kafka2.0-幂等发送(the idempotent producer)_09
从kafka 0.11版本开始,生成者就支持了两种额外的发送模式 - 幂等发送(the idempotent producer)和事物发送(the transactional producer),可以说这是kafka在支持EOS(exactly-once semantics)上的重要功能。事物发送在后面讲。
什么是幂等?(如果已经了解,可跳过)
举个例子:比如用户对订单付款之后,生成了一个付款成功的消息,发送给了订单系统,订单系统接收到消息之后,将订单状态为已付款,后来,订单系统又收到了一个发货成功的消息,再将订单状态更新为已发货,但是由于网络或者是系统的原因,订单系统再次收到了之前的付款成功的消息,也就是消息重复了,这个在现象在实际应用中也经常出现。订单系统的处理是,查询数据库,发现这个订单状态为已发货,然后不再更改订单状态。这时候,我们可以说订单处理消息的接口是幂等的,如果订单再次将状态更新为已付款,接口就是非幂等的。
kafka的消息重复发送问题
在以前的kafka的老版本中,是支持消息的同步发送的,但是现在,kafka全部改成了异步发送。其具体过程是
kafkaProducer.send()方法将消息发送到缓冲区中,然后后台的一个IO线程读取缓冲区中的数据,将消息发送到对应的broker上。
我们在发送消息的时候,如果设置了retries的次数大于0,就可能一个消息被重复的发送到了broker上,并且broker也保存了多次,具体产生过程如下:
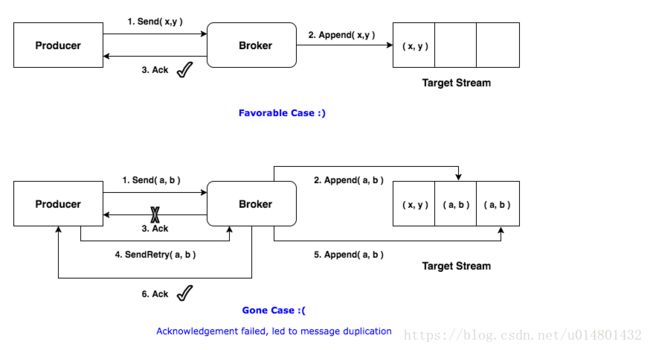
具体的情况是,由于网络原因第三步ack消息回传的时候,客户端没有接收到发送成功确认消息,客户端会重发。所以这就产生了消息的生产。
如果我们设置retries等于0,那么假如在第一步消息就发送失败了,那么消息将无法正确的发送到kafka集群。
幂等发送
如果想发送消息不重复,可以使用kafka的幂等发送,这个功能早在0.11版本中就存在了。
使用幂等发送只需要这样设置props.put("enable.idempotence", true);,默认情况下enable.idempotence为false,如果设置了它为true,retries的默认值将为 Integer.MAX_VALUE,acks默认为all。
开启幂等发送之后,其发送过程将会如下:

为了实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。
PID:当每个新的Producer在初始化的时候,会分配一个唯一的PID,这个PID对用户是不可见的。
Sequence Numbler:(对于每个PID,该Producer发送数据的每个Sequence Number。
Broker端在缓存中保存了这Sequence Numbler,对于接收的每条消息,如果其序号比Broker缓存中序号大于1则接受它,否则将其丢弃。这样就可以实现了消息重复提交了。但是,只能保证单个Producer对于同一个
总而言之,幂等的producer只能保证在同一个session和同一个partition中支持EOS。
源码解读
在KafkaProducer的构造方法中初始化化了一个IO线程,用来发送producer放在缓存中的消息,如下:
this.sender = new Sender(logContext,
client,
this.metadata,
this.accumulator,
maxInflightRequests == 1,
config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
acks,
retries,
metricsRegistry.senderMetrics,
Time.SYSTEM,
this.requestTimeoutMs,
config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
this.transactionManager,
apiVersions);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();Sender实现了Runable接口,是IO线程主体所在,从kafka0.11版本开始,它实现了幂等和事物,所以主要实现看Sender.run方法。
/** sender线程的主体 */
public void run() {
log.debug("Starting Kafka producer I/O thread.");
// main loop, runs until close is called
while (running) {
try {
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
log.debug("Beginning shutdown of Kafka producer I/O thread, sending remaining records.");
// okay we stopped accepting requests but there may still be
// requests in the accumulator or waiting for acknowledgment,
// wait until these are completed.
while (!forceClose && (this.accumulator.hasUndrained() || this.client.inFlightRequestCount() > 0)) {
try {
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
if (forceClose) {
// We need to fail all the incomplete batches and wake up the threads waiting on
// the futures.
log.debug("Aborting incomplete batches due to forced shutdown");
this.accumulator.abortIncompleteBatches();
}
try {
this.client.close();
} catch (Exception e) {
log.error("Failed to close network client", e);
}
log.debug("Shutdown of Kafka producer I/O thread has completed.");
}
/**
* Run a single iteration of sending
*
* @param now The current POSIX time in milliseconds
*/
void run(long now) {
if (transactionManager != null) {
try {
if (transactionManager.shouldResetProducerStateAfterResolvingSequences())
// Check if the previous run expired batches which requires a reset of the producer state.
transactionManager.resetProducerId();
if (!transactionManager.isTransactional()) {
// this is an idempotent producer, so make sure we have a producer id
maybeWaitForProducerId();
} else if (transactionManager.hasUnresolvedSequences() && !transactionManager.hasFatalError()) {
transactionManager.transitionToFatalError(new KafkaException("The client hasn't received acknowledgment for " +
"some previously sent messages and can no longer retry them. It isn't safe to continue."));
} else if (transactionManager.hasInFlightTransactionalRequest() || maybeSendTransactionalRequest(now)) {
// as long as there are outstanding transactional requests, we simply wait for them to return
client.poll(retryBackoffMs, now);
return;
}
// do not continue sending if the transaction manager is in a failed state or if there
// is no producer id (for the idempotent case).
