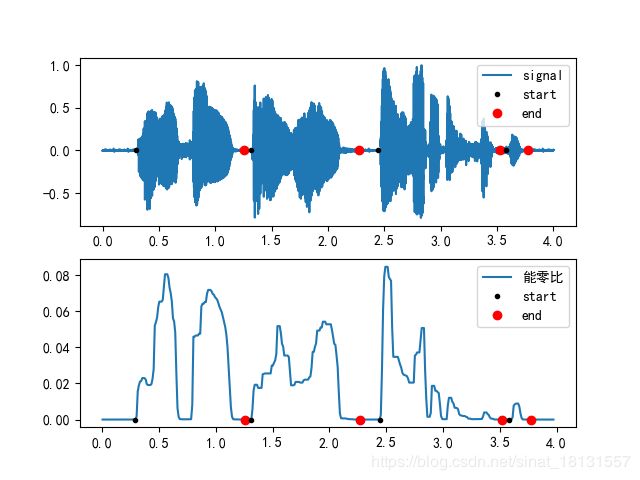
比例法
在噪声情况下,信号的短时能量与过零率可能发生一定变化,甚至影响端点检测。用能量值除以过零率的值,可以突出说话区间,更容易检测过语音端点。将短时能量更新为:
L E n = lg ( 1 + E n / a ) LE_n=\lg(1+E_n/a) LEn=lg(1+En/a)
其中 a a a为常数,适当取值可以区分噪声和清音。过零率的定义首先要对信号进行限幅处理:
x ^ ( m ) = { x n ( m ) , ∣ x n ( m ) > σ ∣ 0 , ∣ x n ( m ) < σ ∣ \hat x(m)=\left \{\begin{array}{ll} x_n(m)&,|x_n(m)>\sigma|\\ 0&,|x_n(m)<\sigma| \end{array}\right. x^(m)={xn(m)0,∣xn(m)>σ∣,∣xn(m)<σ∣
能零比可以表示为:
E Z R n = L E n / ( Z C R n + b ) EZR_n=LE_n/(ZCR_n+b) EZRn=LEn/(ZCRn+b)
b b b是一个较小的常数,为了防止除0的错误发生。
能熵比:
E E F n = 1 + ∣ L E n / H n ∣ EEF_n=\sqrt{1+|LE_n/H_n|} EEFn=1+∣LEn/Hn∣
def vad_pro(data, wnd, inc, NIS, thr1, thr2, mode):
from scipy.signal import medfilt
x = enframe(data, wnd, inc)
if len(wnd) == 1:
wlen = wnd
else:
wlen = len(wnd)
if mode == 1:
a = 2
b = 1
LEn = np.log10(1 + np.sum(np.multiply(x, x) / a, axis=1))
EZRn = LEn / (STZcr(data, wlen, inc) + b)
for i in range(10):
EZRn = medfilt(EZRn, 5)
dth = np.mean(EZRn[:NIS])
T1 = thr1 * dth
T2 = thr2 * dth
Epara = EZRn
elif mode == 2:
a = 2
X = np.abs(np.fft.fft(x, axis=1))
X = X[:, :wlen // 2]
Esum = np.log10(1 + np.sum(np.multiply(X, X) / a, axis=1))
prob = X / np.sum(X, axis=1, keepdims=True)
Hn = -np.sum(np.multiply(prob, np.log10(prob + 1e-10)), axis=1)
Ef = np.sqrt(1 + np.abs(Esum / Hn))
for i in range(10):
Ef = medfilt(Ef, 5)
Me = np.max(Ef)
eth = np.mean(Ef[NIS])
Det = Me - eth
T1 = thr1 * Det + eth
T2 = thr2 * Det + eth
Epara = Ef
voiceseg, vsl, SF, NF = vad_forw(Epara, T1, T2)
return voiceseg, vsl, SF, NF, Epara
from chapter2_基础.soundBase import *
from chapter4_特征提取.end_detection import *
data, fs = soundBase('C4_1_y.wav').audioread()
data -= np.mean(data)
data /= np.max(data)
IS = 0.25
wlen = 200
inc = 80
N = len(data)
time = [i / fs for i in range(N)]
wnd = np.hamming(wlen)
overlap = wlen - inc
NIS = int((IS * fs - wlen) // inc + 1)
mode = 2
if mode == 1:
thr1 = 3
thr2 = 4
tlabel = '能零比'
elif mode == 2:
thr1 = 0.05
thr2 = 0.1
tlabel = '能熵比'
voiceseg, vsl, SF, NF, Epara = vad_pro(data, wnd, inc, NIS, thr1, thr2, mode)
fn = len(SF)
frameTime = FrameTimeC(fn, wlen, inc, fs)
plt.subplot(2, 1, 1)
plt.plot(time, data)
plt.subplot(2, 1, 2)
plt.plot(frameTime, Epara)
for i in range(vsl):
plt.subplot(2, 1, 1)
plt.plot(frameTime[voiceseg[i]['start']], 0, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 0, 'or')
plt.legend(['signal', 'start', 'end'])
plt.subplot(2, 1, 2)
plt.plot(frameTime[voiceseg[i]['start']], 0, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 0, 'or')
plt.legend([tlabel, 'start', 'end'])
plt.savefig('images/{}.png'.format(tlabel))
plt.close()

对数频率距离
对于语音信号取FFT有:
X i ( k ) = ∑ m = 0 N − 1 x i ( m ) exp j 2 π m k N , k = 0 , 1 , . . . , N − 1 X_i(k)=\sum_{m=0}^{N-1}x_i(m)\exp{j\frac{2\pi mk}{N}},k=0,1,...,N-1 Xi(k)=m=0∑N−1xi(m)expjN2πmk,k=0,1,...,N−1
