WaveRNN相关原理以及细节介绍
在学习WaveRNN的过程中,除了原文之外呢,网上写的比较全面、细致的博客可以找到一篇(https://www.jianshu.com/p/b3019f2773ed)。首先,我们这里先转载一下这篇博客。然后,在此基础上又做了一些详细的介绍,特别是对于subscale的部分。
简介
这篇博客主要内容是语音合成的新技术,WaveRNN, 谷歌最新提出的语音合成算法,可应用在手机,嵌入式等资源比较少的系统。WaveRNN 采用了三种先进的计算方法去提高生成语音的质量同事保证模型很小。 这个博客基于论文 “Efficient Neural Audio Synthesis”介绍的。 论文链接如下: https://arxiv.org/pdf/1802.08435
这篇文章的创新点有三个。具体如下。
1. 该文提出了一个单层的RNN 网络架构,使用了dual softmax layer, 实现了当前最佳语音生成水准, 可以实时生成24kHz 16-bit的语音。
2. 这篇文章采用了 weight pruning technique, 实现了96% sparsity。
3. 这篇文章提出了高并行度生成语音算法,在语音生成中,把很长的序列生成折叠成若干个短的序列,每个短序列同时生成,进而提高了长序列的生成速度 (fold a long sequency into a batch of shorter sequences and allows one to generate multiple samples at once)
下文会一一介绍每个创新点。 首先是分析语音生成的效率问题, 然后根据语音效率的分析,本文提出了一一优化。
语音生成效率分析
对于序列生成模型来说, 他的生成速度可以用下面的公式表达。

T(u) 就是生成某句子 u 发音需要的时间。一共有|u|个sample, 这里的sample 和digital audio 里的sample是一个意思。不了解的同学可以看我以前的简介博客。 |u| 会非常大,对于高品质声音。比如高保真声音就是24K 个sample, 每个sample 对应16 bit.
上面公式里还有求和表达式中的N, 这个用来代表神经网络的层数,number of layers。 这个可能很大,如果神经网络的层数很多。 c(op) 代表每一层的计算时间,如果网络很宽,或者网络的kernel 很多,计算时间也会很长。 而d(op)代表硬件执行程序的overhead 时间, 包含了调用程序,提取对应参数之类的时间。 要想语音生成的快, 上面的每个参数都要尽量的小。
WaveRNN 的架构

Fig. 1 WaveRNN 的神经网络架构
先看图说话,Fig. 1 中的WaveRNN 有两层softmax layer. coarse 8 代表粗略的8bit. 这个翻译太直译,很拙劣。可以理解成most important 8 bits, 即 8 MSB。 R 这一层是一个GRU layer, 它首先会用来生成coarse 8 bit, coarse 8bit 生成后会当做输入 去生成 fine 8 bits.

