搜索引擎框架介绍
欢迎将公众号设置为星标,技术文章第一时间看到。我们将一如既往精选技术好文,提供有价值的阅读。如果文章对你有帮助,欢迎点个在看鼓励作者。
技术经验交流:点击入群
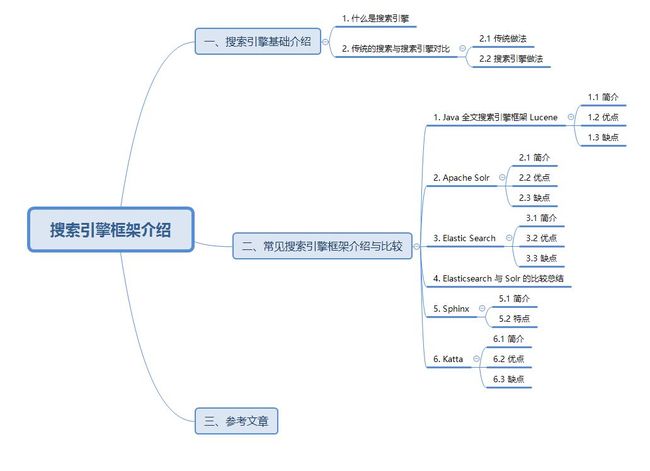
一、搜索引擎基础介绍
1. 什么是搜索引擎
搜索引擎,通常指的是收集了万维网上几千万到几十亿个网页并对网页中的每一个词(即关键词)进行索引,建立索引数据库的全文搜索引擎。当用户查找某个关键词的时候,所有在页面内容中包含了该关键词的网页都将作为搜索结果被搜出来。再经过复杂的算法进行排序(或者包含商业化的竞价排名、商业推广或者广告)后,这些结果将按照与搜索关键词的相关度高低(或与相关度毫无关系),依次排列。
2. 传统的搜索与搜索引擎对比
2.1 传统做法
(1)文档中使用系统的Find查找
(2)mysql中使用like模糊查询
存在问题:
(1)海量数据中不能及时响应,少量数据可以通过传统的MySql建立索引解决
(2)一些无用词不能进行过滤,没法分词
(3)数据量大的话难以拓展
(4)相同的数据难以进行相似度最高的进行排序
2.2 搜索引擎做法
(1)存储非结构化的数据
(2)快速检索和响应我们需要的信息,快-准
(3)进行相关性的排序,过滤等
(4)可以去掉停用词(没有特殊含义的词,比如英文的a,is等,中文: 这,的,是等),框架一般支持可以自定义停用词
二、常见搜索引擎框架介绍与比较
1. Java 全文搜索引擎框架 Lucene
1.1 简介
Lucene的开发语言是Java,也是Java家族中最为出名的一个开源搜索引擎,在Java世界中已经是标准的全文检索程序,它提供了完整的查询引擎和索引引擎,没有中文分词引擎,需要自己去实现,因此用Lucene去做一个搜素引擎需要自己去架构,另外它不支持实时搜索。但是solr和elasticsearch都是基于Lucene封装。
1.2 优点
成熟的解决方案,有很多的成功案例。apache 顶级项目,正在持续快速的进步。庞大而活跃的开发社区,大量的开发人员。它只是一个类库,有足够的定制和优化空间:经过简单定制,就可以满足绝大部分常见的需求;经过优化,可以支持 10亿+ 量级的搜索。
1.3 缺点
需要额外的开发工作。所有的扩展,分布式,可靠性等都需要自己实现;非实时,从建索引到可以搜索中间有一个时间延迟,而当前的“近实时”(Lucene Near Real Time search)搜索方案的可扩展性有待进一步完善.
