Memcached源码分析 - 数据存储(3)
Memcached源码分析 - 网络模型(1)
Memcached源码分析 - 命令解析(2)
Memcached源码分析 - 数据存储(3)
Memcached源码分析 - 增删改查操作(4)
Memcached源码分析 - 内存存储机制Slabs(5)
Memcached源码分析 - LRU淘汰算法(6)
Memcached源码分析 - 消息回应(7)
开篇
这篇文章的目的主要是为了讲清楚Memcached内部数据存储结构,以及基于该存储结构的增删改查操作过程。
基于一贯的风格,很多内容参考了大神前辈的文章,都一一在参考文章当中列出来了。
数据存储结构
Memcached存储结构图
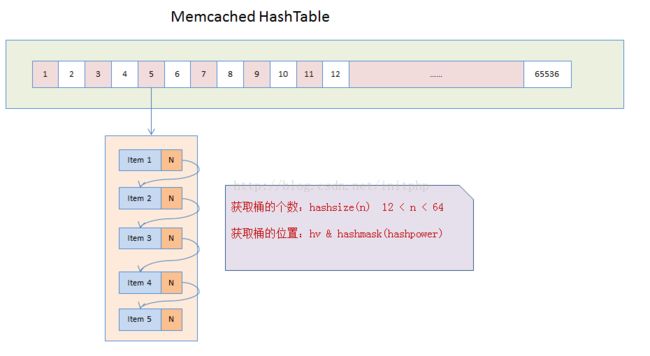
说明:
-
- Memcached在启动的时候,会默认初始化一个HashTable,这个table的默认长度为65536。
-
- 我们将这个HashTable中的每一个元素称为桶,每个桶就是一个item结构的单向链表。
-
- Memcached会将key值hash成一个变量名称为hv的uint32_t类型的值。
-
- 通过hv与桶的个数之间的按位与计算,hv & hashmask(hashpower),就可以得到当前的key会落在哪个桶上面。
-
- 然后会将item挂到这个桶的链表上面。链表主要是通过item结构中的h_next实现。
Item的存储结构
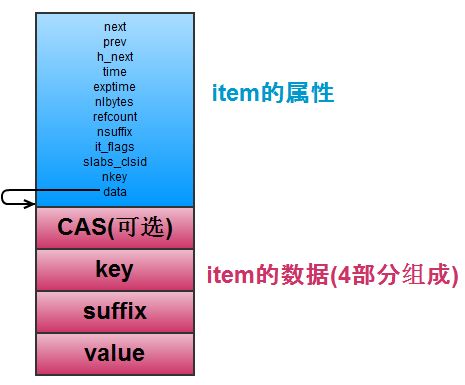
说明:
1.item的结构分两部分, 第一部分定义 item 结构的属性, 包括连接其它 item 的指针 (next, prev),还有最近访问时间(time), 过期的时间(exptime), 以及数据部分的大小, 标志位, key的长度, 引用次数, 以及 item 是从哪个 slabclass 分配而来。
2.第二部分是 item 的数据, 由 CAS, key, suffix, value 组成。 item 结构体的定义使用了一个常用的技巧: 定义空数组 data, 用来指向 item 数据部分的首地址, 使用空数组的好处是 data 指针本身不占用任何存储空间, 为 item 分配存储空间后, data 自然而然就指向数据部分的首地址.
Memcached存储结构源码分析
assoc_init负责初始化hashtable数据结构,通过初始化hashsize(hashpower)大小的数组指针,默认应该是2*16次方大小的数组。
#define HASHPOWER_DEFAULT 16
unsigned int hashpower = HASHPOWER_DEFAULT;
#define hashsize(n) ((ub4)1<<(n))
#define hashmask(n) (hashsize(n)-1)
void assoc_init(const int hashtable_init) {
if (hashtable_init) {
hashpower = hashtable_init;
}
primary_hashtable = calloc(hashsize(hashpower), sizeof(void *));
if (! primary_hashtable) {
fprintf(stderr, "Failed to init hashtable.\n");
exit(EXIT_FAILURE);
}
STATS_LOCK();
stats_state.hash_power_level = hashpower;
stats_state.hash_bytes = hashsize(hashpower) * sizeof(void *);
STATS_UNLOCK();
}
Memcached存储数据结构item定义,item的结构分两部分, 第一部分定义 item 结构的属性,第二部分是 item 的数据。
/**
* Structure for storing items within memcached.
