Azure机器学习入门(三)创建Azure机器学习实验
- 下载、处理和上传收入普查的数据集;
- 创建一个新的Azure机器学习实验;
- 训练和评价一个预测模型;
从公共资源库下载数据集
在开发预测分析收入水平模型时,我们使用UCI 机器学习资源库的成人收入普查数据。数据集地下载链接为http://archive.ics.uci.edu/ml/datasets/Census+Income。该网站包含下载数据文件的链接,您可将adult.data数据文件下载到本地计算机。此数据集的格式以逗号分隔。另外,该网站还包含了在此数据集中的 15 个属性信息,在上传数据至实验之前我们使用此信息作为创建数据表的列标题。
现在,用 Microsoft Excel 或任何其他电子表格工具中打开 adult.data 文件,并为其添加网站中属性列表的详细信息,这些信息如下列出。注意,其中的一部分属性值为连续的,因为它们以数值的形式表现,另一部分则为其选项值列表。
- 年龄(age),连续值
- 工作种类(Workclass)个人(Private), 无限责任公司(Self-emp-not-inc), 有限责任公司(Self-emp-inc), 联邦政府(Federal-gov), 地方政府( Local-gov), 州政府(State-gov), 无薪人员(Without-pay), 无工作经验人员(Never-worked)离散值
- Fnlwgt连续值
- 教育情况(Education) Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool )离散值
-
受教育年限(Education-num ),连续值
- 婚姻状况(Marital-status) 已婚(Married-civ-spouse),离婚(Divorced),未婚(Never-married),离异(Separated),丧偶(Widowed),已婚配偶缺席(Married-spouse-absent)、 再婚(Married-AF-spouse),离散值
- 职业情况(Occupation)技术支持(Tech-support),维修工艺(Craft-repair),服务行业(Other-service)、 销售(Sales)、 执行管理(Exec-managerial)、 专业教授(Prof-specialty),清洁工(Handlers-cleaners),机床操控人员(Machine-op-inspct)、 行政文员(Adm-clerical)、 养殖渔业(Farming-fishing)、 运输行业(Transport-moving),私人房屋服务(Priv-house-serv),保卫工作(Protective-serv), 武装部队(Armed-Forces)职业情况,离散值
- 亲属情况(Relationship)妻子(Wife),子女(Own-child),丈夫(Husband),外来人员(Not-in-family)、 其他亲戚(Other-relative)、 未婚(Unmarried),离散值
- 种族肤色(Race)白人(White),亚洲太平洋岛民(Asian-Pac-Islander),阿米尔-印度-爱斯基摩人(Amer-Indian-Eskimo)、 其他(Other),黑人(Black)离散值
- 性别(Sex )男性(Female),女性( Male),离散值
- 资本盈利(Capital-gain )连续值
- 资本损失(Capital-loss) ,连续值
- 每周工作时间(Hours-per-week ),连续值
- 国籍(Native-country )美国(United-States)、 柬埔寨(Cambodia)、 英国(England),波多黎各(Puerto-Rico),加拿大(Canada),德国(Germany),美国周边地区(关岛-美属维尔京群岛等)(Outlying-US(Guam-USVI-etc)),印度(India)、 日本(Japan)、 希腊(Greece)、 美国南部(South)、 中国(China)、 古巴(Cuba)、 伊朗(Iran)、 洪都拉斯(Honduras),菲律宾(Philippines)、 意大利(Italy)、 波兰(Poland)、 牙买加(Jamaica)、 