Kafka史上最详细原理总结
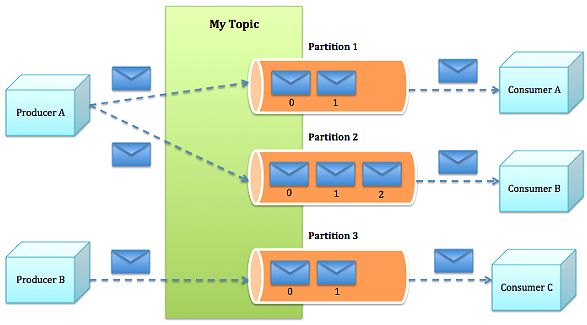
这张图比较清晰地描述了“分区”的概念,对于某一个topic的消息来说,我们可以把这组消息发送给若干个分区,就相当于一组消息分发一样。
分区、Offset、消费线程、group.id的关系
1)一组(类)消息通常由某个topic来归类,我们可以把这组消息“分发”给若干个分区(partition),每个分区的消息各不相同;
2)每个分区都维护着他自己的偏移量(Offset),记录着该分区的消息此时被消费的位置;
3)一个消费线程可以对应若干个分区,但一个分区只能被具体某一个消费线程消费;
4)group.id用于标记某一个消费组,每一个消费组都会被记录他在某一个分区的Offset,即不同consumer group针对同一个分区,都有“各自”的偏移量。
说完概念,必须要注意的一点是,必须确认卡夫卡的server.properties里面的一个属性num.partitions必须被设置成大于1的值,否则消费端再怎么折腾,也用不了多线程哦。我这里的环境下,该属性值被设置成10了。
https://blog.csdn.net/lingbo229/article/details/80761778
kafka 多分区、一个消费者组只有一个消费者该消费者有多个线程(同时消费多个分区)
kafka多分区、一个消费者组有多个消费者、每个消费者一个线程(消费者数=分区数的情况)
kafka多分区、多个消费者组每个消费者组1个消费者1个线程(这种情况不存在,应该是1个消费者启动多个线程同时消费多个分区,而不是1个消费者1个线程轮询多个分区进行消费),如果kafka有多个分区,那么每个消费者组中最终消费时也会有多个线程(线程数=分区数)
原因有人是这样说的:根据源码,创建consumer的时候会触发rebalance操作,底层就是创建Fetch线程。否则用1个线程去轮询3个分区的数据其实也不好实现的,对吧
在同一个消费者组中,topic里面的每个partition只会由一个线程消费(即一个线程对应1个分区,但一个消费者可以创建多个线程),在分配的时候就已经指定好,如果有消费者线程加入或者退出,则会重新开始分配,超出分区个数的消费者也不能消费。
http://www.cnblogs.com/qizhelongdeyang/p/7355309.html
要想保证完全有序消费:在每个消费者组中只能指定一个消费者(指定多了也是浪费,只有1个会工作)(启一个线程消费)且kafka只能设一个分区。
生产者知识:创建多个分区,往分区发送数据时,有两种发送策略:
默认情况下,Kafka根据传递消息的key来进行分区的分配,即hash(key) % numPartitions,如下图所示:
def partition(key: Any, numPartitions: Int): Int = {
Utils.abs(key.hashCode) % numPartitions
}这就保证了相同key的消息一定会被路由到相同的分区。如果你没有指定key,那么Kafka是如何确定这条消息去往哪个分区的呢?随机发送

if(key == null) { // 如果没有指定key
val id = sendPartitionPerTopicCache.get(topic) // 先看看Kafka有没有缓存的现成的分区Id
id match {
case Some(partitionId) =>
partitionId // 如果有的话直接使用这个分区Id就好了
case None => // 如果没有的话,
val availablePartitions = topicPartitionList.filter(_.leaderBrokerIdOpt.isDefined) //找出所有可用分区的leader所在的broker
if (availablePartitions.isEmpty)
throw new LeaderNotAvailableException("No leader for any partition in topic " + topic)
val index = Utils.abs(Random.nextInt) % availablePartitions.size // 从中随机挑一个
val partitionId = availablePartitions(index).partitionId
sendPartitionPerTopicCache.put(topic, partitionId) // 更新缓存以备下一次直接使用
partitionId
}
}
可以看出,Kafka几乎就是随机找一个分区发送无key的消息,然后把这个分区号加入到缓存中以备后面直接使用——当然了,Kafka本身也会清空该缓存(默认每10分钟或每次请求topic元数据时)
消费者知识:消费策略:
range和roundrobin,由参数partition.assignment.strategy指定,默认是range策略。本文只讨论range策略。所谓的range其实就是按照阶段平均分配。举个例子就明白了,假设你有10个分区,P0 ~ P9,consumer线程数是3, C0 ~ C2,那么每个线程都分配哪些分区呢?