对 X i ( k ) X_i(k) Xi(k)取对数有:
X ^ i ( k ) = 20 lg ∣ X i ( k ) ∣ \hat X_i(k)=20\lg |X_i(k)| X^i(k)=20lg∣Xi(k)∣
两个信号 x 1 ( n ) x_1(n) x1(n)和 x 2 ( n ) x_2(n) x2(n)的对数频谱距离定义为:
d s p e c ( i ) = 1 N 2 ∑ k = 0 N 2 − 1 [ X ^ i 1 ( k ) − X ^ i 2 ( k ) ] 2 d_{spec}(i)=\frac{1}{N_2}\sum_{k=0}^{N_2-1}[\hat X_i^1(k)-\hat X_i^2(k)]^2 dspec(i)=N21k=0∑N2−1[X^i1(k)−X^i2(k)]2
其中 N 2 N_2 N2表示只取正频率部分,即 N 2 = N / 2 + 1 N_2=N/2+1 N2=N/2+1。可以预先计算一些噪声的频率频谱,然后用待检测信号段与平均噪声做距离运算,可以得出是不是噪声,从而进行判断。
def vad_LogSpec(signal, noise, NoiseCounter=0, NoiseMargin=3, Hangover=8):
"""
对数频率距离检测语音端点
:param signal:
:param noise:
:param NoiseCounter:
:param NoiseMargin:
:param Hangover:
:return:
"""
SpectralDist = 20 * (np.log10(signal) - np.log10(noise))
SpectralDist = np.where(SpectralDist < 0, 0, SpectralDist)
Dist = np.mean(SpectralDist)
if Dist < NoiseMargin:
NoiseFlag = 1
NoiseCounter += 1
else:
NoiseFlag = 0
NoiseCounter = 0
if NoiseCounter > Hangover:
SpeechFlag = 0
else:
SpeechFlag = 1
return NoiseFlag, SpeechFlag, NoiseCounter, Dist
from chapter2_基础.soundBase import *
from chapter4_特征提取.end_detection import *
def awgn(x, snr):
snr = 10 ** (snr / 10.0)
xpower = np.sum(x ** 2) / len(x)
npower = xpower / snr
return np.random.randn(len(x)) * np.sqrt(npower) + x
data, fs = soundBase('C4_1_y.wav').audioread()
data -= np.mean(data)
data /= np.max(data)
IS = 0.25
wlen = 200
inc = 80
SNR = 10
N = len(data)
time = [i / fs for i in range(N)]
wnd = np.hamming(wlen)
overlap = wlen - inc
NIS = int((IS * fs - wlen) // inc + 1)
signal = awgn(data, SNR)
y = enframe(signal, wnd, inc)
frameTime = FrameTimeC(y.shape[0], wlen, inc, fs)
Y = np.abs(np.fft.fft(y, axis=1))
Y = Y[:, :wlen // 2]
N = np.mean(Y[:NIS, :], axis=0)
NoiseCounter = 0
SF = np.zeros(y.shape[0])
NF = np.zeros(y.shape[0])
D = np.zeros(y.shape[0])
# 前导段设置NF=1,SF=0
SF[:NIS] = 0
NF[:NIS] = 1
for i in range(NIS, y.shape[0]):
NoiseFlag, SpeechFlag, NoiseCounter, Dist = vad_LogSpec(Y[i, :], N, NoiseCounter, 2.5, 8)
SF[i] = SpeechFlag
NF[i] = NoiseFlag
D[i] = Dist
sindex = np.where(SF == 1)
voiceseg = findSegment(np.where(SF == 1)[0])
vosl = len(voiceseg)
plt.subplot(3, 1, 1)
plt.plot(time, data)
plt.subplot(3, 1, 2)
plt.plot(time, signal)
plt.subplot(3, 1, 3)
plt.plot(frameTime, D)
for i in range(vosl):
plt.subplot(3, 1, 1)
plt.plot(frameTime[voiceseg[i]['start']], 0, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 0, 'or')
plt.legend(['signal', 'start', 'end'])
plt.subplot(3, 1, 2)
plt.plot(frameTime[voiceseg[i]['start']], 0, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 0, 'or')
plt.legend(['noised', 'start', 'end'])
plt.subplot(3, 1, 3)
plt.plot(frameTime[voiceseg[i]['start']], 1, '.k')
plt.plot(frameTime[voiceseg[i]['end']], 1, 'or')
plt.legend(['对数频率距离', 'start', 'end'])
plt.savefig('images/对数频率距离.png')
plt.close()
