有时我们会需要大量线程来处理一些相互独立的任务,为了避免频繁的申请释放线程所带来的开销,我们可以使用线程池
1、线程池拥有若干个线程,是线程的集合,线程池中的线程数目有严格的要求,用于执行大量的相对短暂的任务,线程池中线程的数目一般小于并发的任务量,如果此时存在大量的并发的任务需要执行
,由于线程池中的线程数目小于并发的任务量,因此,任务需要在队列中去等待,等待线程池中的某个线程执行完成后,该线程在从任务队列获得一个任务去执行,这就是线程池的概念。
2、线程池中线程执行的是相对短暂的任务,如果任务的执行时间太长,不适合在线程池中进行处理。
3、任务一般分为两种类型:计算密集型任务和IO密集型任务,计算密集型任务一般是占用CPU资源,这种情况下线程池中的数目一般等于cpu数目,在执行任务的时候很少被阻塞,这种情况下并发数目最佳
对于IO密集型任务,线程任务很容易被IO操作阻塞,这种情况下线程池的数目要大于CPU的数目
对线程池的要求:
1.用于处理大量短暂的任务。
2.动态增加线程,直到达到最大允许的线程数量。
3.动态销毁线程。
线程池的实现类似于”消费者--生产者”模型:
用一个队列存放任务(仓库,缓存)
主线程添加任务(生产者生产任务)
新建线程函数执行任务(消费者执行任务)
由于任务队列是全部线程共享的,就涉及到同步问题。这里采用条件变量和互斥锁来实现。
接下来看下面的一个案例:

线程池的实现就是生产者与消费者模型的应用:
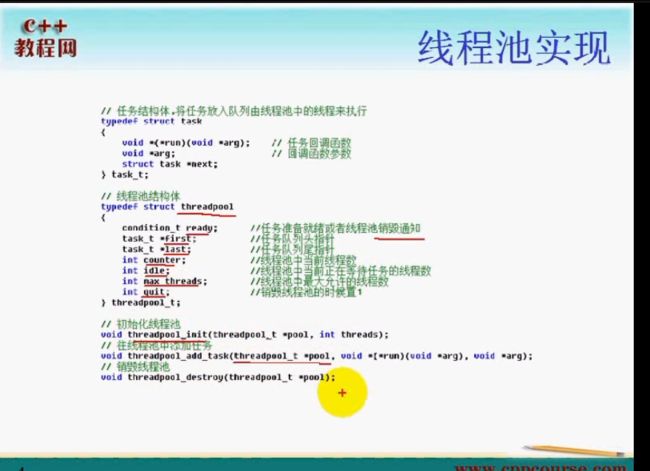
线程池结构体
condition_t 是一个封装的条件变量,表示是否有任务到达或者销毁结构体的通知
第二个字段:任务队列的头指针
第三个字段:任务队列的尾指针
第三个字段:线程池中的当前线程数目
第四个字段:线程池中空闲的线程数目
第五个字段:线程池中最大能够存放线程的最大值
第六个字段:是否销毁线程池,当销毁线程池的时候该字段的这设置成1,当我们销毁线程池的时候需要将该字段的值设置成1
线程池操作的三个函数:
第一个函数初始化一个线程池
第二个函数:向线程池中添加任务,那么任务需要一个函数来执行,第三个参数是传递给执行函数的参数
第三个函数:是销毁该线程池
线程池中的需要执行的任务构成了一个任务队列,采用单链表的数据结构来实现,因此封装了一个结构体来表示任务,通过单链表形成一个任务队列

包括任务的执行函数,传递给执行函数的参数,以及下一个任务的节点地址。
我们来看一下对条件变量的封装:条件变量都和互斥锁在一起配合使用,所以我们这边定义了一个结构体condition,它包含了一个条件变量和互斥锁
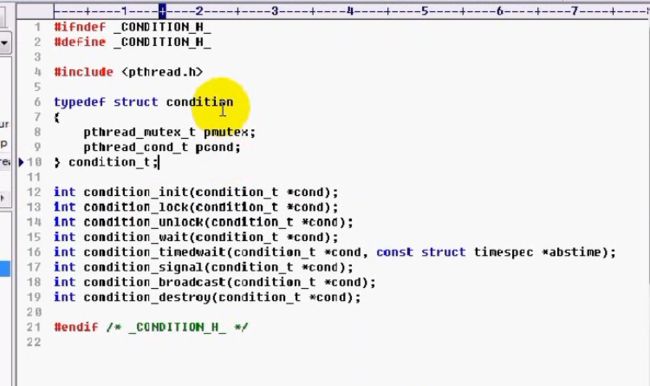
condition_init函数主要对互斥锁和条件变量进行初始化
condition_lock,条件变量在使用的时候,首先需要互斥锁进行锁定,该函数内部实现是对condition结构体中的互斥锁进行锁定
condition_unlock函数主要是对condition中的互斥锁成员变量进行解锁
condition_wait 在条件变量的基础上等待条件的成立
condition_signal 向等待的条件变量发送一个通知
上面就是对条件变量简单的一个封装。
我们在上面的如何使用一个线程池,我们可以先从使用者的角度看如何使用一个线程池:
1、创建一个线程池对象;
2、初始化该线程池;
3、向线程池添加一个任务,执行该任务
4、任务执行完成后,销毁线程池
下面就是使用者使用线程池的代码:
#include#include"pthreadpool.h" #include"condition.h" /* 执行任务的函数 */ void*mytask(void*arg){ printf("thread 0x%0x is working on task %d\n",(int)pthread_self(),*(int*)arg); sleep(1);//表示任务执行的时间 //释放内存 free(arg); return NULL; } int main(){ /*第一步定义一个线程池的结构体* 第二步:初始化一个线程池 3表示线程池中的线程的最大数目 主线程可以看成是生产者线程,向线程池中添加任务 