越南(Vietnam)、 墨西哥(Mexico)、 葡萄牙(Portugal)、 爱尔兰(Ireland)、 法国(France)、多米尼加共和国(Dominican-Republic)、 老挝(Laos)、 厄瓜多尔(Ecuador)、 台湾(Taiwan)、 海地(Haiti)、 哥伦比亚(Columbia)、 匈牙利(Hungary)、 危地马拉(Guatemala)、 尼加拉瓜(Nicaragua)、苏格兰(Scotland)、 泰国(Thailand)、 南斯拉夫(Yugoslavia),萨尔瓦多(El-Salvador)、 特立尼达和多巴哥(Trinadad&Tobago)、 秘鲁(Peru),香港(Hong),荷兰(Holland-Netherlands)离散值
- 收入 (incom) >50K, <=50K ,离散值
注意,在插入这些列的标题后,一定要以 .csv 格式保存,且保存时将文件命名为 Adult.data.csv 。
下面,先总括一下第一个Azure机器学习实验的数据集的数据特征:
- 十四个与结果相关的唯一属性
- 数据集的实例数为 48,842
- 预测任务是确定用户是否一年收入超过$50,000美元。
此人口收入的普查数据集以被微软作为一个样本数据提供出来了,在其成人普查收入的二元分类(Adult Census Income Binary Classification)数据集中便可以找到。以下我们将手动地一步步全面地介绍整个Azure机器学习工作流过程,很有可能,您的用于预测模型地真实数据集来自于其他外部资源,因此了解机器学习是怎么从开始至结束的全过程是很有必要的。
数据上载至Azure机器学习实验
将人口收入普查数据集添加了列标题后,我们即可将数据上载至Azure机器学习工作区,并将其纳入预测模型。点击屏幕左下方的"+",然后选择上传的数据集。下图显示上传本地数据文件的选项。

图 Azure机器学习中上载本地数据集文件的选项
下一步,点击从本地文件选择即"FROM LOCAL FILE",您可看见如下图所示的上载界面。在此界面您可指定上载文件的属性,比如文件的位置、名称(本例中我们使用 Adult.data.csv )和类型(通常是CSV类型),以及新的数据集的可选说明。
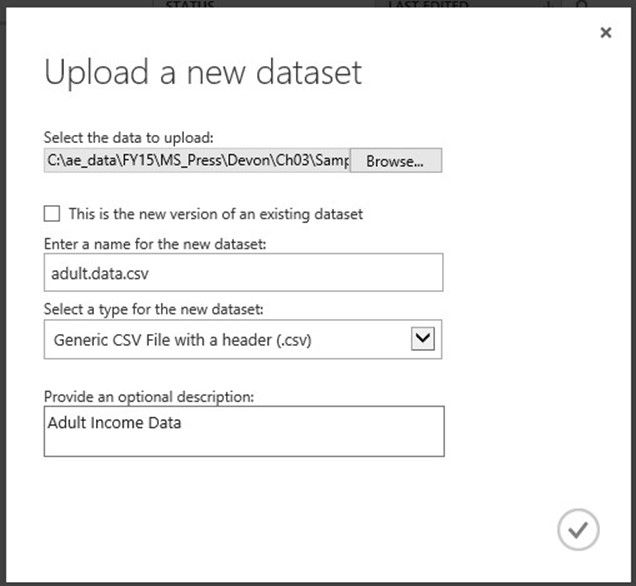
图 Azure机器学习对话框,选择设定从本地文件上载新的数据集
完成信息的输入并点击签入按钮后,您的数据集将异步加载至您的第一个Azure机器学习实验的工作区中。
创建新的Azure机器学习实验
![]()
创建新的实验的方法是点击屏幕左下角的"+NEW"按钮,选择"实验"(EXPERIMENT)à "空白实验"(Blank Experiment)。
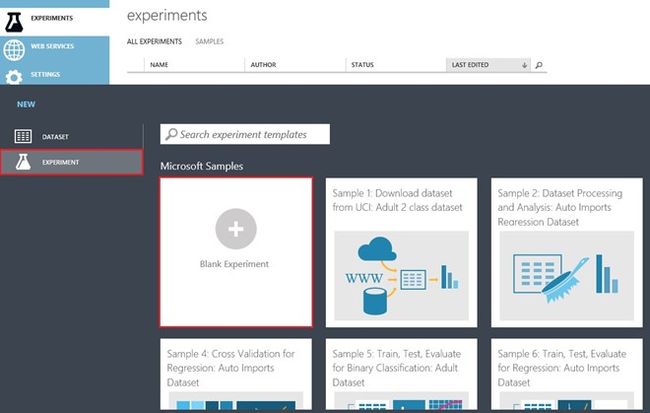
图Azure机器学习中的实验类型列表
请注意,除了空白实验之外,还有许多示例实验模板可供您加载和修改,以便您快速掌握Azure机器学习的实践。
完成新的空白实验的加载后,您可见到如下图所示的Azure ML Studio可视化设计界面。
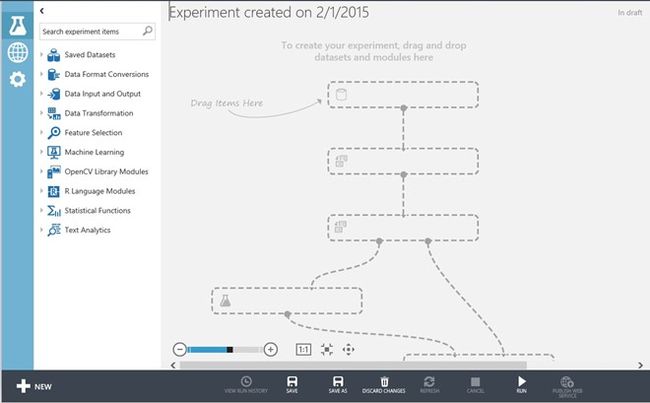
图 在Azure ML Studio设计器中的空白Azure机器学习实验
可以看到设计器由三个主要区域构成:
-
左侧导航窗格 此区域包含Azure机器学习模块的可搜索列表,此模型可用于创建预测分析模型。
- 按功能区域分组的模块
- 数据集的读取和格式转换;
- 使用和训练机器学习算法;
- 评估预测模型的结果。
- 中间窗格 在可视化设计器中,Azure机器学习的实验类似于流程图的形式,可以通过拖拽左侧窗格中的功能模块至可视化设计器的中间窗格组装成工作流。模块可以自由的被拖放在中间窗格的任意位置,模块之间通过输入和输出端口之间画线连接。
- 右侧窗体 在属性视图中,可在右侧窗体查看和设置被选择模块的属性。
在左侧窗体展开"已保存的数据集(Saved Datasets)"选项,便可以看到我们上载的用于Azure机器学习的 Adult.data.csv 数据文件出现在数据集的列表中。图3-13显示 Adult.data.csv 将被拖放至可视化设计器的中间窗体。
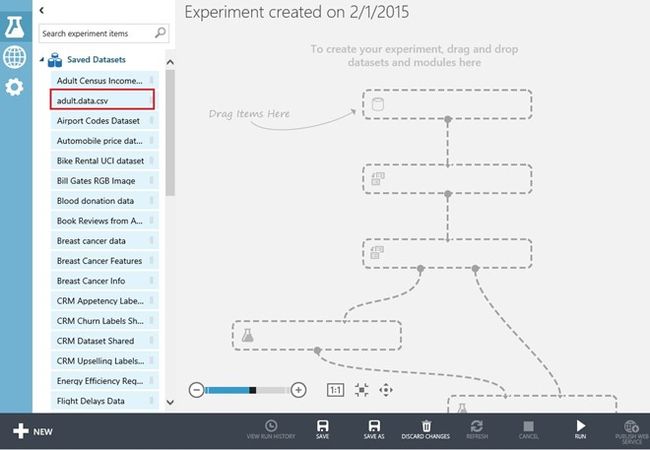