我们先来看看公式, 如上图所示。 c_{t-1}, f_{t-1} 分别代表 t-1 时刻 coarse 8 bit 和 fine 8 bit 的输出。 注意观察上图中的softmax 计算, 就可以知道网络的输出就是c_t 和 f_t。其中计算u_t 的时候有一个*, 用来表示masked matrix。masked matrix 主要是在计算coarse 8 bit 的时候使用,因为 x_t 的输入中有个c_t, 这个还没有生成, 所以需要用masked matrx, 使这部分变成0, 来计算。 其中 coarse and fine parts 都在 [0,255]之间, 对应了softmax 的256 个分类。Coarse parts 和fine parts 合起来就是对应声音的16 bit.
如果你还是不了解两段生成过程, 下图具体解释了。 Fig. 2 生成coarse 8 bit. Fig. 3 生成 fine 8 bit. 请注意两个图输入的变化。
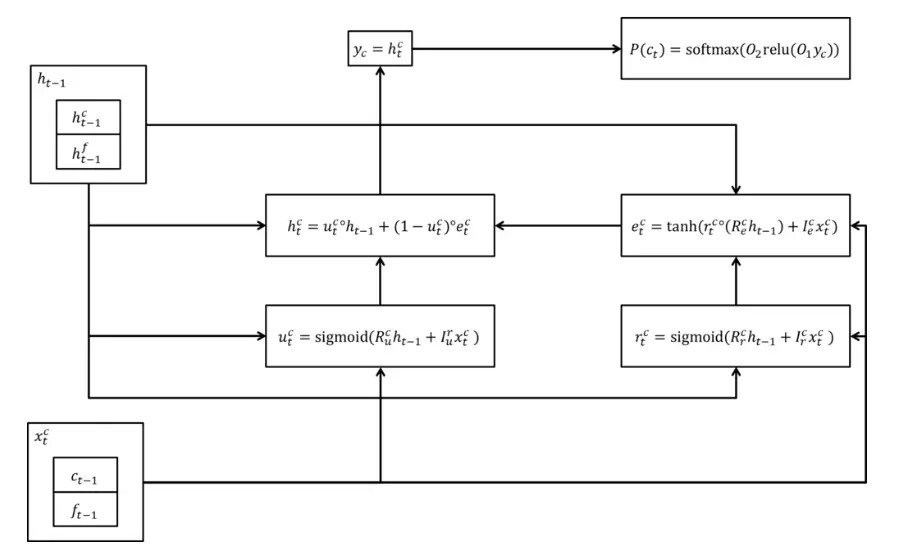
Fig. 2 WaveRNN coarse 8 bit的生成示意图 (source: https://www.monthly-hack.com/entry/2018/02/26/211248)
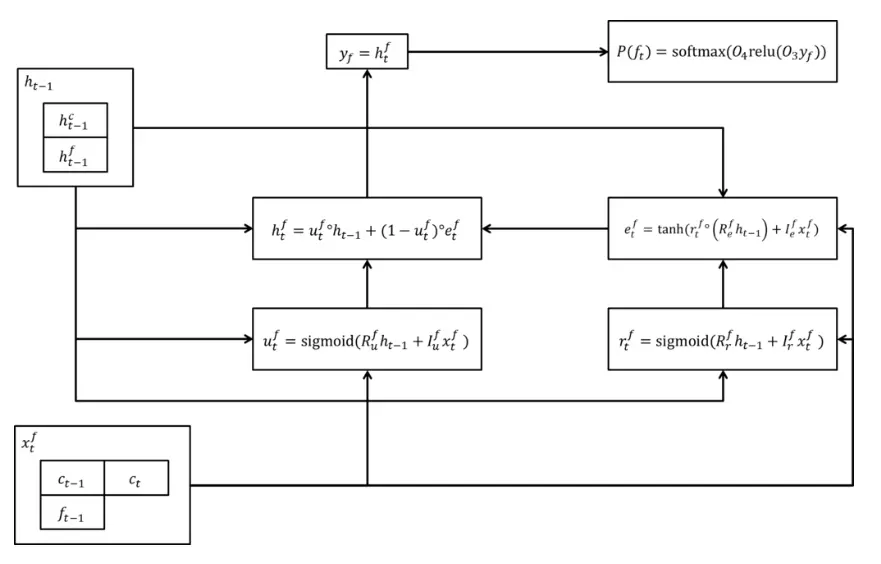
Fig. 3 WaveRNN fine 8 bit的生成示意图 (source: https://www.monthly-hack.com/entry/2018/02/26/211248)
这里的计算对应语音生成效率的分析,就是减少了N 的大小, 理论上N =1, 因为只有一个RNN layer, 所以生成速度可能会比WaveNet 快一些, 因为WaveNet 的N 比较大。 原文又进一步对GPU 计算过程优化, 达到了较好的效果。
我个人的感觉是, 这篇文章把 2^16 的分类器, 拆成了两个2^8 的分类器。直觉上,网络的架构和需求确实变小了, 但是coarse 8 bit 的分类器很重要,却只有 一层RNN layer, 可能会效果不好, 这点需要代码开源后去验证。
WaveRNN 的稀疏化
网络的稀疏化算法有很多, 这篇文章的算法应该不是WaveRNN首次提出来的。以前的deep compression和binary neural network 是搞这方向的两大论文。 感兴趣的读者可以谷歌学习之。 这里就简单介绍下WaveRNN 的做法。
WaveRNN使用的是裁剪法, 在训练中将网络里较小的值,裁剪成0. 具体说来就是首先随机生成一个正常的矩阵 然后每训练500步, 就将weight matrix 里k 个最小的值变成0. 这个k, 是根据稀疏程度的要求确定的。 逐渐会越来越大, 直到满足的稀疏度的要求。 这里WaveRNN 进一步提出了用block sparse 的方式来表达这个稀疏矩阵,据说可以相应的减少神经网络的精度损失。
Subscale WaveRNN