C0 消费分区 0, 1, 2, 3
C1 消费分区 4, 5, 6
C2 消费分区 7, 8, 9
Kafka 新版生产者 API
https://cloud.tencent.com/developer/article/1336565
org.apache.kafka
kafka_2.11
0.11.0.0
/*
* www.unisinsight.com Inc.
* Copyright (c) 2018 All Rights Reserved
*/
package com.unisinsight.kafka;
/**
* description 整个发送流程:producer-buffer-partition in broker
*
* 同步异步发送指的是发送到partition in broker的方式
* 这里的同步:是发送消息后需要等待结果返回,才能进行下一行程序的执行
* 异步:是发送消息后不需要等待结果返回,就能进行下一行程序的执行,如果在异步的
* 过程中某条数据发送失败则会丢失该条数据,可通过回调函数返回的信息重新发送该条数据
* acks、retries指的是发送到partition in broker
*
* 关于批量发送:是sender()时进行判断,如果满足批量发送条件,才会往partition in broker发送,如果
* 不满足批量发送条件,则缓存数据到bufffer,什么也不会返回,继续下一次sender()调用。
*
* @author yuwei [[email protected]]
* @date 2019/01/15 10:18
* @since 1.0
*/
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.Future;
public class TransactionProducer {
private static Properties getProps() {
Properties props = new Properties();
props.put("bootstrap.servers", "47.52.199.53:9092");
// 等待所有副本(leader和follower)节点的应答
props.put("acks", "all");
props.put("retries", 0); // 消息发送失败的情况下,重试发送的次数 存在消息发送是成功的,只是由于网络导致ACK没收到的重试,会出现消息被重复发送的情况
props.put("batch.size", 16384); // 批量发送大小,这里是16384b,16kb
props.put("buffer.memory", 33554432); // 缓存大小,根据本机内存大小配置,这里是32M
// 发送频率,如果buffer中数据>=200b,则立即发送,如果buffer中数据<200b但此时已经过了1000ms也会立即发送。
props.put("linger.ms", 1000);
props.put("client.id", "producer-syn-2"); // 发送端id,便于统计
// 压缩算法
props.put("compression.type","snappy");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("transactional.id", "producer-1"); // 每台机器唯一
props.put("enable.idempotence", true); // 设置幂等性
return props;
}
public static void main(String[] args) {
KafkaProducer producer = new KafkaProducer(getProps());
// 初始化事务
producer.initTransactions();
try {
Thread.sleep(2000);
// 开启事务
producer.beginTransaction();
// 同步发送,如果成功返回元数据信息则证明发送成功。
ProducerRecord record = new ProducerRecord("producer-syn", "test4");
// 程序阻塞,直到该条消息发送成功返回元数据信息或者报错
RecordMetadata metadata = producer.send(record).get();
StringBuilder sb = new StringBuilder();
sb.append("record [").append("test4").append("] has been sent successfully!").append("\n")
.append("send to partition ").append(metadata.partition())
.append(", offset = ").append(metadata.offset());
System.out.println(sb.toString());
// 异步发送 程序不会阻塞。
// 大多数时候,我们并不需要等待响应——尽管 Kafka会把目标主题、分区信息和消息的偏移量发送回来,但对于发送端的应用程序来说不是必需的。
//不过在遇到消息发送失败时,我们需要抛出异常、记录错误日志等,这样的情况下可以使用异步发送消息的方式,调用 send() 方法,并指定一个回调函数,服务器在返回响应时调用该函数。
producer.send(new ProducerRecord("producer-asyn", "test5"),
new Callback() {
public void onCompletion(RecordMetadata metadata, Exception e) {
// 如果消息发送失败,抛出异常
// 如果发送消息成功,返回了 RecordMetadata
if (e != null) {
// e.printStackTrace();
StringBuilder sb = new StringBuilder();
sb.append("record [").append("test5").append("] has been sent failed!").append("\n");
System.out.println(sb.toString());
} else {
StringBuilder sb = new StringBuilder();
sb.append("record [").append("test5").append("] has been sent successfully!").append("\n")
.append("send to partition ").append(metadata.partition())
.append(", offset = ").append(metadata.offset());
System.out.println(sb.toString()); }
}
});
// 提交事务
producer.commitTransaction();
} catch (Exception e) {
e.printStackTrace();
// 终止事务
producer.abortTransaction();
}
producer.close();
}
}
Kafka 新版消费者 API(一):订阅主题
https://cloud.tencent.com/developer/article/1336563
Kafka 新版消费者 API(二):提交偏移量
https://cloud.tencent.com/developer/article/1336564