图 将 Adult.data.csv 数据集拖动至设计器面板中
分割数据集
![]()
通常,创建Azure 机器学习实验后,我们都会将数据集分割为两个逻辑分组即训练数据和验证数据,这样做有两个特定目的:
- 训练数据通常用来创建预测模型,基于机器学习算法发现历史数据中的固有模式。
- 验证数据的分组用来测试训练数据创建的预测模型对于已知结果预测的精度和概率。
为完成这个任务,执行以下的步骤将数据集分割成两部分。
- 在左侧窗体中展开"Data Transformation"即数据转换模块。
- 拖动"Split"即分割模块至Azure机器学习设计器。
- 连接"Split"模块与 Adult.data.csv 数据集。
- 点击分割模块并设置"Fraction of rows in the first output dataset"为0.8。这将80%的数据分割至训练数据集中。
下图显示在Azure ML Studio中的操作步骤。

图 分割 Adult.data.csv 数据集为训练数据和测试数据
以上操作就将数据集中的80%的数据用于训练模型,我们可使用剩余的20%数据验证模型的精度。
模型训练
![]()
下一步是借助Azure机器学习算法"教"模型如何评估数据。在左侧窗体中展开"Machine Learning"即机器学习模块,然后展开"Train"子模块,将"Train Model"拖放至设计器中,最后在设计器中连接"Train Model"和"Split"图形。
然后,我们展开"Machine Learning"即机器学习模块下的"Initialize Model"即初始化模型,展开"Classfication"即分类子模块。在此实验中,我们使用"Two-Class Boosted Decision Tree"即双类提升的决策树算法。在左侧窗体中选中该算法模块并将其拖放至设计器中,至此您的实验应该如下图所示。

图 在Azure机器学习实验中连接训练模型和双类提升决策树模块
至此,我们设计了实验将80%的成人收入普查数据集用于训练双类提升决策树算法的模型。
可能您会产生疑问,为什么选择这个算法来处理我们的预测。请不必纠结于为什么要采用此算法而不是别的算法,因为本章的主题是如何在Azure ML Studio中创建预测模型,在后续的章节将涵盖如何选择恰当的机器学习预测算法。所以现在就让我们使用双类提升决策树算法演示Azure机器学习实验的示例。
选择预测列
![]()
要完成算法的配置,我们需要指定数据集中的哪一列数据作为输出或者预测列,数据集中的任意列将基于其他列的数据做预测。
若要执行此操作,在设计器中点击"Train Model",属性窗体将在Azure ML Studio的右侧窗体中显示,如下图所示。

图 打开训练模块的列选择器
若您在设计器中设置,请选择"Launch column selector"即启动列选择器,选择"Include"和列名称为"income"即收入的列。
下图所示的列选择器将数据集中的收入列作为预测列,即要预测的是用户收入。

图 配置训练模块即选择收入列
按照这种方式,Azure机器学习算法从每行数据中的其他列训练模型,以预测收入。我们使用数据集中的80%基于已知的输入和输出数据训练训练模型。
至此,我们已经做好训练模型的准备,选择屏幕底端的"RUN"即运行选项,然后隔岸观火静待Azure机器学习训练我们的模型。您会注意到,实验每个阶段完成的时候,绿色的复选框就出现在每个操作的右侧,如下图所示。
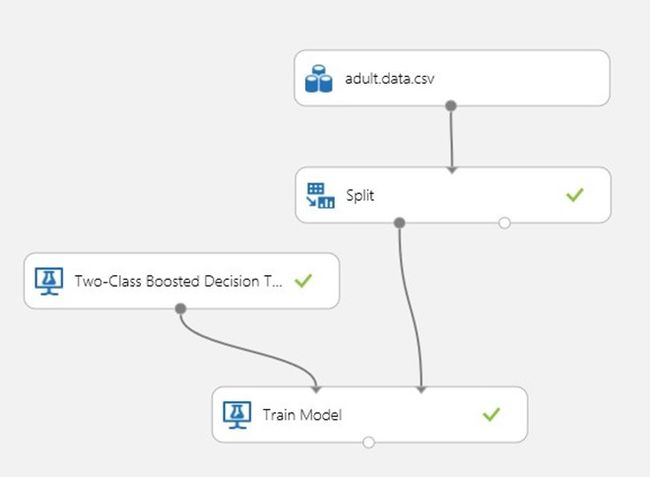
图 训练Azure机器学习的收入预测模型
模型评分
![]()
现在我们已经训练完成新的Azure机器学习预测模型,下一步我们从解决方案的适用性的角度评估预测结果的正确性,以确定模型的精度。请牢记,Azure机器学习解决方案伟大之处在于迭代开发,最终成功的关键是快速试错。
如要实现对模型的评价,首先展开Azure ML Studio左侧的"Machine Learning"即机器学习模块,然后展开"Score Model"即评分模型子模块,将"Score Model"拖放至设计器中,下一步连接"Score Model"和"Train Model",最后链接"Score Model"和"Split"模块。至此,基本上就完成了利用数据集中20%的数据评估预测模型的准确性。