*/
typedef struct _stritem {
/* Protected by LRU locks */
struct _stritem *next;
struct _stritem *prev;
/* Rest are protected by an item lock */
struct _stritem *h_next; /* hash chain next */
rel_time_t time; /* least recent access */
rel_time_t exptime; /* expire time */
int nbytes; /* size of data */
unsigned short refcount;
uint8_t nsuffix; /* length of flags-and-length string */
uint8_t it_flags; /* ITEM_* above */
uint8_t slabs_clsid;/* which slab class we're in */
uint8_t nkey; /* key length, w/terminating null and padding */
/* this odd type prevents type-punning issues when we do
* the little shuffle to save space when not using CAS. */
union {
uint64_t cas;
char end;
} data[];
/* if it_flags & ITEM_CAS we have 8 bytes CAS */
/* then null-terminated key */
/* then " flags length\r\n" (no terminating null) */
/* then data with terminating \r\n (no terminating null; it's binary!) */
} item;
数据增删改查过程
数据查找过程
- 首先通过key的hash值hv找到对应的桶,区分是否在扩容。 primary_hashtable[hv & hashmask(hashpower)];
- 然后遍历桶的单链表,比较key值并找到对应item。
item *assoc_find(const char *key, const size_t nkey, const uint32_t hv) {
item *it;
unsigned int oldbucket;
if (expanding &&
(oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)
{
it = old_hashtable[oldbucket];
} else {
it = primary_hashtable[hv & hashmask(hashpower)];
}
item *ret = NULL;
int depth = 0;
while (it) {
if ((nkey == it->nkey) && (memcmp(key, ITEM_key(it), nkey) == 0)) {
ret = it;
break;
}
it = it->h_next;
++depth;
}
MEMCACHED_ASSOC_FIND(key, nkey, depth);
return ret;
}
数据插入过程
- 首先通过key的hash值hv找到对应的桶。
- 然后将item放到对应桶的单链表的头部
int assoc_insert(item *it, const uint32_t hv) {
unsigned int oldbucket;
// assert(assoc_find(ITEM_key(it), it->nkey) == 0); /* shouldn't have duplicately named things defined */
if (expanding &&
(oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)
{
it->h_next = old_hashtable[oldbucket];
old_hashtable[oldbucket] = it;
} else {
it->h_next = primary_hashtable[hv & hashmask(hashpower)];
primary_hashtable[hv & hashmask(hashpower)] = it;
}
MEMCACHED_ASSOC_INSERT(ITEM_key(it), it->nkey);
return 1;
}
数据删除过程
- 首先通过key的hash值hv找到对应的桶。
- 找到桶对应的链表,遍历单链表,删除对应的Item。
static item** _hashitem_before (const char *key, const size_t nkey, const uint32_t hv) {
item **pos;
unsigned int oldbucket;
if (expanding &&
(oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)
{
pos = &old_hashtable[oldbucket];
} else {
pos = &primary_hashtable[hv & hashmask(hashpower)];
}
while (*pos && ((nkey != (*pos)->nkey) || memcmp(key, ITEM_key(*pos), nkey))) {
pos = &(*pos)->h_next;
}
return pos;
}
void assoc_delete(const char *key, const size_t nkey, const uint32_t hv) {
item **before = _hashitem_before(key, nkey, hv);
if (*before) {
item *nxt;
//因为before是一个二级指针,其值为所查找item的前驱item的h_next成员地址.