Fig. 4 子规模生成过程

Fig. 5 子规模生成过程解释,水平轴为时间轴
这个创新点有点不好理解, 我尽力解释的让大家理解。上文介绍的WaveRNN 减少了N和d(op)的大小, sparse WaveRNN减少了c(op)的计算,最后要减少的是|u|的大小。一个比较简单的方法就是生成8bit量化的声音, 但是这样声音的保真性损失很大。 这篇文章提出了子规模生成过程, 可以并行的线性减少生成声音所需的时间,可以用下图公式表示。
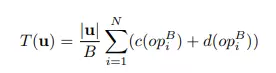
其中B就是batch size。我们看Fig. 4 来解释子规模生成过程。 为了方便解释, 我标注了每一个步骤, 并用Fig. 5 来举例解释。
Step 1: 首先 把一个尺度为L的张量折叠成L/B 大小的B 个张量。 以Fig. 5为例子, 就是把数列, 1,2,3,4,。。。128 这么长的数列折叠成了8 份, 每一份都是16 这么长的张量。 这里叫子规模生成的原因是本来生成的数字是1,2,3,4,5,6... 这些。但是折叠以后生成的是1,9,17,25, 这样的数组, 相当于把原数列降采样,即sub-scale sampling.
Step 2: 解释了声音生成过程,以及相对的依赖关系(conditioning)。这里假设每个子张量的生成需要较小的前瞻性。 我还是用Fig.5 里的图来解释。 首先生成的是第八行, 即 1,9,17,25,33 。。。这列数组。 这列数组会先生成, 然后生成的是第七行数组, 依次生成。 但是第七行数组的生成不仅考虑第八行和第七行当前时间已经生成的数组,还要看第八行横轴未来生成的数组。 按照原论文, 这里主要解释第五行红色数字,76 的生成。 76 的生成, 需要考虑当前时刻之前的所有数字, 即第八行, 第七行, 第六行, 第五行, 1-9列蓝色标注的数值,还要考虑未来, 10-13列产生的数值, 即前瞻性为F=4.
Step 3: 解释了并行生成的过程。 依照我Fig. 5中的图, 就是红色标注的37, 76, 107 是可以同时并列生成。他的前瞻性都是4, 如step 2 中的解释。
Step 4: 最后一步就是把生成的矩阵,再展开变成原来的数列, 1,2,3,4,5.。。。这样的话就实现了高度并行快速生成语音的目的。
按照上图的解释,如果想生成 24kHz 的声音, 每一个子规模的生成速度就是24/16= 1.5kHz, 如果B = 16.
实验结果
实验结果总结一下就是WaveRNN算法很好很棒, 和WaveNet生成质量一样,但是生成速度快,模型小。可惜源代码没有公布,还无法验证具体细节。 Talk is cheap. Show me the code.
第一个结果图

这个呢,就是A/B 测试的结果。 让人去给生成的声音去打分,分数是从3到-3, 3是非常好, -3 是非常差。 上图对比的是WaveRNN-896 和表格中其他网络的表现对比。 首先, WaveRNN-896的表现和 WaveNet-512 效果差不多,说明达到了state-of-the-art result. 接下来用16个子规模, subscale WR 1024, 生成的声音依旧效果很好, 这说明subscale的方法效果很好, 而且基于这算法,可以实现10x 的采样速度。
第二个结果图

这个结果图是保证参数个数不变的情况下, 提高网络的稀疏度,也就是逐渐增大网络模型的大小。 这个实验结果表明, 直到稀疏度98%的情况下,都是网络模型越大,语音生成的效果最好。 这里, NLL代表negative log likelihood, 它的值越小越好。 绿色的224和蓝色384是两个基准, 没有使用block sparse. 而红色和紫色分别使用了block sparse 的稀疏表达方式。
第三个结果图
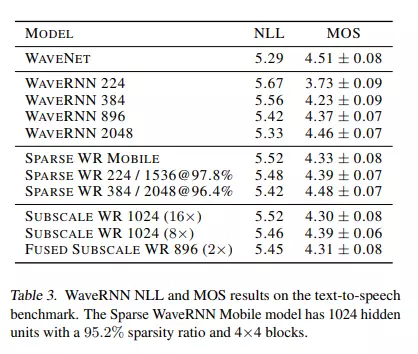
这里的NLL, 就是negative Log-likelihood, MOS 是mean opinion scores. MOS 是打分, 从 1 到 5。 1 表示非常不好, 3 表示普通, 5 表示非常好。 这个表格就是说明WaveRNN 可以表现的和WaveNet 差不多好, 但是速度会快很多。
以上基本是所转载博客的内容。但是通过此文章的评论,以及我个人对该文章的学习,确实对于subscale的部分讲解不是很详细,所以通过搜寻网上资料,再补充下此部分的内容:
我们先看以下动图:
首先,折叠分段。排列按照列的顺序,但是生成则按照每行进行。
第一张图,也就是最下面的一行(第一行)先开始生成,随着生成产生过去依赖。
而当过去依赖为F时(这里为4个sample),同时也是第二行的未来依赖。 第二行开始生成,我们可以看到对于每一行的过去依赖视野没有限制,而未来依赖值为F。
第三幅图中的中间这张图很详细的讲解了整体的过程:就x而言,其过去依赖为其所在行以及之前生成的行的蓝色区域,而未来依赖则为所有过去生成行在其之前步长F为4的绿色区域。
因此,在最后一张图中,我们可以看到,白色的区域sample则为生成过程中同时进行的部分。在所有行生成结束后, 再将其恢复为一串序列。
再换一种更通俗的说法:
1.将原始序列重组为B组(B表示Batch Size,这里为8)。上图中的序号表示在原始序列中的序号。
2.作者发现直接分组并行生成,虽然简单,但效果不好。其原因在于只用到了过去的序列数据,而缺少对整个序列信息的把握。但直接采用全局信息,又不是RNN的做法。为此论文提出了提前量的概念,即上图中的F。
3.我们可以将B组数据看作B个赛道。第1行首先发车(生成数据),当第1行生成了F个数据之后,第2行开始发车。依此类推。显然,只要赛道足够长,则在大多数时间中,都是B个赛车同时再跑。这样就达到了并行运算的效果。如上图中的三个白色方格就是同时生成的。
4.数据生成好之后,再重新组合回去,得到最终的结果序列。
以上部分就是WaveRNN的原理以及详细介绍。