下一步,单击屏幕底部的"Run"即运行按钮等待处理的结果(每个模块右侧出现绿色的复选标记表示运行完毕)。下图是机器学习实验预测收入的运算过程截图。
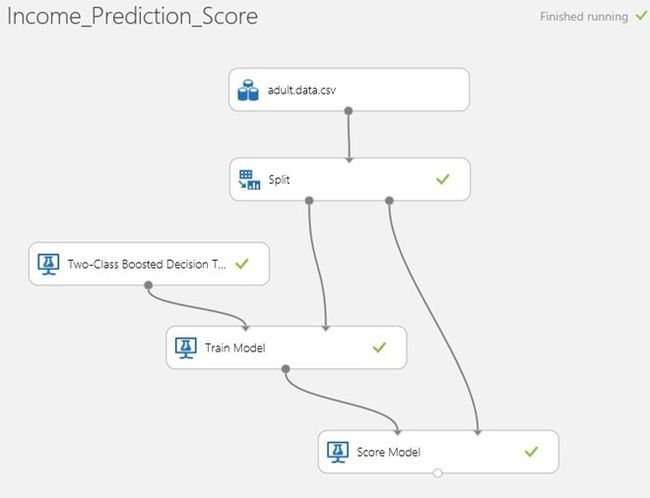
图Azure ML Studio的训练和评分模型
模型计算结果的可视化
![]()
当所有的模型运算结束后,将鼠标悬停在"Score Model"即评分模型上点击右键,从快捷菜单中选择"Visualize"即可视化,如下图所示。

图Azure ML Studio实验中模型评分结果的可视化
- 当您选择可视化新训练的模型数据选项后,会生成一个新的页面。在可视化的界面中滑动滚动条至最右端,您会发现两个额外的列显示在数据集中,如下图所示。
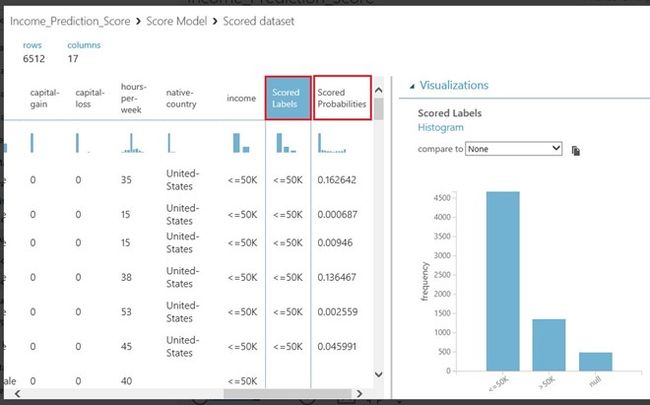
图 训练模型每行新增的两列分别代表针对每一行模型的预测值及预测概率
可以看到现在有两个额外的列添加到了我们的数据集中:
- . "Scored Lables"即评分标签表示数据集中此行数据的预测结果
- "Scored Probabilities"即评分概率表示收入水平超过 $50000 的概率 (或可能性)。
在我们数据集中新增的列提供了算法针对每行数据计算的预测结果和概率因子。概率因子是模型基于数据集中其他列数据预测结果的准确度的概率估计。
通常情况下,预测分析是一个多轮迭代的过程。可能您会尝试许多不同的算法,或者将他们联合使用(在高级的机器学习主题文章中被称为集成)以证明预测模型的有效性。
模型评估
![]()
Azure机器学习最引入注目的功能之一就是它能够快速评估不同的算法,只要轻点鼠标就可完成这些功能,这一切都归功于评估模型。确定模型的精准度的方法很简单,我们只要使用Azure ML Studio内置的评估模型就轻松完成模型的评价。
若要执行此操作,在Azure ML Studio的左侧导航窗格中点击"Machine Learning"即机器学习模块,选择"Evaluate"即评估子模块,最后选择"Evaluate Model"即评估模型的模块,将其拖至可视化设计器页面中的"Score Model"模块下方。连接"Split Model"和"Score Model"即分割模型和评分模型,以及"Evaluate Model"和"Score Model"即评价模型和评分模型,如下图所示。
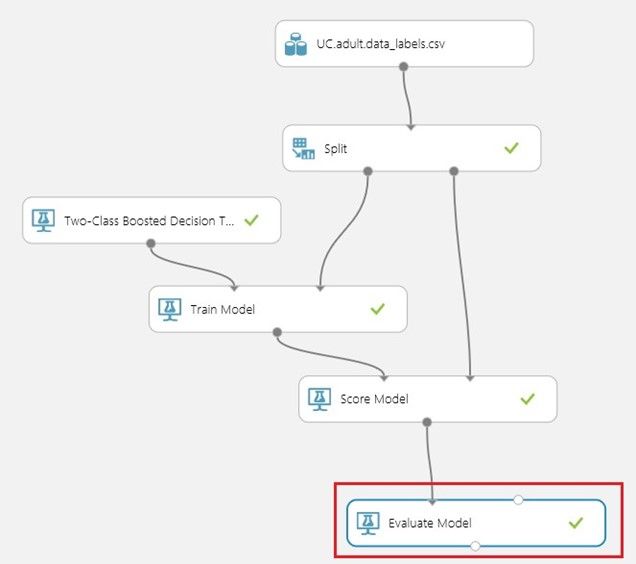
图 链接评估模型评价收入预测的结果
点击Azure ML Studio 屏幕底部的"Run"即运行按钮,在执行过程中您可以查看实验中每个模块的运行情况,如果模块运行完毕会在模块的右侧显示绿色的复选标记。
整个过程运行完毕后,右键单击评估模型的模块底部连接器,在快捷菜单中选择"Visualize"即可视化,评估的结果就会如下图显示。
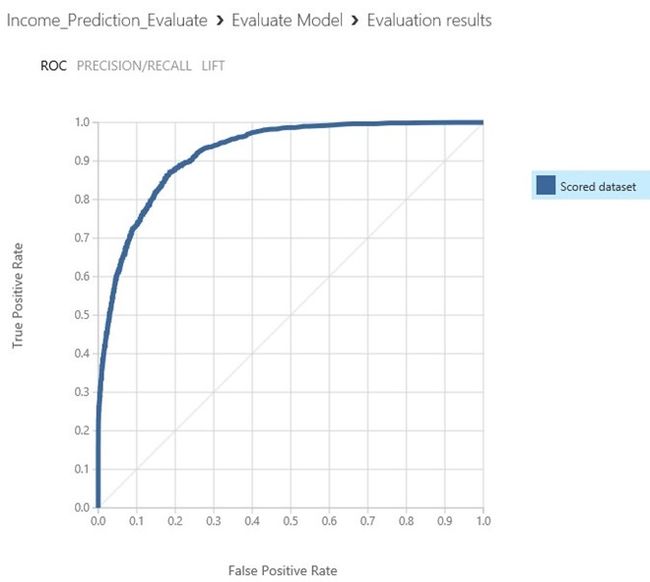
图Azure 机器学习评估模型评价收入预测模型的可视化结果
评估模型模块会产生一套曲线和度量指标,让您对于评分模型的结果或者两个评分模型的对比情况一目了然。评分结果以以下三种形式展示:
- ROC曲线(Receiver Operator Characteristic)即受试者工作特征曲线反映的是真阳性占总的实际阳性的比例。将它与在各种阈值设置情况下假阳性占总的实际阴性的比例进行对比。对角连线表示50%预测的准确性,并可作为评价的基准以便后续提高。曲线位于左边高出对角线的部分表示模型的精准度高,当然您也会希望实验的结果曲线出现在此区域。
-
准确率和召回率是衡量信息检索系统性能的重要指标。准确率是指检索到相关文档数占检索到的文档总数的比例,而召回率是指检索到相关文档数占所有相关文档总数的比例。
- lift曲线是数据挖掘分类器最常用的方式之一,与ROC曲线不同的是lift考虑分类器的准确性,也就是使用分类器获得的正类数量和不使用分类器随机获取正类数量的比例。
在图 3-29 的可视化结果中,您可看到两个数据集("训练"数据集和"验证"数据集)几乎完全相同,即红色和蓝色曲线几乎完全重合,这表明我们的预测模型相当准确。Azure 机器学习入门教程的初衷就是构建合理准确的预测模型,并在下一个阶段中进行应用。