向线程池中添加十个任务 ,将任务的编号传递给执行函数 传递任务编号的时候, threadpool_add_task(&pool,mytask,&i); 上面这种情况存在多线程问题,所以采用下面的这种形式传递编号: int * arg = (int*)malloc(sizeof(int)); * arg = i; */ threadpool_t pool; threadpool_init(&pool,3); int i = 0; for( i = 0 ;i < 10 ;i++){ int * arg = (int*)malloc(sizeof(int)); * arg = i; threadpool_add_task(&pool,mytask,arg); } //执行完任务后销毁线程池 threadpool_destory(&pool); return 0; }
首先是定义一个线程池变量,然后初始化线程池,第一个函数线程池变量的地址,第二参数是线程的最大数目
添加任务的时候
threadpool_add_task
第一个参数是线程池的变量地址,第二个参数第任务的执行函数,第三个参数是传递给执行函数的参数,这个是任务的编号
对于传递任务的编号,不能写成下面的形式
threadpool_add_task(&pool,mytask,&i);
对i取地址传递进行,会出现多线程的问题,所以这里使用mallloc方式申请的一个变量arg,这种方式能够避免线程问题
mytask函数在执行任务的时候,只是打印出一些简单的输出,模拟执行任务耗时一秒,任务执行完成之后需要释放arg变量,因为arg变量是使用malloc来申请内存的,然后返回一个空指针
上面就是线程池的使用情况,当前内部没有实现线程池的内部实现。需要实现三个接口,第一个是线程池的初始化,第二是向线程池中添加任务队列
上面代码是站在使用者的角度使用了线程池,但是没有具体实现内部的功能,下面我们来具体看下线程池的具体的内部实现
接下来我们来具体实现下面的接口
第一个初始化线程池的初始化函数
threadpool_init函数的初始化实现:
//initialize thread pool
void threadpool_init(threadpool_t* pool, int max_threads){
cond_init(&pool->ready);
pool->first = NULL;
pool->last = NULL;
pool->idle = 0;
pool->threadcnt = 0;
pool->max_threads = max_threads;
pool->quit = 0;
}
第一个是对条件变量的初始化调用cond_init(&pool->ready);,cond_init(&pool->ready);该函数实现对成员变量互斥锁和成员变量条件变量的初始化
第二个是对线程池的任务队列的头指针的初始化
第三个是任务队列尾指针的初始化都是为NULL
第三个当前线程池中线程的数目初始化为0
空闲的线程数目也是为0
线程池中最大的线程数目有通过形参传递进来初始化。
线程池中默认销毁线程池的标志为0
初始化向线程池中添加任务
// add a task to thread pool
void threadpool_add_task(threadpool_t *pool, TASK_ROUTINE mytask, TASK_PARA_TYPE arg){
/*
第一步首先生成一个任务
第二步将任务添加到队列当中
*/
task_t * task = (task_t *) malloc(sizeof(task_t));
task->run = mytask;
task->arg = arg;
task->next = NULL;
//使用条件变量和互斥锁进行操作
//首先需要对任务队列进行互斥保护
cond_lock(&pool->ready);
if(pool->first == NULL){ //第一次添加任务
pool->first = task;
}esle{
pool->last->next = task;//添加到尾部
}
//添加完成后要更新线程池结构体的尾指针