if (transactionManager.hasFatalError() || !transactionManager.hasProducerId()) {
RuntimeException lastError = transactionManager.lastError();
if (lastError != null)
maybeAbortBatches(lastError);
client.poll(retryBackoffMs, now);
return;
} else if (transactionManager.hasAbortableError()) {
accumulator.abortUndrainedBatches(transactionManager.lastError());
}
} catch (AuthenticationException e) {
// This is already logged as error, but propagated here to perform any clean ups.
log.trace("Authentication exception while processing transactional request: {}", e);
transactionManager.authenticationFailed(e);
}
}
long pollTimeout = sendProducerData(now);
client.poll(pollTimeout, now);
}如果是幂等发送,就要求有一个producderID,主要看这个方法maybeWaitForProducerId();
private void maybeWaitForProducerId() {
//如果没有produceId并且,transactionManager没有error那就一直自旋。
while (!transactionManager.hasProducerId() && !transactionManager.hasError()) {
try {
Node node = awaitLeastLoadedNodeReady(requestTimeoutMs);
if (node != null) {
ClientResponse response = sendAndAwaitInitProducerIdRequest(node);
InitProducerIdResponse initProducerIdResponse = (InitProducerIdResponse) response.responseBody();
Errors error = initProducerIdResponse.error();
if (error == Errors.NONE) {
ProducerIdAndEpoch producerIdAndEpoch = new ProducerIdAndEpoch(
initProducerIdResponse.producerId(), initProducerIdResponse.epoch());
transactionManager.setProducerIdAndEpoch(producerIdAndEpoch);
return;
} else if (error.exception() instanceof RetriableException) {
log.debug("Retriable error from InitProducerId response", error.message());
} else {
transactionManager.transitionToFatalError(error.exception());
break;
}
} else {
log.debug("Could not find an available broker to send InitProducerIdRequest to. " +
"We will back off and try again.");
}
} catch (UnsupportedVersionException e) {
transactionManager.transitionToFatalError(e);
break;
} catch (IOException e) {
log.debug("Broker {} disconnected while awaiting InitProducerId response", e);
}
log.trace("Retry InitProducerIdRequest in {}ms.", retryBackoffMs);
time.sleep(retryBackoffMs);
metadata.requestUpdate();
}
}awaitLeastLoadedNodeReady方法
这个方法是随机寻找一个负载最低的broker,也就是说,获取producerID可由任意的broker完成处理。
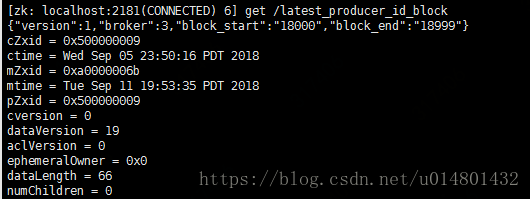
Kafka在zk中新引入了一个节点:
/latest_producer_id_block,broker启动时提前预分配一段PID,当前是0~999,即提前分配出1000个PID来,当PID超过了999,则目前会按照1000的步长重新分配,依次递增,如下图所示:
broker在内存中还保存了下一个待分配的PID。这样,当broker端接收到初始化PID的请求后,它会比较下一个PID是否在当前预分配的PID范围:若是则直接返回;否则再次预分配下一批的PID。现在我们来讨论下为什么这个请求所有broker都能响应——原因就在于集群中所有broker启动时都会启动一个叫TransactionCoordinator的组件,该组件能够执行预分配PID块和分配PID的工作,而所有broker都使用/latest_producer_id_block节点来保存PID块,因此任意一个broker都能响应这个请求。
sendAndAwaitInitProducerIdRequest方法
这个就是发送初始化PID请求的方法,注意当前是同步等待返回结果,即Sender线程会无限阻塞直到broker端返回response(当然依然会受制于request.timeout.ms参数的影响)。得到PID之后,
Sender线程会调用RecordAccumulator.drain()提取当前可发送的消息,在该方法中会将PID,Seq number等信息封装进消息batch中,具体代码参见:RecordAccumulator.drain()。一旦获取到消息batch后,Sender线程开始构建ProduceRequest请求然后发送给broker端。至此producer端的工作就算告一段落了。broker端是如何响应producer请求
实际上,broker最重要的事情就是要区别某个PID的同一个消息batch是否重复发送了。因此在消息被写入到leader底层日志之前必须要先做一次判断,即producer请求中的消息batch是否已然被处理过。如果请求中包含的消息batch与最近一次成功写入的batch相同(即PID相同,batch起始seq number和batch结束seq number都相同),那么该方法便抛出异常,然后由上层方法捕获到该异常封装进ProduceResponse返回。如果batch不相同,则允许此次写入,并在写入完成后更新这些producer信息。最后再说一点:以上所说的幂等
producer一直强调的是“精确处理一次”的语义,实际上幂等producer还有“不乱序”的强语义保证,只不过在0.11版本中这种不乱序主要是通过设置enable.idempotence=true时强行将max.in.flight.requests.per.connection设置成1来实现的。这种实现虽然保证了消息不乱序,但也在某种程度上降低了producer的TPS。据我所知,这个问题将在1.0.0版本中已然得到解决。
源码部分的解读是参见的这篇文章:http://www.mamicode.com/info-detail-2058306.html