保存实验
![]()
在此步骤中,我们将要保存实验的副本。在屏幕的底部点击"Save As"另存为按钮。在后面的实验中,我们要将实验的核心功能做出重大的修改,所以要先将实验另存,保存的名称建议具有描述性的说明,比如 Azure 机器学习的收入预测——训练模型试验(Azure ML Income Prediction – Train Model Experiment)。
- 下载、处理和上传收入普查的数据集;
- 创建一个新的Azure机器学习实验;
- 训练和评价一个预测模型;
从公共资源库下载数据集
在开发预测分析收入水平模型时,我们使用UCI 机器学习资源库的成人收入普查数据。数据集地下载链接为http://archive.ics.uci.edu/ml/datasets/Census+Income。该网站包含下载数据文件的链接,您可将adult.data数据文件下载到本地计算机。此数据集的格式以逗号分隔。另外,该网站还包含了在此数据集中的 15 个属性信息,在上传数据至实验之前我们使用此信息作为创建数据表的列标题。
现在,用 Microsoft Excel 或任何其他电子表格工具中打开 adult.data 文件,并为其添加网站中属性列表的详细信息,这些信息如下列出。注意,其中的一部分属性值为连续的,因为它们以数值的形式表现,另一部分则为其选项值列表。
- 年龄(age),连续值
- 工作种类(Workclass)个人(Private), 无限责任公司(Self-emp-not-inc), 有限责任公司(Self-emp-inc), 联邦政府(Federal-gov), 地方政府( Local-gov), 州政府(State-gov), 无薪人员(Without-pay), 无工作经验人员(Never-worked)离散值
- Fnlwgt连续值
- 教育情况(Education) Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool )离散值
-
受教育年限(Education-num ),连续值
- 婚姻状况(Marital-status) 已婚(Married-civ-spouse),离婚(Divorced),未婚(Never-married),离异(Separated),丧偶(Widowed),已婚配偶缺席(Married-spouse-absent)、 再婚(Married-AF-spouse),离散值
- 职业情况(Occupation)技术支持(Tech-support),维修工艺(Craft-repair),服务行业(Other-service)、 销售(Sales)、 执行管理(Exec-managerial)、 专业教授(Prof-specialty),清洁工(Handlers-cleaners),机床操控人员(Machine-op-inspct)、 行政文员(Adm-clerical)、 养殖渔业(Farming-fishing)、 运输行业(Transport-moving),私人房屋服务(Priv-house-serv),保卫工作(Protective-serv), 武装部队(Armed-Forces)职业情况,离散值
- 亲属情况(Relationship)妻子(Wife),子女(Own-child),丈夫(Husband),外来人员(Not-in-family)、 其他亲戚(Other-relative)、 未婚(Unmarried),离散值
- 种族肤色(Race)白人(White),亚洲太平洋岛民(Asian-Pac-Islander),阿米尔-印度-爱斯基摩人(Amer-Indian-Eskimo)、 其他(Other),黑人(Black)离散值
- 性别(Sex )男性(Female),女性( Male),离散值
- 资本盈利(Capital-gain )连续值
- 资本损失(Capital-loss) ,连续值
- 每周工作时间(Hours-per-week ),连续值