pool->last = task;
//判断当前线程是否存在空闲的线程,如果有唤醒该线程执行任务
if(pool->idle > 0){
cond_signal(&pool->ready);
}else {
if(pool->threadcnt < pool->max_threads){
//需要创建新的线程
pthread_t pid;
pthread_create(&pid,NULL,thread_routine,pool);
}
}
cond_unlock(&pool->ready);
}
第一个步骤是生成一个新的任务
task_t * task = (task_t *) malloc(sizeof(task_t));
task->run = mytask;
task->arg = arg;
task->next = NULL;
任务的执行函数由形参传递进行,传递到执行函数的参数也是由外面传递进来。
接下来我们要将生成的新的任务添加到任务队列的队尾部中,如果是第一次添加,直接将队列添加到队列的frist节点,如果是后面添加的
直接添加到队列的尾部,添加到了队列之后,线程池中的last节点需要发送改变
f(pool->first == NULL){ //第一次添加任务
pool->first = task;
}esle{
pool->last->next = task;//添加到尾部
}
pool->last = task;
添加了任务之后,需要判断线程池中有没有等待的线程,如果有我们需要唤醒该线程来消费任务,我们使用条件变量signal函数,必须需要配合互斥锁来使用,我们必须首先使用互斥锁来进行加锁
访问任务队列生产者线程可以访问,消费者线程也可以访问,所以必须要使用互斥锁来锁定,这里相当于生产者和消费者模式中的生产者线程模式。
线程池的实现类似于”消费者--生产者”模型:
用一个队列存放任务(仓库,缓存)
主线程添加任务(生产者生产任务)
新建线程函数执行任务(消费者执行任务)
任务创建了使用signal通知
//首先需要对任务队列进行互斥保护
cond_lock(&pool->ready);
如果没有等待的线程,如果当前的线程池存在的线程数目小于线程池最大的可以容纳的线程池数目,我们可以创建一个线程来消费任务
if(pool->threadcnt < pool->max_threads){
//需要创建新的线程
pthread_t pid;
pthread_create(&pid,NULL,thread_routine,pool);
}
线程的处理函数是thread_routine,将线程池对象传递给线程处理函数,当我们创建了一个新的线程后,线程池中当前线程的数目的值应该加1
我们来看下线程的处理函数
/*线程执行的函数*/
void * thread_routine(void * arg){
printf("thread 0x%x is starting \n",(int)pthread_self());
threadpool_t *pool = (threadpool_t *)arg;
//创建的线程等待任务,然后去执行任务
while(1){
cond_lock(&pool->ready);
pool->idle ++; //空闲任务加1
//等待有任务的到来或者线程池的销毁
while(pool->first == NULL && ! pool->quit ) {
cond_wait(&pool->ready);
}
//有任务或者受到线程池销毁的通知执行任务,处于工作状态
pool->idle --;
if(pool->first != NULL){
//从队头取出任务进行处理
task_t * t = pool->first;
pool->first = t->next;
//执行任务,执行任务是一个耗时的操作,在 cond_wait条件变量满足退出等待之后,该线程还是处于被锁的状态,不清楚的看 条件变量的wait机制
//所以执行任务需要耗时很长,这个时候如果在执行任务的时候处于锁定的状态,那么其他线程无法进行操作,列如无法添加任务,其他线程不能进入等待状态
//所以执行任务之前先解锁,执行任务完成后在加锁