//所以*before指向的是所查找的item.因为before是一个二级指针,所以
//*before作为左值时,可以给h_next成员变量赋值。所以下面三行代码是
//使得删除中间的item后,前后的item还能连得起来。
MEMCACHED_ASSOC_DELETE(key, nkey);
nxt = (*before)->h_next;
(*before)->h_next = 0; /* probably pointless, but whatever. */
*before = nxt;
return;
}
/* Note: we never actually get here. the callers don't delete things
they can't find. */
assert(*before != 0);
}
数据扩容过程
1.数据扩容过程是由一个单独线程在检测是否需要扩容,扩容的前提条件是curr_items > (hashsize(hashpower) * 3) / 2,也就是说数据量是原来的1.5倍。
2.检测需要扩容后通过信号通知pthread_cond_signal(&maintenance_cond)开始执行扩容。
3、以2倍的扩容速度进行扩容,primary_hashtable = calloc(hashsize(hashpower + 1), sizeof(void *))。
4、迁移过程是一个逐步迁移过程,每次都只迁移一个桶里面的Item数据。
/* grows the hashtable to the next power of 2. */
static void assoc_expand(void) {
old_hashtable = primary_hashtable;
primary_hashtable = calloc(hashsize(hashpower + 1), sizeof(void *));
if (primary_hashtable) {
if (settings.verbose > 1)
fprintf(stderr, "Hash table expansion starting\n");
hashpower++;
expanding = true;
expand_bucket = 0;
STATS_LOCK();
stats_state.hash_power_level = hashpower;
stats_state.hash_bytes += hashsize(hashpower) * sizeof(void *);
stats_state.hash_is_expanding = true;
STATS_UNLOCK();
} else {
primary_hashtable = old_hashtable;
/* Bad news, but we can keep running. */
}
}
int start_assoc_maintenance_thread() {
int ret;
char *env = getenv("MEMCACHED_HASH_BULK_MOVE");
if (env != NULL) {
hash_bulk_move = atoi(env);
if (hash_bulk_move == 0) {
hash_bulk_move = DEFAULT_HASH_BULK_MOVE;
}
}
pthread_mutex_init(&maintenance_lock, NULL);
if ((ret = pthread_create(&maintenance_tid, NULL,
assoc_maintenance_thread, NULL)) != 0) {
fprintf(stderr, "Can't create thread: %s\n", strerror(ret));
return -1;
}
return 0;
}
static void *assoc_maintenance_thread(void *arg) {
mutex_lock(&maintenance_lock);
while (do_run_maintenance_thread) {
int ii = 0;
//hash_bulk_move用来控制每次迁移,移动多少个桶的item。默认是一个.
//如果expanding为true才会进入循环体,所以迁移线程刚创建的时候,并不会进入循环体
for (ii = 0; ii < hash_bulk_move && expanding; ++ii) {
item *it, *next;
unsigned int bucket;
void *item_lock = NULL;
if ((item_lock = item_trylock(expand_bucket))) {
for (it = old_hashtable[expand_bucket]; NULL != it; it = next) {
next = it->h_next;
bucket = hash(ITEM_key(it), it->nkey) & hashmask(hashpower);
it->h_next = primary_hashtable[bucket];
primary_hashtable[bucket] = it;
}
old_hashtable[expand_bucket] = NULL;
expand_bucket++;
if (expand_bucket == hashsize(hashpower - 1)) {
expanding = false;
free(old_hashtable);
STATS_LOCK();
stats_state.hash_bytes -= hashsize(hashpower - 1) * sizeof(void *);
stats_state.hash_is_expanding = false;
STATS_UNLOCK();
if (settings.verbose > 1)
fprintf(stderr, "Hash table expansion done\n");
}
} else {
usleep(10*1000);
}
if (item_lock) {
item_trylock_unlock(item_lock);
item_lock = NULL;
}
}
if (!expanding) {
started_expanding = false;
pthread_cond_wait(&maintenance_cond, &maintenance_lock);
pause_threads(PAUSE_ALL_THREADS);
assoc_expand();
pause_threads(RESUME_ALL_THREADS);
}
}
return NULL;
}
/* grows the hashtable to the next power of 2. */
static void assoc_expand(void) {
old_hashtable = primary_hashtable;
primary_hashtable = calloc(hashsize(hashpower + 1), sizeof(void *));
if (primary_hashtable) {
if (settings.verbose > 1)
fprintf(stderr, "Hash table expansion starting\n");
hashpower++;
expanding = true;
expand_bucket = 0;
STATS_LOCK();
stats_state.hash_power_level = hashpower;
stats_state.hash_bytes += hashsize(hashpower) * sizeof(void *);
stats_state.hash_is_expanding = true;
STATS_UNLOCK();
} else {
primary_hashtable = old_hashtable;
/* Bad news, but we can keep running. */
}
}
void assoc_start_expand(uint64_t curr_items) {
if (started_expanding)
return;
if (curr_items > (hashsize(hashpower) * 3) / 2 &&
hashpower < HASHPOWER_MAX) {
started_expanding = true;
pthread_cond_signal(&maintenance_cond);
}
}
参考文章
Memcached源码分析之内存管理篇之item结构图及slab结构图
Memcached源码分析 - Memcached源码分析之HashTable(4)
memcached源码分析-----哈希表基本操作以及扩容过程