- 国籍(Native-country )美国(United-States)、 柬埔寨(Cambodia)、 英国(England),波多黎各(Puerto-Rico),加拿大(Canada),德国(Germany),美国周边地区(关岛-美属维尔京群岛等)(Outlying-US(Guam-USVI-etc)),印度(India)、 日本(Japan)、 希腊(Greece)、 美国南部(South)、 中国(China)、 古巴(Cuba)、 伊朗(Iran)、 洪都拉斯(Honduras),菲律宾(Philippines)、 意大利(Italy)、 波兰(Poland)、 牙买加(Jamaica)、 越南(Vietnam)、 墨西哥(Mexico)、 葡萄牙(Portugal)、 爱尔兰(Ireland)、 法国(France)、多米尼加共和国(Dominican-Republic)、 老挝(Laos)、 厄瓜多尔(Ecuador)、 台湾(Taiwan)、 海地(Haiti)、 哥伦比亚(Columbia)、 匈牙利(Hungary)、 危地马拉(Guatemala)、 尼加拉瓜(Nicaragua)、苏格兰(Scotland)、 泰国(Thailand)、 南斯拉夫(Yugoslavia),萨尔瓦多(El-Salvador)、 特立尼达和多巴哥(Trinadad&Tobago)、 秘鲁(Peru),香港(Hong),荷兰(Holland-Netherlands)离散值
- 收入 (incom) >50K, <=50K ,离散值
注意,在插入这些列的标题后,一定要以 .csv 格式保存,且保存时将文件命名为 Adult.data.csv 。
下面,先总括一下第一个Azure机器学习实验的数据集的数据特征:
- 十四个与结果相关的唯一属性
- 数据集的实例数为 48,842
- 预测任务是确定用户是否一年收入超过$50,000美元。
此人口收入的普查数据集以被微软作为一个样本数据提供出来了,在其成人普查收入的二元分类(Adult Census Income Binary Classification)数据集中便可以找到。以下我们将手动地一步步全面地介绍整个Azure机器学习工作流过程,很有可能,您的用于预测模型地真实数据集来自于其他外部资源,因此了解机器学习是怎么从开始至结束的全过程是很有必要的。
数据上载至Azure机器学习实验
将人口收入普查数据集添加了列标题后,我们即可将数据上载至Azure机器学习工作区,并将其纳入预测模型。点击屏幕左下方的"+",然后选择上传的数据集。下图显示上传本地数据文件的选项。
图 Azure机器学习中上载本地数据集文件的选项
下一步,点击从本地文件选择即"FROM LOCAL FILE",您可看见如下图所示的上载界面。在此界面您可指定上载文件的属性,比如文件的位置、名称(本例中我们使用 Adult.data.csv )和类型(通常是CSV类型),以及新的数据集的可选说明。
图 Azure机器学习对话框,选择设定从本地文件上载新的数据集
完成信息的输入并点击签入按钮后,您的数据集将异步加载至您的第一个Azure机器学习实验的工作区中。
创建新的Azure机器学习实验
![]()
创建新的实验的方法是点击屏幕左下角的"+NEW"按钮,选择"实验"(EXPERIMENT)à "空白实验"(Blank Experiment)。
图Azure机器学习中的实验类型列表
请注意,除了空白实验之外,还有许多示例实验模板可供您加载和修改,以便您快速掌握Azure机器学习的实践。
完成新的空白实验的加载后,您可见到如下图所示的Azure ML Studio可视化设计界面。
图 在Azure ML Studio设计器中的空白Azure机器学习实验
可以看到设计器由三个主要区域构成:
-
左侧导航窗格 此区域包含Azure机器学习模块的可搜索列表,此模型可用于创建预测分析模型。
- 按功能区域分组的模块
- 数据集的读取和格式转换;
- 使用和训练机器学习算法;
- 评估预测模型的结果。
- 中间窗格 在可视化设计器中,Azure机器学习的实验类似于流程图的形式,可以通过拖拽左侧窗格中的功能模块至可视化设计器的中间窗格组装成工作流。模块可以自由的被拖放在中间窗格的任意位置,模块之间通过输入和输出端口之间画线连接。
- 右侧窗体 在属性视图中,可在右侧窗体查看和设置被选择模块的属性。
在左侧窗体展开"已保存的数据集(Saved Datasets)"选项,便可以看到我们上载的用于Azure机器学习的 Adult.data.csv 数据文件出现在数据集的列表中。图3-13显示 Adult.data.csv 将被拖放至可视化设计器的中间窗体。