2. Apache Solr
2.1 简介
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过 http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提 供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
2.2 优点
(1)Solr有一个更大、更成熟的用户、开发和贡献者社区。
(2)支持添加多种格式的索引,如:HTML、PDF、微软 Office 系列软件格式以及 JSON、XML、CSV 等纯文本格式。
(3)Solr比较成熟、稳定。
(4)不考虑建索引的同时进行搜索,速度更快。
2.3 缺点
建立索引时,搜索效率下降,实时索引搜索效率不高
3. Elastic Search
3.1 简介
ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。支持通过HTTP使用JSON进行数据索引。
3.2 优点
(1)Elasticsearch是分布式的。不需要其他组件,分发是实时的,被叫做”Push replication”。
(2)Elasticsearch 完全支持 Apache Lucene 的接近实时的搜索。
(3)处理多租户(multitenancy)不需要特殊配置,而Solr则需要更多的高级设置。
(4)Elasticsearch 采用 Gateway 的概念,使得完备份更加简单。
各节点组成对等的网络结构,某些节点出现故障时会自动分配其他节点代替其进行工作。
3.3 缺点
还不够自动(不适合当前新的Index Warmup API)
4. Elasticsearch 与 Solr 的比较总结
(1)二者安装都很简单
(2)Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
(3)Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
(4)Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
(5)Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
(6)总之,Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
5. Sphinx
5.1 简介
Sphinx一个基于SQL的全文检索引擎,特别为一些脚本语言(PHP,Python,Perl,Ruby)设计搜索API接口。
Sphinx是一个用C++语言写的开源搜索引擎,也是现在比较主流的搜索引擎之一,在建立索引的事件方面比Lucene快50%,但是索引文件比Lucene要大一倍,因此Sphinx在索引的建立方面是空间换取事件的策略,在检索速度上,和lucene相差不大,但检索精准度方面Lucene要优于Sphinx,另外在加入中文分词引擎难度方面,Lucene要优于Sphinx.其中Sphinx支持实时搜索,使用起来比较简单方便.
Sphinx可以非常容易的与SQL数据库和脚本语言集成。当前系统内置MySQL和PostgreSQL 数据库数据源的支持,也支持从标准输入读取特定格式 的XML数据。通过修改源代码,用户可以自行增加新的数据源(例如:其他类型的DBMS 的原生支持)
5.2 特点
(1)高速的建立索引(在当代CPU上,峰值性能可达到10 MB/秒);
(2)高性能的搜索(在2 – 4GB 的文本数据上,平均每次检索响应时间小于0.1秒);
(3)可处理海量数据(目前已知可以处理超过100 GB的文本数据, 在单一CPU的系统上可 处理100 M 文档);
(4)提供了优秀的相关度算法,基于短语相似度和统计(BM25)的复合Ranking方法;
(5)支持分布式搜索;
(6)支持短语搜索
(7)提供文档摘要生成
(8)可作为MySQL的存储引擎提供搜索服务;
(9)支持布尔、短语、词语相似度等多种检索模式;
(10)文档支持多个全文检索字段(最大不超过32个);
(11)文档支持多个额外的属性信息(例如:分组信息,时间戳等);
(12)支持断词;
6. Katta
6.1 简介
基于 Lucene 的,支持分布式,可扩展,具有容错功能,准实时的搜索方案。
6.2 优点
开箱即用,可以与 Hadoop 配合实现分布式。具备扩展和容错机制。
6.3 缺点
只是搜索方案,建索引部分还是需要自己实现。在搜索功能上,只实现了最基本的需求。成功案例较少,项目的成熟度稍微差一些。因为需要支持分布式,对于一些复杂的查询需求,定制的难度会比较大。
三、参考文章
https://blog.csdn.net/belalds/article/details/82686387
https://blog.csdn.net/peng_0129/article/details/86150438
https://www.cnblogs.com/panxuejun/p/5952681.html
推荐阅读(点击文字可跳转)
1. 深究Spring中Bean的生命周期
2. 深入SpringBoot核心注解原理
3.线上环境部署概览
4.Springboot Vue shiro 实现前后端分离、权限控制
作者:故事爱人
www.cnblogs.com/WUXIAOCHANG
