京东java笔试
2.下面有关值类型和引用类型描述正确的是(A)?
A.值类型的变量赋值只是进行数据复制,创建一个同值的新对象,而引用类型变量赋值,仅仅是把对象的引用的指针赋值给变量,使它们共用一个内存地址。
B.值类型数据是在栈上分配内存空间,它的变量直接包含变量的实例,使用效率相对较高。而引用类型数据是分配在堆上,引用类型的变量通常包含一个指向实例的指针,变量通过指针来引用实例。
C.引用类型一般都具有继承性,但是值类型一般都是封装的,因此值类型不能作为其他任何类型的基类。
D.值类型变量的作用域主要是在栈上分配内存空间内,而引用类型变量作用域主要在分配的堆上。
解析:
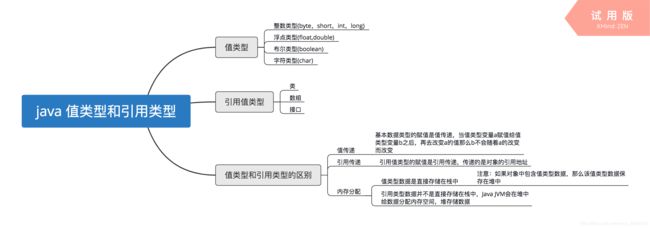
B错在,值类型变量不包含实例,实例是针对于对象的概念,当类实例化为对象的时候,这个时候可以称为是类的一个实例。同时,效率比较高这个概念比较模糊。
C错在,封装的概念也是针对类而言的,值类型数据不存在封装概念。
D错在,值类型变量可以作为成员变量存储在堆里,例如一个Class A中包含一个int value,那么value是作为成员变量存储在堆中的。D选项表述有漏洞。
3.如何在多线程中避免发生死锁?
A.允许进程同时访问某些资源。
B.允许进程强行从占有者那里夺取某些资源。
C.进程在运行前一次性地向系统申请它所需要的全部资源。
D.把资源事先分类编号,按号分配,使进程在申请,占用资源时不会形成环路。
解析:
死锁:在多道程序设计环境下,多个进程可能竞争一定数量的资源,。一个进程申请资源,如果资源不可用,那么进程进入等待状态。如果所申请的资源被其他等待进程占有,那么该等待的进程有可能无法改变状态,这种情况下称之为死锁。
死锁的四个条件:
1.互斥:至少有一个资源必须处在非共享模式,即一次只能有一个进程使用,如果另一进程申请该资源,那么申请进程必须延迟直到该资源释放为止。
2.占有并等待:一个进程必须占有至少一个资源,并等待另一个资源,而该资源为其他进程所占有。
3.非抢占:资源不能被抢占
4.循环等待:有一组进程{P0,P1,…Pn},P0等待的资源被P1占有,P1等待的资源被P2占有,Pn-1等待的资源被Pn占有,Pn等待的资源被P0占有。
形成死锁必须要满足这四个条件。那么违背这几个条件中的任何一个就不会形成死锁,这种方式成为 死锁预防,而死锁避免是动态的检测分配资源的状态是否安全
- 死锁解决方式
- 死锁预防
- 死锁避免
- 死锁检测并恢复
三者处理死锁的方式可以类比为:死锁预防,直接铲平坑;死锁避免,直接跳过坑;死锁检测并恢复,摔到坑里,修正一下继续前行。
对于互斥而言:有的资源本身就是互斥的,所以通常无法破坏这一必要条件。
对于占有并等待:破坏它,可以指定这样的规则(协议):每一个进程执行前一次性申请完所有资源。或者 每个进程申请当前所需要的资源,当需要使用其他资源时,需要把之前申请的资源释放掉。前者可以理解为破坏等待,后者可以理解为破坏占有。这样做使得资源得利用率很低(最后阶段可能需要用一下打印机,而将其在整个运行期占有);对于优先级低得进程来说,多次释放资源很容易造成它们饥饿。
对于非抢占:破坏它,即对于已经分配的资源可以进行抢占。当一个优先级比较低,那么它的资源往往会被优先级高得剥夺,导致它饥饿。
对于循环等待:对所有资源类型进排序,要求每个进程按照资源编号递增顺序申请资源。可以用反证法证明。简要描述一下,在进程按照资源编号递增顺序申请资源的条件下,假设一个循环等待存在,即有一组进程{P0,P1,…Pn},P0等待的资源被P1占有,P1等待的资源被P2占有,Pn-1等待的资源被Pn占有,Pn等待的资源被P0占有。那么Pi+1占有了Ri资源,同时又申请Ri+1,所以资源Ri的编号必然小于Ri+1,那么R0的编号小于R1的…Rn资源的编号小于R0资源的编号(Pn进程)。根据传递性,R0的编号小于R0的编号,显然矛盾,因此,在上述条件下,不会产生循环等待。
参考:《操作系统概念》
这题个人认为没有答案,A为产生死锁的一个原因,B为解除死锁的方法,CD为预防死锁的方法,C破坏‘请求与保持’条件,D破坏‘循环等待’条件。避免死锁的方法有银行家算法,但是选项中并没有。
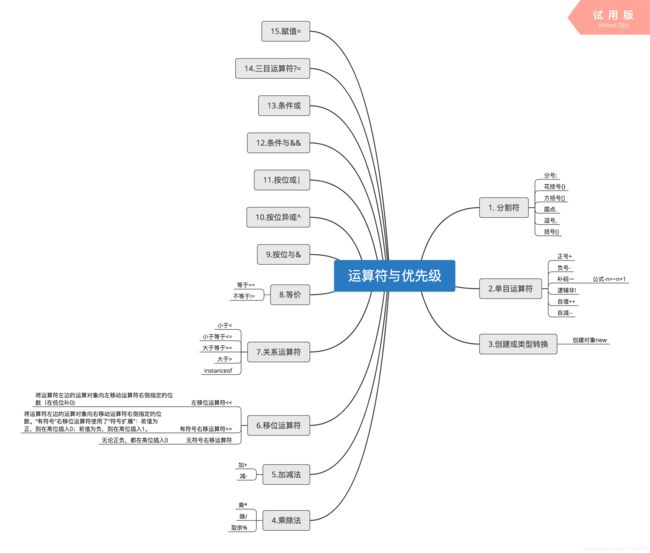
8.运算符与优先级
16.下列对TCP/IP结构及协议分层不正确的是:
A.网络接口层:Wi-Fi、ATM 、GPRS、EVDO、HSPA。
B.网际层:IP、ICMP、IGMP 。
C.传输层:TCP、UDP、TLS、ssh。
D.应用层:FTP、TELNET、DNS、SMTP.
解析:
SSH 为Secure Shell的缩写,由 IETF 的网络小组(Network Working Group)所制定;SSH 为建立在应用层基础上的安全协议。SSH 是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。
17. 以下哪种设备工作在数据链路层?
A.中继器
B.集线器
C.交换机
D.路由器
解析:
物理层:中继器、集线器
数据链路层:网桥、交换器
网络层:路由器
网络层以上:网关
21 、TCP协议的拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。常用的方法有:
解析
慢开始、拥塞避免、快重传、快恢复 。
22 、对于京东商城高流量访问,预防Ddos的方法可以有?(A)
A.限制同时打开SYN半链接的数目。
B.缩短SYN半链接的Time out 时间。
C.关闭不必要的服务。
D.限制客户端请求服务器时长。
解析:
DOS 是 denial of service(停止服务)的缩写,表示这种攻击的目的,就是使得服务中断。
当大量syn请求包发送给服务端的时候,需要设置合理的最大并发半开连接数。一旦超过相应的最大限制,系统就会认为自己收到了syn flood攻击,进入防范模式中。SYN Timeout时间被减短,SYN-ACK的重试次数减少,系统也会自动对缓冲区中的报文进行延时,避免对TCP/IP堆栈造成过大的冲击,力图将攻击危害减到最低。
31.以下哪条SQL语句可以返回table1中的全部的key:(D)
A、select tabel1.key from table1 join tabel2 on table1.key=table2.key
B、select tabel1.key from table1 right outer join tabel2 on table1.key=table2.key
C、select tabel1.key from table1 left semi join tabel2 on table1.key=table2.key
D、select tabel1.key from table1 left outer join tabel2 on table1.key=table2.key
解析:
由于需要返回table1中的全部的key,则需要左连接,而left semi join表示只打印出左边表中 的key,但前提是左表中的key在右表中存在,否则会过滤掉,所以选D
详细请看[link]https://www.cnblogs.com/fumj/archive/2012/09/12/2682039.html
32、MyISAM特性:
1:不支持事务、不具备AICD特性(原子性、一致性、分离性、永久性);
2:表级别锁定形式(更新数据时锁定整个表、这样虽然可以让锁定的实现成本很小但是同时大大降低了其并发的性能);
3:读写相互阻塞(不仅会在写入的时候阻塞读取、还会在读取的时候阻塞写入、但是读取不会阻塞读取);
4:只会缓存索引(myisam通过key_buffer_size来设置缓存索引,提高访问性能较少磁盘IO的压力、但是只缓存索引、不缓存数据);
5:读取速度快、占用资源比较少;
6:不支持外键约束、只支持全文检索;
7:是MySQL5.5.5版本之前的默认存储引擎;
33、Mysql中表user的建表语句如下,
CREATE TABLE user (
id bigint(20) NOT NULL AUTO_INCREMENT COMMENT ‘主键Id’,
name varchar(255) DEFAULT NULL COMMENT ‘名称’,
age int(11) DEFAULT NULL COMMENT ‘年龄’,
address varchar(255) DEFAULT NULL COMMENT ‘地址’,
created_time datetime DEFAULT NULL COMMENT ‘创建时间’,
updated_time datetime DEFAULT NULL COMMENT ‘更新时间’,
PRIMARY KEY (id),
KEY idx_com1 (name,age,address)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=‘用户表’;
以下哪个查询语句没有使用到索引idx_com1?(c)
A、select * from user where name=‘张三’ and age = 25 and address=‘北京大兴区’;