cond_unlock(&pool->ready);
t->run(t->arg);//执行任务
free(t);//释放任务
cond_lock(&pool->ready);
}
//如果等待到线程池销毁的通知
if(pool->quit){
}
cond_unlock(&pool->ready);
}
}
首先在线程的处理函数中首先打印当前线程的名字,接下来我们创建的新的线程,该线程处于等待状态,等待任务的到来,然后去执行任务,这里创建的线程相当于生产者和消费者模式中的消费者情况。
我们就按照消费者使用条件变量的方式来编码,首先消费者是我while(1)循环一直等待任务到来,然后消费任务。按照条件变量的编写方式,我们首先应该加锁,然后等待,条件满足之后消费任务,然后释放锁
cond_lock(&pool->ready);
pool->idle ++; //空闲任务加1
//等待有任务的到来或者线程池的销毁
while(pool->first == NULL && ! pool->quit ) {
cond_wait(&pool->ready);
}
当不满足线程池对象的frist指针不为NULL和不是销毁线程池的通知的条件的时候,消费者线程就一直处于等待的状态
cond_wait内部做了三件事情,第一首先释放cond_lock(&pool->ready)加的锁,然后等待条件变量的改变,此时线程处于阻塞状态,当条件变量满足的情况下,然后对线程进行内存加锁,让线程不再阻塞进入同步独占状态,对任务进行消费执行cond_wait后的代码,
在执行cond_wait后的代码的时候,此时该线程是被锁定的状态是受锁保护的,最后执行完代码后,释放锁
所以执行:
if(pool->first != NULL){
//从队头取出任务进行处理
task_t * t = pool->first;
pool->first = t->next;
//执行任务,执行任务是一个耗时的操作,在 cond_wait条件变量满足退出等待之后,该线程还是处于被锁的状态,不清楚的看 条件变量的wait机制
//所以执行任务需要耗时很长,这个时候如果在执行任务的时候处于锁定的状态,那么其他线程无法进行操作,列如无法添加任务,其他线程不能进入等待状态
//所以执行任务之前先解锁,执行任务完成后在加锁
t->run(t->arg);//执行任务
free(t);//释放任务
}
这个时候是受锁保护的互斥的。
通过上面的分析我们知道在消费者执行任务的时候,执行的任务的代码是被cond_lock(&pool->ready)锁定的,如果任务代码没有执行完成,其他线程是无法进行操作的,
列如我们在执行任务的时候,我们添加任务到队列,添加任务到队列的时候,我们使用了
cond_lock(&pool->ready);
这个时候所被消费者线程在消费任务的时候占用了,此时如果不解锁的话,生产者线程是无法向队列中添加任务,所以在消费者线程执行过程中先解锁,这样在消费任务的过程中,以便生产者线程能够向队列中添加新的任务
代码修改为
if(pool->first != NULL){
//从队头取出任务进行处理
task_t * t = pool->first;
pool->first = t->next;
//执行任务,执行任务是一个耗时的操作,在 cond_wait条件变量满足退出等待之后,该线程还是处于被锁的状态,不清楚的看 条件变量的wait机制
//所以执行任务需要耗时很长,这个时候如果在执行任务的时候处于锁定的状态,那么其他线程无法进行操作,列如无法添加任务,其他线程不能进入等待状态
//所以执行任务之前先解锁,执行任务完成后在加锁
cond_unlock(&pool->ready);
t->run(t->arg);//执行任务
free(t);//释放任务
cond_lock(&pool->ready);
}
还有一种情况是等待到了线程池销毁的通知
如果等待到线程池销毁的通知,并且当前线程池没有可执行任务,说明当前线程池可以被销毁
首先当前线程池的数目应该减一,其次break跳槽while循环,跳槽循环之外我们需要对锁进行解锁,因为在cond_wait后执行的代码都是被锁定的,所以一定在跳出while循环的时候一定要记得解锁