图 将 Adult.data.csv 数据集拖动至设计器面板中
分割数据集
![]()
通常,创建Azure 机器学习实验后,我们都会将数据集分割为两个逻辑分组即训练数据和验证数据,这样做有两个特定目的:
- 训练数据通常用来创建预测模型,基于机器学习算法发现历史数据中的固有模式。
- 验证数据的分组用来测试训练数据创建的预测模型对于已知结果预测的精度和概率。
为完成这个任务,执行以下的步骤将数据集分割成两部分。
- 在左侧窗体中展开"Data Transformation"即数据转换模块。
- 拖动"Split"即分割模块至Azure机器学习设计器。
- 连接"Split"模块与 Adult.data.csv 数据集。
- 点击分割模块并设置"Fraction of rows in the first output dataset"为0.8。这将80%的数据分割至训练数据集中。
下图显示在Azure ML Studio中的操作步骤。
图 分割 Adult.data.csv 数据集为训练数据和测试数据
以上操作就将数据集中的80%的数据用于训练模型,我们可使用剩余的20%数据验证模型的精度。
模型训练
![]()
下一步是借助Azure机器学习算法"教"模型如何评估数据。在左侧窗体中展开"Machine Learning"即机器学习模块,然后展开"Train"子模块,将"Train Model"拖放至设计器中,最后在设计器中连接"Train Model"和"Split"图形。
然后,我们展开"Machine Learning"即机器学习模块下的"Initialize Model"即初始化模型,展开"Classfication"即分类子模块。在此实验中,我们使用"Two-Class Boosted Decision Tree"即双类提升的决策树算法。在左侧窗体中选中该算法模块并将其拖放至设计器中,至此您的实验应该如下图所示。
图 在Azure机器学习实验中连接训练模型和双类提升决策树模块
至此,我们设计了实验将80%的成人收入普查数据集用于训练双类提升决策树算法的模型。
可能您会产生疑问,为什么选择这个算法来处理我们的预测。请不必纠结于为什么要采用此算法而不是别的算法,因为本章的主题是如何在Azure ML Studio中创建预测模型,在后续的章节将涵盖如何选择恰当的机器学习预测算法。所以现在就让我们使用双类提升决策树算法演示Azure机器学习实验的示例。
选择预测列
![]()
要完成算法的配置,我们需要指定数据集中的哪一列数据作为输出或者预测列,数据集中的任意列将基于其他列的数据做预测。
若要执行此操作,在设计器中点击"Train Model",属性窗体将在Azure ML Studio的右侧窗体中显示,如下图所示。
图 打开训练模块的列选择器
若您在设计器中设置,请选择"Launch column selector"即启动列选择器,选择"Include"和列名称为"income"即收入的列。
下图所示的列选择器将数据集中的收入列作为预测列,即要预测的是用户收入。
图 配置训练模块即选择收入列
按照这种方式,Azure机器学习算法从每行数据中的其他列训练模型,以预测收入。我们使用数据集中的80%基于已知的输入和输出数据训练训练模型。
至此,我们已经做好训练模型的准备,选择屏幕底端的"RUN"即运行选项,然后隔岸观火静待Azure机器学习训练我们的模型。您会注意到,实验每个阶段完成的时候,绿色的复选框就出现在每个操作的右侧,如下图所示。
图 训练Azure机器学习的收入预测模型
模型评分
![]()
现在我们已经训练完成新的Azure机器学习预测模型,下一步我们从解决方案的适用性的角度评估预测结果的正确性,以确定模型的精度。请牢记,Azure机器学习解决方案伟大之处在于迭代开发,最终成功的关键是快速试错。
如要实现对模型的评价,首先展开Azure ML Studio左侧的"Machine Learning"即机器学习模块,然后展开"Score Model"即评分模型子模块,将"Score Model"拖放至设计器中,下一步连接"Score Model"和"Train Model",最后链接"Score Model"和"Split"模块。至此,基本上就完成了利用数据集中20%的数据评估预测模型的准确性。