B、select * from user where name=‘张三’ and address=‘北京大兴区’;
C、select * from user where age = 25 and address=‘北京大兴区’;
D、select * from user where address=‘北京大兴区’ and age = 25 and name=‘张三’
解析
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候
b+数是按照从左到右的顺序来建立搜索树的,
比如当(张三,20,F)这样的数据来检索的时候,
b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;
但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点
节选于:https://www.cnblogs.com/big-handsome-guy/p/7755059.html
34、DELETE和TRUNCATE TABLE都是删除表中的数据的语句,它们的不同之处描述正确的是:
解析:
truncate table与delete都是删除表数据,保留表结构
truncate table 在功能上与不带 WHERE 子句的 delete语句相同:二者均删除表中的全部行。
不同:
truncate 比 delete(一行一行的删)速度快,且使用的系统和事务日志资源少。
truncate 操作后的表比Delete操作后的表要快得多。如果有ROLLBACK命令Delete将被撤销,而 truncate 则不会被撤销。
truncate当表被清空后表和表的索引重新设置成初始大小,而delete则不能。
如果删除表结构及其数据,用 drop table 语句。
执行速度,一般来说: drop> truncate > delete。
41、JAVA的类加载期负责整个生命周期内的class的初始化和加载工作,就虚拟机的规范来说,以下代码会输出什么结果?
public class Test {
public static void main(String[] args) {
System.out.println(Test2.a);
}
}
class Test2{
public static final String a=“JD”;
static {
System.out.print("OK");
}
}
答案:只有JD
解析:

使用static 和 final同时修饰的变量,在类没有初始化的时候就可以访问。
根据类加载器加载类的初始化原理,推断以下代码的输入结果为?
public class Test {
public static void main(String[] args) throws Exception{
ClassLoader classLoader=ClassLoader.getSystemClassLoader();
Class clazz=classLoader.loadClass("A");
System.out.print("Test");
clazz.forName("A");
}
}
class A{
static {
System.out.print(“A”);
}
}(A)
解析:
用ClassLoader加载类,是不会导致类的初始化(也就是说不会执行方法).Class.forName(…)加载类,不但会将类加载,还会执行会执行类的初始化方法.
50、线程池executor在空闲状态下的线程个数是?
public class Main { public static void main(String[] args) { ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 15, TimeUnit.SECONDS, new ArrayBlockingQueue
前三个参数:核心线程有5个,最大线程数是10个,keepAliveTime是15s,如果线程池中的线程大于5,那么超15s的空闲线程就会被结束,也就是说,一定会保持5个线程不会被结束。当所有任务完成后,会保持5个空闲的线程
57
$0
Shell本身的文件名
$!
Shell最后运行的后台Process的PID(后台运行的最后一个进程的进程ID号)
$?
最后运行的命令的结束代码(返回值)即执行上一个指令的返回值 (显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误)
$#
添加到Shell的参数个数