下一步,单击屏幕底部的"Run"即运行按钮等待处理的结果(每个模块右侧出现绿色的复选标记表示运行完毕)。下图是机器学习实验预测收入的运算过程截图。
图Azure ML Studio的训练和评分模型
模型计算结果的可视化
![]()
当所有的模型运算结束后,将鼠标悬停在"Score Model"即评分模型上点击右键,从快捷菜单中选择"Visualize"即可视化,如下图所示。
图Azure ML Studio实验中模型评分结果的可视化
- 当您选择可视化新训练的模型数据选项后,会生成一个新的页面。在可视化的界面中滑动滚动条至最右端,您会发现两个额外的列显示在数据集中,如下图所示。
图 训练模型每行新增的两列分别代表针对每一行模型的预测值及预测概率
可以看到现在有两个额外的列添加到了我们的数据集中:
- . "Scored Lables"即评分标签表示数据集中此行数据的预测结果
- "Scored Probabilities"即评分概率表示收入水平超过 $50000 的概率 (或可能性)。
在我们数据集中新增的列提供了算法针对每行数据计算的预测结果和概率因子。概率因子是模型基于数据集中其他列数据预测结果的准确度的概率估计。
通常情况下,预测分析是一个多轮迭代的过程。可能您会尝试许多不同的算法,或者将他们联合使用(在高级的机器学习主题文章中被称为集成)以证明预测模型的有效性。
模型评估
![]()
Azure机器学习最引入注目的功能之一就是它能够快速评估不同的算法,只要轻点鼠标就可完成这些功能,这一切都归功于评估模型。确定模型的精准度的方法很简单,我们只要使用Azure ML Studio内置的评估模型就轻松完成模型的评价。
若要执行此操作,在Azure ML Studio的左侧导航窗格中点击"Machine Learning"即机器学习模块,选择"Evaluate"即评估子模块,最后选择"Evaluate Model"即评估模型的模块,将其拖至可视化设计器页面中的"Score Model"模块下方。连接"Split Model"和"Score Model"即分割模型和评分模型,以及"Evaluate Model"和"Score Model"即评价模型和评分模型,如下图所示。
图 链接评估模型评价收入预测的结果
点击Azure ML Studio 屏幕底部的"Run"即运行按钮,在执行过程中您可以查看实验中每个模块的运行情况,如果模块运行完毕会在模块的右侧显示绿色的复选标记。
整个过程运行完毕后,右键单击评估模型的模块底部连接器,在快捷菜单中选择"Visualize"即可视化,评估的结果就会如下图显示。
图Azure 机器学习评估模型评价收入预测模型的可视化结果
评估模型模块会产生一套曲线和度量指标,让您对于评分模型的结果或者两个评分模型的对比情况一目了然。评分结果以以下三种形式展示:
- ROC曲线(Receiver Operator Characteristic)即受试者工作特征曲线反映的是真阳性占总的实际阳性的比例。将它与在各种阈值设置情况下假阳性占总的实际阴性的比例进行对比。对角连线表示50%预测的准确性,并可作为评价的基准以便后续提高。曲线位于左边高出对角线的部分表示模型的精准度高,当然您也会希望实验的结果曲线出现在此区域。
-
准确率和召回率是衡量信息检索系统性能的重要指标。准确率是指检索到相关文档数占检索到的文档总数的比例,而召回率是指检索到相关文档数占所有相关文档总数的比例。
- lift曲线是数据挖掘分类器最常用的方式之一,与ROC曲线不同的是lift考虑分类器的准确性,也就是使用分类器获得的正类数量和不使用分类器随机获取正类数量的比例。
在图 3-29 的可视化结果中,您可看到两个数据集("训练"数据集和"验证"数据集)几乎完全相同,即红色和蓝色曲线几乎完全重合,这表明我们的预测模型相当准确。Azure 机器学习入门教程的初衷就是构建合理准确的预测模型,并在下一个阶段中进行应用。
保存实验
![]()
在此步骤中,我们将要保存实验的副本。在屏幕的底部点击"Save As"另存为按钮。在后面的实验中,我们要将实验的核心功能做出重大的修改,所以要先将实验另存,保存的名称建议具有描述性的说明,比如 Azure 机器学习的收入预测——训练模型试验(Azure ML Income Prediction – Train Model Experiment)。